[논문 리뷰] Stable LM 2 1.6B Technical Report
Stable LM 2 1.6B는 1.6B 매개변수를 가진 오픈 디코더 전용 언어 모델로, 투명한 다국어 데이터 혼합으로 학습되었으며 양자화 및 엣지 디바이스 처리량 기능과 함께 공개되었고, 미세 조정 및 평가 결과를 제공합니다.
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
연구 동기 및 목표
- Stable LM 2 1.6B를 구축하는 데 사용된 데이터 수집 및 학습 절차를 설명한다.
- 사전 학습 아키텍처, 토크나이저 및 최적화 구성에 대해 설명한다.
- 대화 능력을 향상시키기 위해 사용된 미세 조정, 정렬 및 자기 지식 기술을 자세히 설명한다.
- Few-shot, 다국어, 다회 대화 벤치마크에 걸친 종합 평가를 제시한다.
- 추론, 양자화 옵션, 엣지 디바이스 처리량, 환경 영향에 대한 정보를 제공한다.
제안 방법
- FlashAttention-2와 혼합 정밀도를 사용하여 4096 토큰 컨텍스트를 갖는 1.6B 디코더 전용 Transformer를 학습한다.
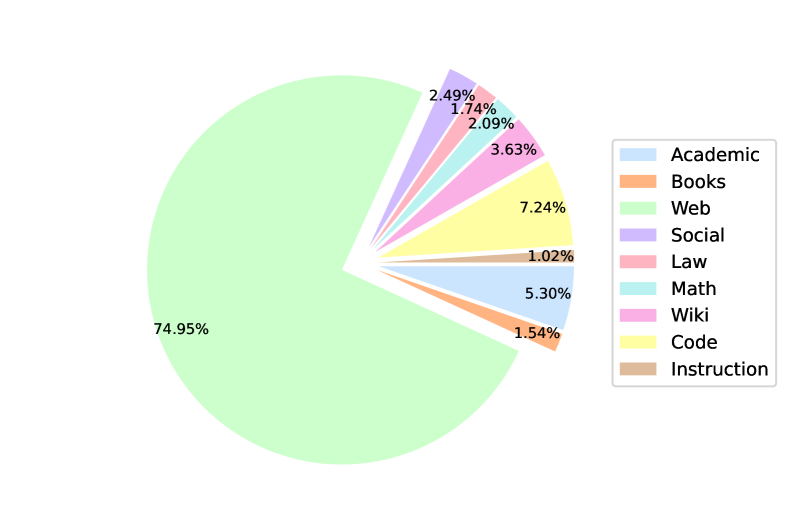
- 도메인 및 언어에 대한 명시적 샘플링 가중치를 사용하는 약 2조 토큰의 다국어 데이터 혼합을 사용한다(표 1).
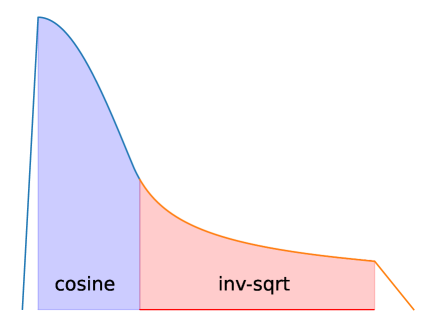
- 워밍업, 코사인 및 rsqrt 감소, 그다음 선형 쿨다운이 포함된 다단계 학습률 스케줄을 적용한다.
- Hugging Face Hub의 지시어 데이터셋에서 감독 미세 조정을 수행한 다음 Direct Preference Optimization과 자기 지식 학습 루프를 수행한다.
- 다양한 추론 프레임워크용으로 Q4_0, Q4_1, Q5_K_M GGUF 및 INT4 형식의 양자화 체크포인트를 제공하고 공개한다.
실험 결과
연구 질문
- RQ1동일 규모의 공개 모델과 비교했을 때 Stable LM 2 1.6B가 표준 few-shot 및 zero-shot 벤치마크에서 어떤 성능을 보이나요?
- RQ2비영어 및 다국어 벤치마크에 대한 다국어 사전 학습 데이터의 영향은 무엇인가요?
- RQ3SFT, DPO 및 자기지식 학습이 대화 품질 및 정렬에 어떤 영향을 미치나요?
- RQ4엣지 배포를 위한 엣지 디바이스 처리량 및 양자화의 trade-off는 무엇인가요?
- RQ5오픈-웨이트 모델 공개의 환경 영향 및 사회적 고려사항은 무엇인가요?
주요 결과
- Stable LM 2 1.6B는 여러 영어 벤치마크에서 유사 규모의 다른 기본 모델보다 우수하고, 대화 상황에서 MT-Bench에서 더 큰 모델에 근접합니다.
- 모델은 비영어 평가 설정에서 독일어, 스페인어, 프랑스어, 이탈리아어, 포르투갈어, 네덜란드어에 걸쳐 강력한 다국어 역량을 보여줍니다.
- 지시 응답 튜닝된 변형(stablelm-2-1_6b-dpo)은 Phi-1.5보다 개선되며 여러 지표에서 Phi-2와 우호적으로 비교됩니다.
- 양자화 체크포인트(Q4_0, Q4_1, Q5_K_M GGUF, INT4)가 제공되어 엣지 디바이스 또는 프레이워크별 배포를 효율화합니다.
- 처리량 측정은 엣지 디바이스에서 하위 정밀도를 사용할 때 상당한 이점을 보여주며, 다양한 프레임워크의 설명 그림이 제공됩니다.
- 학습에 약 92,000 GPU-시간이 필요했고 추정 탄소 발자국은 11 tCO2eq입니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.