[논문 리뷰] Speech2Vec: A Sequence-to-Sequence Framework for Learning Word Embeddings from Speech
이 논문은 원시 음성에서 직접 어휘의 의미적 표현을 학습하는 RNN 기반의 시퀀스-투-시퀀스 프레임워크인 Speech2Vec을 제안한다. 이는 번역 과정을 생략한다. Word2Vec의 스킵그램 및 연속적 백터화 모델을 음성에 적응시켜, 텍스트에는 없는 억양 및 의미적 단서를 포착하며, 13개의 어휘 유사도 벤치마크에서 텍스트 기반 Word2Vec을 능가한다. 특히 50차원 임베딩에서 뛰어난 성능을 보인다.
In this paper, we propose a novel deep neural network architecture, Speech2Vec, for learning fixed-length vector representations of audio segments excised from a speech corpus, where the vectors contain semantic information pertaining to the underlying spoken words, and are close to other vectors in the embedding space if their corresponding underlying spoken words are semantically similar. The proposed model can be viewed as a speech version of Word2Vec. Its design is based on a RNN Encoder-Decoder framework, and borrows the methodology of skipgrams or continuous bag-of-words for training. Learning word embeddings directly from speech enables Speech2Vec to make use of the semantic information carried by speech that does not exist in plain text. The learned word embeddings are evaluated and analyzed on 13 widely used word similarity benchmarks, and outperform word embeddings learned by Word2Vec from the transcriptions.
연구 동기 및 목표
- 원시 음성에서 텍스트 번역에 의존하지 않고 의미적 어휘 임베딩을 학습하는 방법을 개발하는 것.
- 음성 인식(ASR) 기반 어휘 임베딩 파ip라인의 한계, 즉 번역 오류와 억양 정보 손실을 해결하는 것.
- Word2Vec의 성공을 음성으로 확장하기 위해 스킵그램 및 연속적 백터화 학습 목표를 음성 시퀀스에 적응시키는 것.
- 음성에서 유도된 임베딩이 텍스트 기반 대안보다 더 풍부한 의미 정보를 포착하는지 평가하는 것.
- 다양한 어휘 빈도 및 학습 설정에서 학습된 임베딩의 안정성과 변동성 분석하기
제안 방법
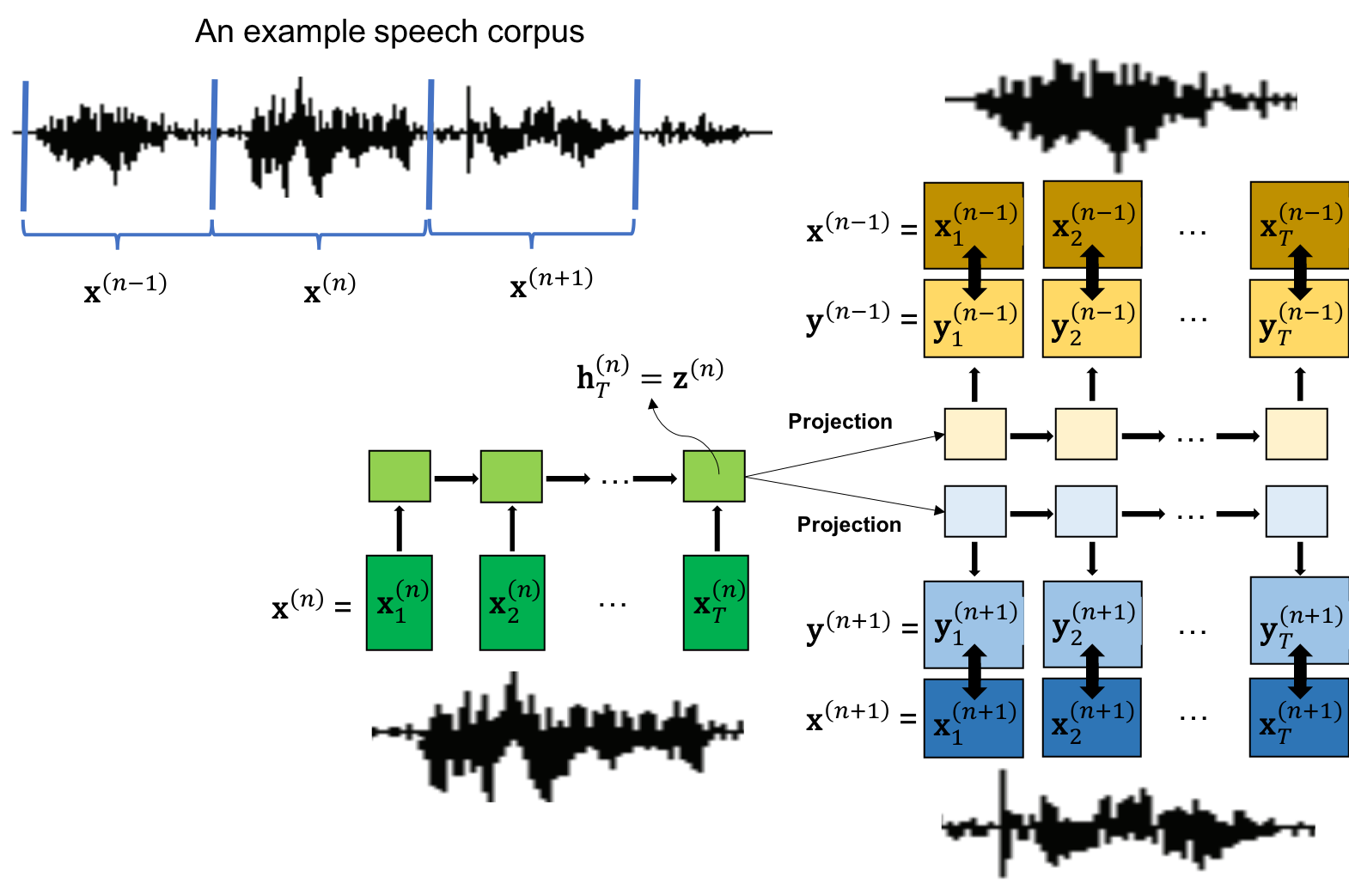
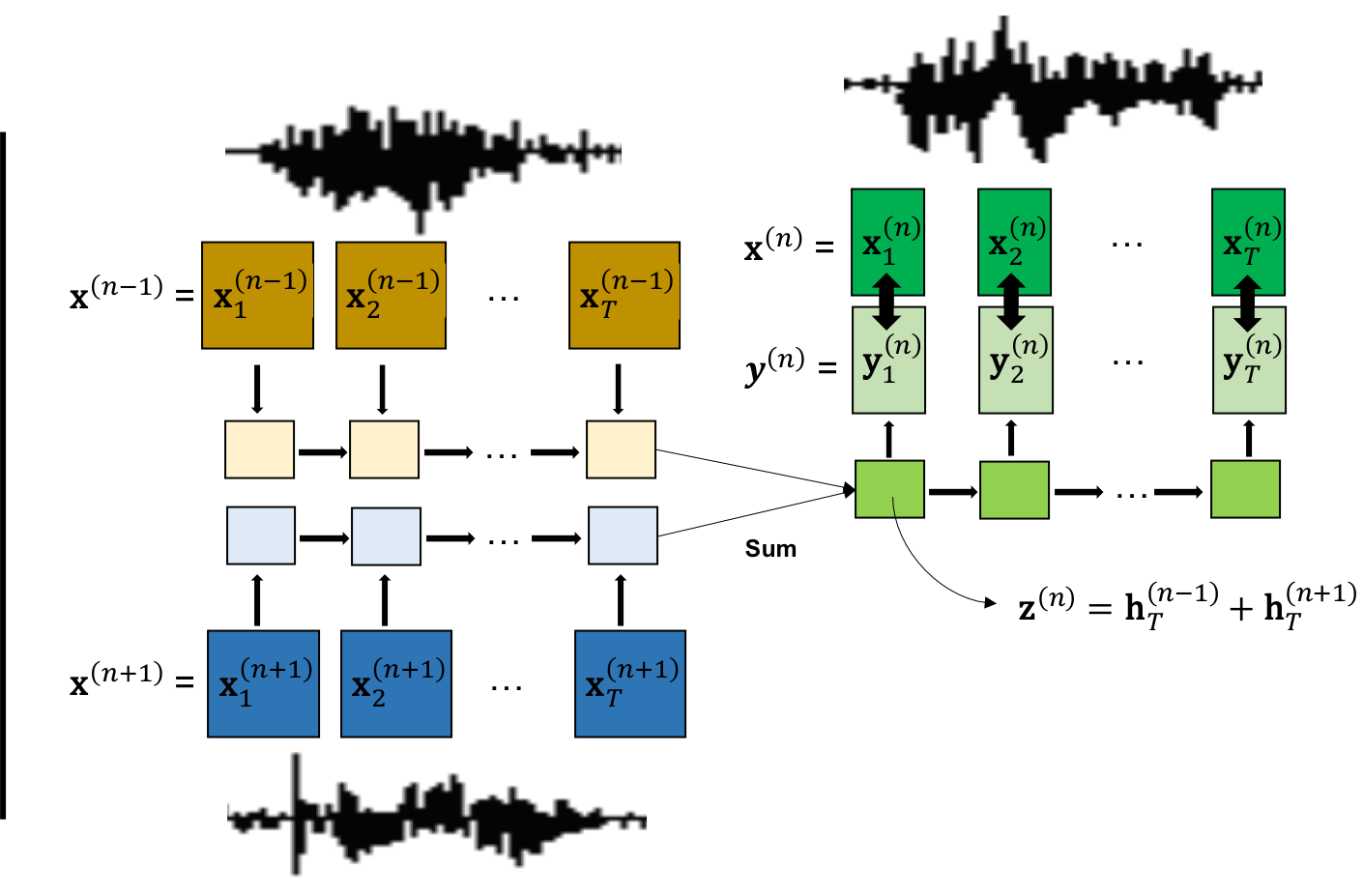
- Speech2Vec는 가변 길이의 음성 시퀀스(예: MFCC)를 고정 길이의 임베딩으로 매핑하기 위해 양방향 RNN 인코더-디코더 프레임워크를 사용한다.
