[논문 리뷰] STaR-GATE: Teaching Language Models to Ask Clarifying Questions
STaR-GATE는 언어 모델이 사용자 선호를 이끌어내기 위한 더 나은 명확화 질문을 하도록 미세조정한다; 두 차례의 반복 후 초기 모델에 대한 비교에서 응답이 72% 승리한다.
When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
연구 동기 및 목표
- 사용자-LM 상호 작용에서 작업 모호성의 동기부여와 정의 및 선호 파악의 필요성.
- 질문 제시를 통한 정보 수집과 자기 플레이 루프를 결합한 반복적 자기 개선 프레임워크로 STaR-GATE를 소개한다.
- 훈련 가이드를 위한 페르소나-작업 프롬프트 및 골 응답의 합성 데이터셋 생성.
- 강청 취득된 질문과 자체 생성 응답에 대한 미세조정이 다운스트림 응답 품질을 향상시킨다는 것을 입증
제안 방법
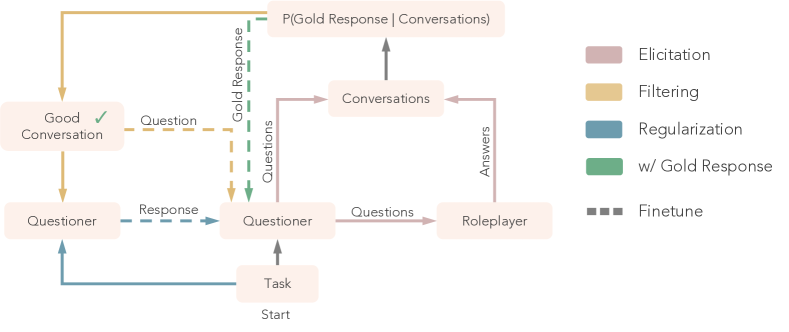
- Oracle을 이용해 페르소나에 접근하는 골 응답과 함께 25,500개의 페르소나-작업 프롬프트의 합성 데이터셋을 생성.
- 타깃 질문을 통해 사용자 선호를 이끌어내는 질문자–롤플레이어 대화를 시뮬레이션.
- Questioner의 프롬프트와 Roleplayer의 선호도에서 골 응답의 로그 확률을 기반으로 보상을 정의.
- 가장 좋은 대화와 해당 모델 응답에 대해 Questioner를 파인튜닝(전문가 반복 스타일).
- 훈련 중 이전 반복의 응답을 포함시켜 분포 shifting을 방지하는 정규화.

실험 결과
연구 질문
- RQ1사용자 선호가 알려지지 않은 경우 정보 이론적 질문을 학습해 작업 성능을 향상시킬 수 있을까?
- RQ2질문을 통한 반복적 자기 개선이 골 응답 가능성과 실제 작업 성능을 향상시키는가?
- RQ3자가 생성 응답 포함 및 정규화가 학습 안정성 및 출력의 현실성에 어떤 영향을 미치는가?
- RQ4훈련 페르소나를 넘어서는 다른 롤플레이어에 일반화되는가?
- RQ5정규화의 필요성과 응답 대 질문 훈련의 필요성에 대한 차별화 실험은?
주요 결과
- 질문 중심의 미세조정이 반복에 걸쳐 골 응답의 로그 확률을 증가시킨다.
- STaR-GATE는 두 차례의 반복 후 초기 모델에 대해 72% 승률을 달성한다.
- 훈련 페르소나를 넘어 확장 가능하다는 부분적인 내성이 입증되었다.
- 자기 생성 응답으로의 정규화는 잊히지 않도록 하고 환각을 방지하는 데 중요하다.
- 차별화에서 질문만으로의 훈련은 성능을 저하시키고 골 응답으로의 훈련은 비현실적인 출력을 초래할 수 있다.
- 응답-정규화된 STaR-GATE는 질문이나 골 응답 중 하나만으로 훈련된 버전보다 더 나은 성능을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.