[논문 리뷰] SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
본 논문은 SpeechTokenizer를 소개하는 통합 RVQ 기반 음성 토크나이저로, 의미 토큰과 음향 토큰을 의미적 증류를 통해 결합하고, Unified Speech Language Model (USLM)을 구축하며, 재구성 성능, SLMTokBench 성능 및 기준선 대비 제로샷 TTS 이점을 보여준다.
Current speech large language models build upon discrete speech representations, which can be categorized into semantic tokens and acoustic tokens. However, existing speech tokens are not specifically designed for speech language modeling. To assess the suitability of speech tokens for building speech language models, we established the first benchmark, SLMTokBench. Our results indicate that neither semantic nor acoustic tokens are ideal for this purpose. Therefore, we propose SpeechTokenizer, a unified speech tokenizer for speech large language models. SpeechTokenizer adopts the Encoder-Decoder architecture with residual vector quantization (RVQ). Unifying semantic and acoustic tokens, SpeechTokenizer disentangles different aspects of speech information hierarchically across different RVQ layers. Furthermore, We construct a Unified Speech Language Model (USLM) leveraging SpeechTokenizer. Experiments show that SpeechTokenizer performs comparably to EnCodec in speech reconstruction and demonstrates strong performance on the SLMTokBench benchmark. Also, USLM outperforms VALL-E in zero-shot Text-to-Speech tasks. Code and models are available at https://github.com/ZhangXInFD/SpeechTokenizer/.
연구 동기 및 목표
- 전체 음성 정보를 보존하면서 텍스트와 정렬되는 이산 음성 표현의 필요성을 제시한다.
- 기존의 의미 토큰과 음향 토큰 유형을 평가하고 음성 언어 모델링에서의 한계를 식별한다.
- RVQ 계층 전반에 걸쳐 콘텐츠와 패럴링구스틱 정보(paralinguistic information)를 분리하는 통합 토크나이저(SpeechTokenizer)를 제안한다.
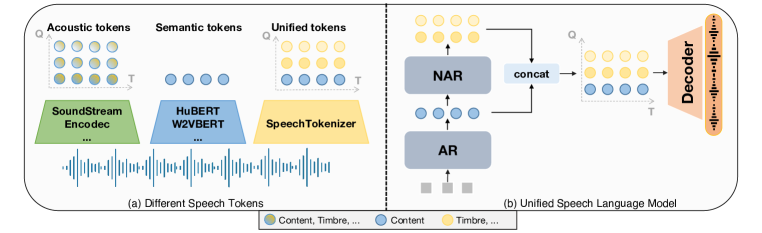
- SpeechTokenizer를 활용하여 자동회귀(AR) 및 비자기회귀(NAR) 생성을 가능하게 하는 Unified Speech Language Model(USLM)을 개발한다.
- 경쟁력 있는 음성 재구성, 강력한 SLMTokBench 성능, 그리고 기준선 대비 향상된 제로샷 TTS를 입증한다.
제안 방법
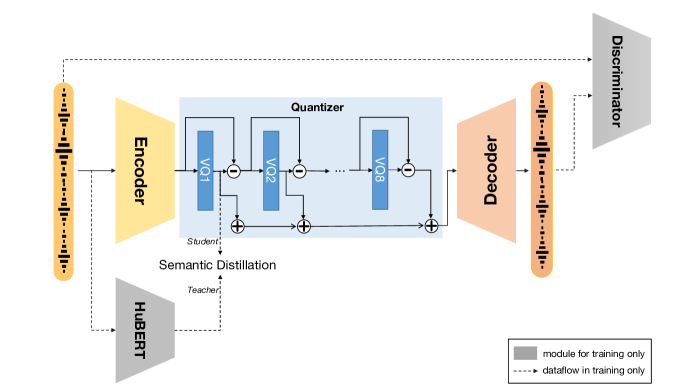
- EnCodec와 유사한 시간적 다운샘플링을 갖는 Encoder-Decoder RVQ-GAN 프레임워크를 사용한다.
- 연속적 및 의사 레이블 증류를 통해 첫 번째 RVQ 계층이 의미적 교사(HuBERT)에 의해 안내되도록 의미 증류를 도입한다.
- 재구성 GAN 목적과 RVQ 약정(RVQ commitment) 손실 및 의미 증류 손실을 함께 사용하여 학습한다.
- RVQ 계층 전반에 걸쳐 정보를 계층적으로 분리하여, 첫 번째 계층은 콘텐츠를 포착하고 이후 계층은 패럴링구스틱 디테일을 인코딩하도록 한다.
- 첫 번째 계층 토큰에서 AR, 이후 계층에서 NAR를 사용하는 Unified Speech Language Model(USLM)을 구성하고 제로샷 TTS를 위해 훈련한다.
- SLMTokBench를 통해 텍스트 정렬 및 정보 보존을 평가하고 제로샷 TTS 및 원샷 보이스 컨버전에 대해 평가한다.
실험 결과
연구 질문
- RQ1통합 SpeechTokenizer가 의미 토큰이나 음향 토큰만 사용하는 경우보다 텍스트 정렬과 음성 정보 보존을 모두 향상시킬 수 있는가?
- RQ2의미 지도가 있는 계층적 RVQ 토큰화가 효과적인 콘텐츠 모델링과 고품질 음성 재구성을 가능하게 하는가?
- RQ3결과물인 USLM이 제로샷 TTS에서 기존 시스템을 능가하고 콘텐츠 정확도를 유지하거나 향상시키는가?
- RQ4의미 교사 선택(HuBERT L9 대 평균 또는 유닛 등)이 이후의 텍스트 정렬 및 재구성에 어떤 영향을 주는가?
- RQ5원샷 보이스 컨버전에 대한 작업에서 RVQ 계층 간 정보 분리가 어떤 역할을 하는가?
주요 결과
- SpeechTokenizer는 EnCodec와 유사한 음성 재구성을 달성하고 더 낮은 WER를 낼 수 있어 콘텐츠 보존이 강하다는 것을 시사한다.
- SLMTokBench에서 SpeechTokenizer 토큰은 텍스트 상호 정보가 향상되고 기준선과 비교하여 콘텐츠 보존이 경쟁력 있거나 더 우수하며, 후반 RVQ 계층이 음색 유지에 기여한다.
- 제로샷 TTS에서 SpeechTokenizer를 사용하는 Unified Speech Language Model은 VALL-E보다 더 낮은 WER와 더 높은 화자 유사도를 달성한다.
- USLM은 제로샷 TTS에서 더 우수한 화자 유사도와 경쟁력 있는 MOS/SMOS 점수를 보여주어 콘텐츠와 화자 정보를 효과적으로 분리함을 시사한다.
- 원샷 보이스 컨버전 실험은 후반 RVQ 계층의 정보가 화자 특성을 인코딩하여 제어 가능한 VC 성능을 가능하게 함을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.