- 모델은 스킵그램 또는 연속적 백터화(CBOW) 목표 함수를 사용해 훈련되며, 타겟 단어 세그먼트의 임베딩에서 그 주변 맥락 세그먼트를 예측한다.
- 스킵그램의 경우, 인코더가 타겟 단어 세그먼트를 처리하고 디코더가 주변 맥락 세그먼트를 예측한다. CBOW의 경우, 인코더가 여러 맥락 세그먼트를 인코딩하여 타겟을 예측한다.
- 음성 세그먼트는 고정 길이로 패딩되며, 강제 정렬(forced alignment)을 사용해 단어 수준의 경계를 확보함으로써 감독 기반 분할을 가능하게 한다.
- 모델은 교차 엔트로피 손실을 사용해 엔드 투 엔드로 훈련되며, 정확한 맥락 세그먼트를 예측할 확률을 최대화한다.
- 어휘 임베딩는 인코더의 최종 은닉 상태에서 유도되며, 어휘 유사도 벤치마크를 통해 평가된다.
실험 결과
연구 질문
- RQ1시퀀스-투-시퀀스 RNN 프레임워크는 텍스트 번역 없이도 원시 음성에서 의미 있는 의미적 어휘 임베딩을 학습할 수 있는가?
- RQ2억양 정보를 포함한 음성에서 학습하는 것이, 번역된 텍스트에서 학습하는 것보다 더 나은 의미 표현을 제공하는가?
- RQ3Speech2Vec의 스킵그램 및 CBOW 변종은 다양한 어휘 빈도 수준에서 성능 및 안정성 측면에서 어떻게 비교되는가?
- RQ4어휘 임베딩의 분산은 훈련 코퍼스 내 단어의 출현 빈도에 따라 어떻게 변화하는가?
- RQ5학습된 임베딩가 동의어 및 반의어와 같은 의미 관계를 얼마나 잘 포착하는가?
주요 결과
- 스킵그램 Speech2Vec는 13개의 어휘 유사도 벤치마크 중 8개에서 CBOW Speech2Vec 및 텍스트 기반 Word2Vec을 모두 능가하여, 음성에서 더 나은 의미 표현 학습 능력을 입증한다.
- 50차원 임베딩을 사용한 Speech2Vec가 대부분의 벤치마크에서 최고 성능을 기록하여, 원시 음성에서 학습할 경우 더 작은 임베딩 크기로도 충분함을 시사한다.
- Speech2Vec의 성능은 더 큰 훈련 코퍼스를 사용할수록 크게 향상되며, 훈련 데이터를 10%에서 전체 데이터로 늘일 경우 뚜렷한 성능 향상이 관찰된다.
- 스킵그램 Speech2Vec는 어휘 빈도가 높아질수록 어휘 임베딩의 분산이 낮아져 고빈도어의 안정성과 강건성을 보여준다.
- t-SNE 시각화 결과는 학습된 임베딩이 의미적 구조를 잘 포착하고 있음을 확인하며, 반의어(긍정/부정 어휘)는 공간적으로 분리되어 있고, 동의어들은 그룹화되어 있다.
- 모델이 음성의 억양 및 맥락적 단서를 포착할 수 있어, 번역 텍스트를 입력으로 사용하는 텍스트 기반 Word2Vec보다 더 나은 의미 일반화 능력을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.