[논문 리뷰] Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Speech Robust Bench(SRB)을 소개합니다. SRB는 69개의 교란을 평가하고 모델을 비교하기 위한 지표를 제공하는 ASR용 포괄적 강인성 벤치마크입니다. 서브그룹 공정성 분석을 포함합니다.
As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 114 input perturbations which simulate an heterogeneous range of corruptions that ASR models may encounter when deployed in the wild. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as the use of discrete representations, or self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females. Our results revealed noticeable disparities in the model's robustness across subgroups. We believe that SRB will significantly facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
연구 동기 및 목표
- 실세계 손상에서 ASR 모델의 강인한 평가를 촉진한다.
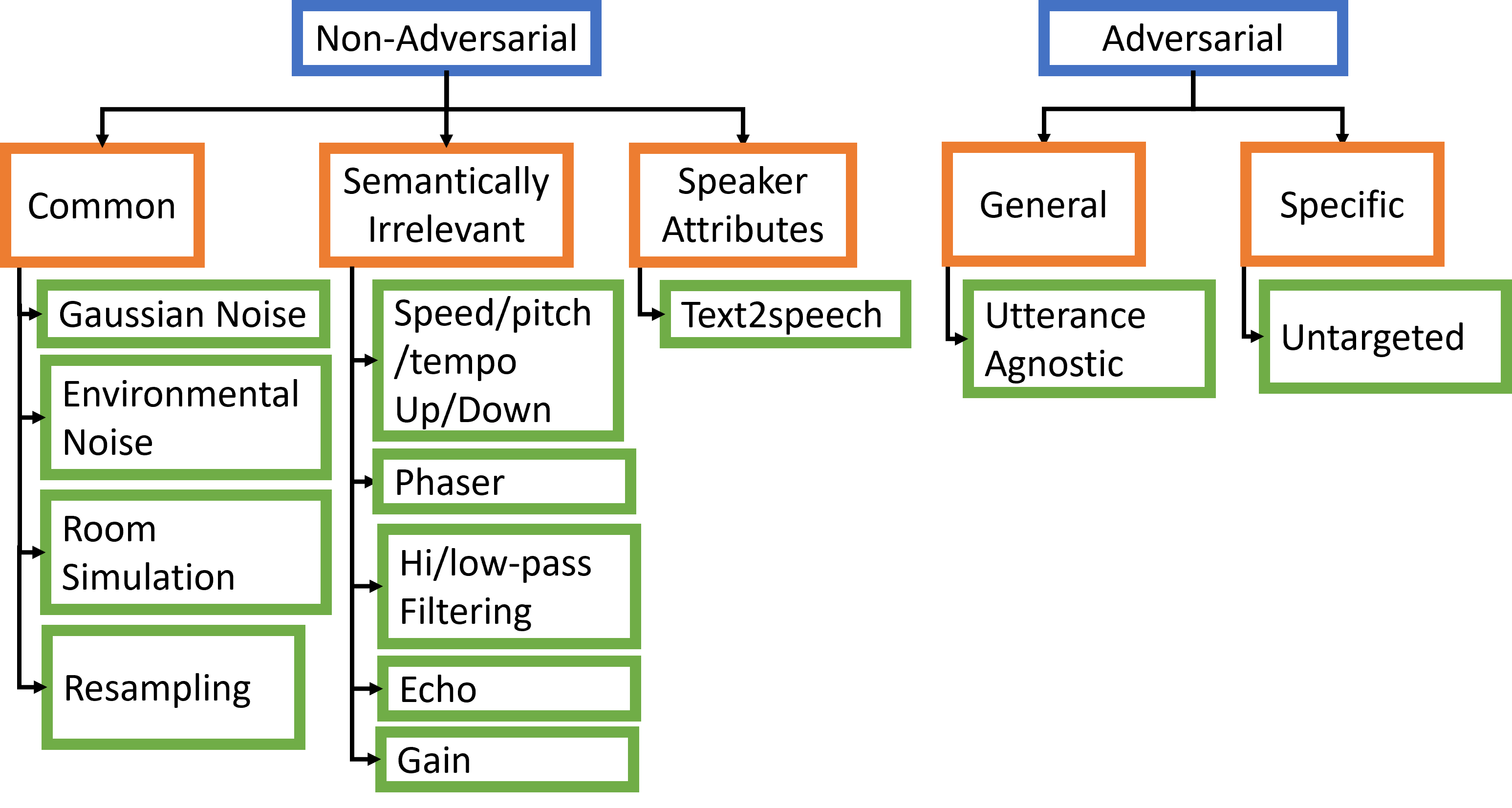
- 비대상적(distortions non-adversarial) 및 대적적(distortions adversarial) 왜곡을 포괄하는 포괄적 교란 은행을 정의한다.
