[논문 리뷰] SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
SPDF는 사전 학습 중 비구조적 가중치 희소성으로 FLOP를 줄인 뒤, 미세 조정에서 밀집화하여 용량을 회복하고 다운스트림 성능을 유지한다.
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also lead to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity, while retaining the benefits of pre-trained textual representations for downstream tasks.
연구 동기 및 목표
- 사전 학습 계산 비용을 다운스트림 정확도 손실 없이 줄이는 것을 동기부여한다.
- Sparse Pre-training and Dense Fine-tuning (SPDF)를 두 단계 학습 프레임워크로 제안한다.
- 사전 학습 시 희소성(최대 75%)이 성능을 미세 조정으로 회복되며 FLOPs를 줄일 수 있음을 보여준다.
- 희소성 수준이 작업 난이도, 데이터셋 크기, 모델 규모와 어떻게 관계하는지 조사한다.
- 사전 학습과 미세 조정 모델 간 매개변수 하위공간의 이동을 분석한다.
제안 방법
- dense GPT-like 모델에 사전 학습 전 uniform static unstructured sparsity를 적용한다.
- 희소 모델을 대규모 텍스트 코퍼스에서 사전 학습하여 고정된 희소성 마스크를 가진 masked autoregressive 목적함수를 최소화한다.
- 이전에 0으로 설정된 가중치를 모두 복원하고(초기화는 0) 다운스트림 작업에서 밀집하게 업데이트하여 dense한 미세 조정으로 전환한다.
- 자연어 생성 및 텍스트 요약 작업 전반에 걸쳐 평가하여 다운스트림 전이 성능을 평가한다.
- FLOPs를 측정하고 밀집 학습과 비교하여 효율성 향상을 정량화한다.
실험 결과
연구 질문
- RQ1사전 학습 중 높은 희소성(50-75%)이 dense한 미세 조정 후 다운스트림 성능을 유지할 수 있는가?
- RQ2SPDF의 희소성이 데이터셋 크기와 작업 난이도와 어떻게 상호작용하는가?
- RQ3더 큰 모델 크기(예: GPT-3 XL)가 다운스트림 저하를 덜 겪고 더 높은 희소성을 버티는가?
- RQ4모델 규모와 작업에 따라 SPDF로 달성 가능한 FLOP 감소는 어느 정도인가?
- RQ5SPDF 하에서 사전 학습과 미세 조정의 매개변수 하위공간은 어떻게 관계하는가?
주요 결과
| 모델 | 사전 학습 희소성 | E2E FLOPs (×10^18) | WebNLG FLOPs (×10^18) | DART FLOPs (×10^18) | Curation Corpus FLOPs (×10^18) |
|---|---|---|---|---|---|
| GPT-2 Small | 0% | 2.48 (1.00x) | 2.48 (1.00x) | 2.45 (1.00x) | 2.44 (1.00x) |
| GPT-2 Small | 50% | 1.84 (1.34x) | 1.82 (1.35x) | 1.84 (1.34x) | 1.81 (1.35x) |
| GPT-2 Small | 75% | 1.52 (1.64x) | 1.49 (1.65x) | 1.52 (1.64x) | 1.48 (1.65x) |
| GPT-3 XL | 0% | 236.62 (1.00x) | 236.62 (1.00x) | 236.33 (1.00x) | 236.32 (1.00x) |
| GPT-3 XL | 50% | 142.40 (1.66x) | 142.10 (1.66x) | 142.01 (1.66x) | 142.40 (1.66x) |
| GPT-3 XL | 75% | 95.29 (2.48x) | 94.98 (2.49x) | 95.29 (2.48x) | 94.90 (2.49x) |
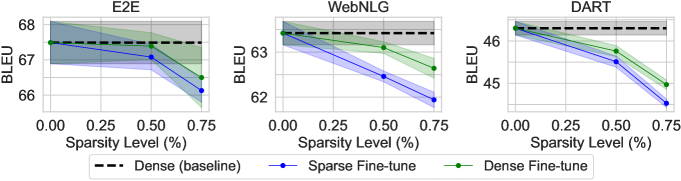
- 사전 학습에 GPT-2 Small 및 GPT-3 XL을 최대 75%의 희소성으로 학습시킨 결과, 여러 NLG 작업에서 BLEU/ perplexity의 감소가 미미하며 더 큰 모델이 희소성에 더 관대하게 반응한다.
- 희소한 사전 학습 후 밀집한 미세 조정은 희소한 미세 조정만 수행하는 경우보다 성능 손실을 완화한다.
- SPDF는 모델 크기에 따라 FLOP 감소를 크게 달성하며, 75% 희소성으로 사전 학습 시 GPT-2 Small은 약 1.65x, GPT-3 XL은 약 2.48x~2.49x의 총 FLOP 감소를 보인다.
- 다운스트림 작업 난이도는 희소성 허용도와 상관관계가 있으며, Curation Corpus(요약)은 E2E, WebNLG, DART보다 높은 희소성에 더 민감하다.
- 더 큰 모델은 사전 학습과 미세 조정 매개변수 하위공간 간 코사인 거리가 작아지며, 미세 조정 시 적응이 더 덜 필요함을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.