[논문 리뷰] Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
본 논문은 Stable Video Diffusion (SVD)를 제시합니다. 이는 큐레이션된 대규모 동영상 데이터셋을 대상으로 세 단계의 데이터 전략으로 학습된 잠재 동영상 확산 모델로, 최첨단 텍스트-투-비디오(text-to-video) 및 이미지-투-비디오(image-to-video) 합성을 달성하며, 강력한 모션 및 다중 시점(prior) 사전을 제공합니다.
We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .
연구 동기 및 목표
- 대규모 비디오 확산 사전학습을 위한 효과적인 데이터 큐레이션 전략을 식별한다.
- 비디오 LDM을 위한 세 단계 학습 체계(이미지 사전학습, 비디오 사전학습, 고품질 미세조정)를 제안하고 검증한다.
- 큐레이션된 사전학습이 강력한 모션 표현을 얻고 텍스트-투-비디오, 이미지-투-비디오, 다중 시점 생성 등 다운스트림 작업에 이익을 준다는 것을 입증한다.
- 기저 모델이 강력한 모션 프라이어로 작용하며 카메라 모션에 대한 LoRA 등 효율적인 파인튜닝으로 다양한 작업에 적합하다는 것을 보인다.
제안 방법
- 사전에 학습된 이미지 확산 백본에 시간적 계층을 삽입한 잠재 동영상 확산 모델을 사용한다.
- 컷 탐지, 합성 자막, 광학 흐름 필터링, OCR, CLIP 기반 미학 및 유사도 지표를 포함하는 체계적인 데이터 큐레이션 워크플로를 개발한다.
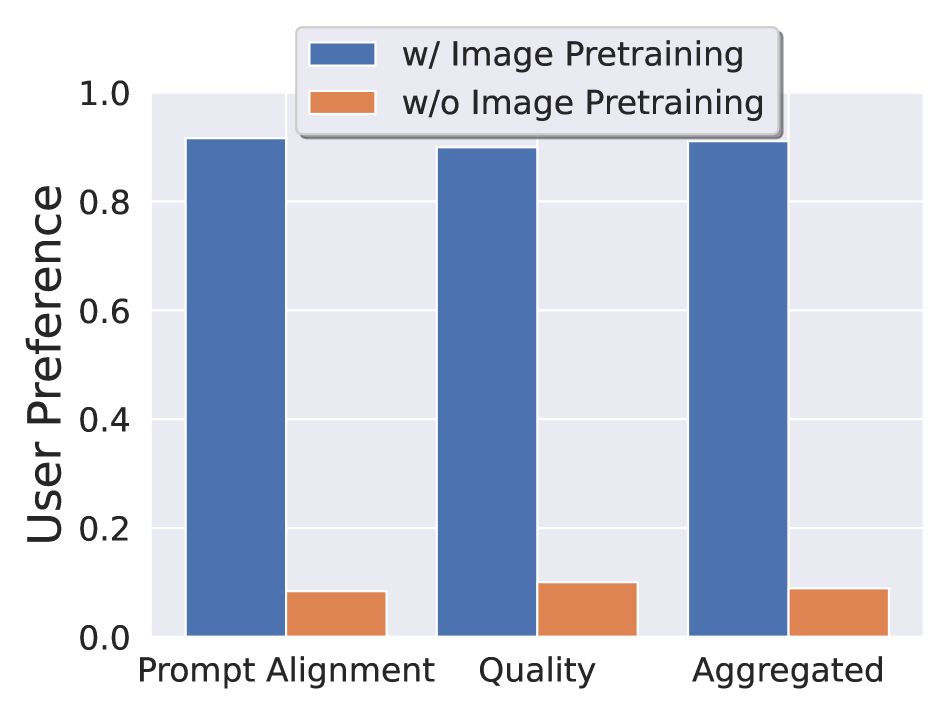
- 세 단계로 학습: (i) 2D 확산 모델에서의 이미지 사전학습, (ii) 저해상도에서의 대규모 비디오 사전학습, (iii) 더 작은 데이터셋에서 고해상도로의 고품질 미세조정.
- EDM 잡음 스케줄을 더 높은 잡음 값 쪽으로 이동시켜 고해상도 미세조정을 개선한다.
- 프레임 속도에 대한 마이크로 컨디셔닝과 카메라 모션용 LoRA 모듈을 통해 모션 제어를 가능하게 한다.
- 학습한 모션 프라이어를 활용하여 다중 시점 데이터세트에서 미세조정으로 일관된 다중 시점 출력을 생성하는 다중 뷰 생성(Multi-view generation)을 시연한다.
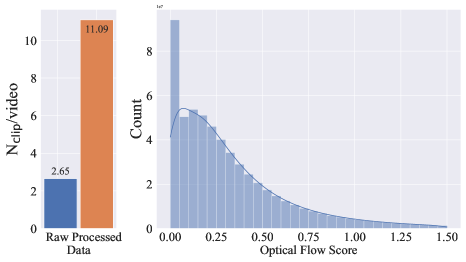
실험 결과
연구 질문
- RQ1대규모 비디오 말뭉치에 대한 신중한 데이터 큐레이션이 미세조정 후 최종 비디오 모델의 성능을 향상시키는가?
- RQ2세 단계 학습 체계가 고품질 텍스트-투-비디오 및 이미지-투-비디오 합성에 미치는 영향은 무엇인가?
- RQ3기저 비디오 모델이 강력한 모션 표현과 다운스트림 작업에 usable한 3D/다중 뷰 프라이어를 제공할 수 있는가?
- RQ4큐레이션된 데이터로 사전학습된 비디오 확산 모델이 품질과 효율성 측면에서 최첨단 다중 뷰/합성 방법과 어떻게 비교되는가?
주요 결과
- 잘 큐레이션된 비디오 데이터로의 사전학습은 고품질 미세조정 후에도 지속되는 상당한 성능 향상을 가져온다.
- 큐레이션된 데이터로 사전학습된 기본 모델은 제로샷 텍스트-투-비디오 성능이 강하며 UCF-101에서 여러 베이스라인을 능가한다.
- 고품질 데이터로의 미세조정은 폐쇄 소스 모델과 대등한 해상도의 텍스트-투-비디오 및 이미지-투-비디오 결과를 제공한다.
- 기저 모델은 강력한 모션 표현을 제공하고 다운스트림 다중 뷰 생성에 강력한 프라이어 역할을 하며 다중 뷰 작업에서 Zero123XL 및 SyncDreamer와 같은 방법을 능가한다.
- LoRA 모듈을 사용하면 이미지-투-비디오 생성에서 명시적 카메라 모션 제어가 가능하다.
- 세 단계 학습 전략은 대규모 데이터셋(약 600M 샘플)에도 효과적으로 확장되며 제한된 컴퓨팅으로도 효율적인 다중 뷰 파인튜닝을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.