- ASR 예측의 활용도와 안정성을 위한 지표(NWER 및 WERV)를 제안한다.
- 오픈 소스 도구와 데이터 세트로 표준화되고 확장 가능한 강인성 평가를 가능하게 한다.
제안 방법
- 환경적, 화자 관련, 의미적 및 대적적 왜곡을 네 가지 심각도에서 포괄하는 교란 은행을 구성한다.
- 대상 ASR 모델과 기준 모델로 교란된 음성을 기록하여 지표를 계산한다.
- 기존 WER로 대상 WER을 표준화하여 난이도를 고려하는 Normalize된 WER(NWER)을 계산한다.
- 다수의 교란 샘플에서 예측의 안정성을 측정하기 위해 WER 편차(WERV)를 계산한다.
- 주요 데이터 세트로 Librispeech를 사용하고 다국어 분석을 위해 스페인어 부분 데이터를 포함한다.
- 바로 사용할 수 있는 강인성 평가를 가능하게 하는 SRB 도구 및 교란 테스트 세트를 오픈 소스로 제공한다.

실험 결과
연구 질문
- RQ1현재의 ASR 모델이 현실 세계의 광범위한 교란(비대적 및 대적적)에 얼마나 강인한가?
- RQ2모델 크기, 아키텍처 및 학습 데이터가 교란 전반에 걸친 강인성에 어떤 영향을 미치는가?
- RQ3강인성 특성이 언어(영어 vs 스페인어) 및 성별과 같은 인구 하위 그룹마다 차이가 있는가?
- RQ4SRB가 하위 그룹 간의 강인성 차이에 대한 공정성 또는 편향의 격차를 밝힐 수 있는가?
주요 결과
| 언어 | 모델 | 데이터 (h) | #매개변수 (M) | WER |
|---|---|---|---|---|
| EN | wav2vec2-large-960h-lv60-self (w2v2-lg-slf) | 60,000 | 317 | 1.8 |
| EN | wav2vec2-large-robust-ft-libri-960h (w2v2-lg-rob) | 63,000 | 317 | 2.6 |
| EN | hubert-large-ls960-ft (hubt-lg) | 60,000 | 300 | 2.1 |
| EN | wav2vec2-base-960h (w2v2-bs) | 960 | 95 | 4.9 |
| EN | whisper-tiny.en (wsp-tn.en) | 680,000 | 39 | 6.4 |
| EN | deepspeech (ds) | 960 | 86 | 17.7 |
| ES | wav2vec2-large-xlsr-53-spanish (w2v2-lg-es) | 54,350 | 315 | 6.8 |
| ES | wav2vec2-base-10k-voxpopuli-ft-es (w2v2-bs-es) | 10,116 | 94 | 25.7 |
| Multi | whisper-large-v2 (wsp-lg) | 680,000 | 1,550 | 3.9/5.8 |
| Multi | whisper-tiny (wsp-tn) | 680,000 | 39 | 8.2/23.3 |
| Multi | mms-1b-fl102 (mms) | 55,000 | 964 | 15.4/15.7 |
- 더 큰 모델은 평균적으로 더 강인한 경향이 있지만, 특정 기법으로 학습된 작은 모델이 특정 교란에서 더 잘 수행할 수 있다.
- Whisper 대형 및 Wav2Vec2.0 대형 변형은 일반적으로 높은 강인성을 보이나, 일부 교란은 작은 모델에 유리하다(예: RIR, 재샘플링, 템포 감소).
- 대적적 교란은 모델 간 뚜렷한 강인성 프로필을 드러낸다; 어떤 모델은 발화 무관 공격에 더 잘 견디고, 다른 모델은 일반 공격에 더 효과적으로 견딘다.
- 스페인어(비영어) 강인성은 많은 모델에서 영어보다 뒤처지며 다국어 모델도 스페인 데이터에서 덜 강인한 경향이 있다.
- 성별 격차가 강인성에 존재하며, 여성 화자는 여러 모델에서 일반적으로 더 어려운 편이며 특정 교란 및 대적 공격에서 이 격차가 확대되는 경향이 있다.
- SRB는 상세한 공정성 분석을 가능하게 하며 강인성이 언어 및 인구통계학적 하위 그룹에 따라 달라지는 조건을 드러낸다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.