[논문 리뷰] StarCoder: may the source be with you!
StarCoderBase와 StarCoder는 8K 컨텍스트를 가진 오픈 액세스 15.5B Code LLM으로 The Stack에서 학습했으며, 오픈 모델에서 강력한 성능을 보이고 OpenAI의 code-cushman-001과 일치하거나 이를 능가하고, 오픈 릴리스용 안전성 및 출처 도구를 제공합니다.
The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
연구 동기 및 목표
- 광범위한 언어 지원을 갖춘 오픈 액세스 코드 LLM(StarCoderBase와 StarCoder)을 개발한다.
- The Stack에서 허용적으로 라이선스된 데이터로 학습하고 데이터를 신중하게 선별한다.
- 오픈 및 클로즈드 코드 LLM에 대해 포괄적인 평가를 수행하고 안전성 도구를 평가한다.
- 저작 출처 추적, 향상된 PII 비식별/삭제, 그리고 접근 가능한 라이선스를 통해 책임 있는 배포를 가능하게 한다.
- 문서화와 함께 상업적으로 실행 가능한 오픈 라이선스하에 모델의 공개 출시를 제공한다.
제안 방법
- 우리는 8K 토큰 컨텍스트를 가진 15.5B 매개변수 모델과 Fill-in-the-Middle 인필링을 사용한다.
- StarCoderBase는 The Stack의 1조 토큰을 사용해 80개국 이상 언어, GitHub 이슈, 커밋, 노트북에서 학습된다.
- StarCoder는 추가로 35B Python 토큰에서 미세 조정된 변형이다.
- Multi-Query-Attention을 통해 빠른 대형 배치 추론을 구현한다.
- 데이터 큐레이션 필터에는 언어 선택, XML/HTML/JSON/YAML 처리, Jupyter 노트북 처리 등이 포함된다.
- 코드 데이터에 중복 제거 파이프라인(MinHashes 및 LSH)을 적용하고 커밋에 대해서는 데이터 양을 샘플링한다.
- PII 비식별은 전용 데이터 세트와 StarEncoder 모델을 활용해 강화하며, 출처 도 tracing을 위한 도구를 VSCode 데모에 통합한다.
실험 결과
연구 질문
- RQ1StarCoderBase와 StarCoder가 다국어 지원에서 오픈 코드 LLM과 어떻게 비교되는가?
- RQ2StarCoderBase와 StarCoder가 평가 벤치마크에서 OpenAI code-cushman-001과 일치하거나 이를 능가하는가?
- RQ3Python에서의 미세 조정이 StarCoder에게 다른 Python 튜닝 모델들보다 우위를 주면서도 언어 간 성능을 유지하는가?
- RQ4오픈 액세스 릴리스를 Attribution 도구와 개선된 PII 비식별로 안전하고 투명하게 만들 수 있는가?
주요 결과
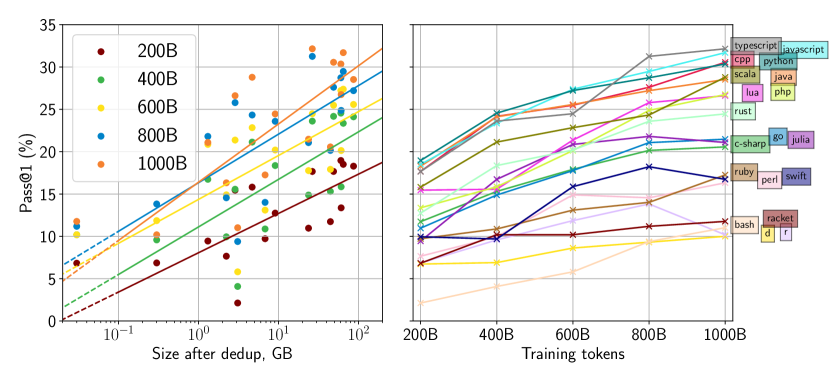
- StarCoderBase는 여러 프로그래밍 언어를 지원하는 모든 오픈 LLM보다 성능이 앞선다.
- StarCoderBase는 OpenAI code-cushman-001 모델과 일치하거나 이를 능가한다.
- Python에서 미세 조정되었을 때 StarCoder는 기존의 Python 튜닝 LLM들보다 상당히 우수하다.
- StarCoder는 Python에서 미세 조정된 모든 모델보다 우수한 성능을 유지하면서 다른 언어에서도 성능을 유지한다.
- 릴리스에는 OpenRAIL-M 라이선스, 출처 추적 도구, 학습 데이터 추적을 위한 훈련된 StarEncoder를 활용한 개선된 PII 비식별 파이프라인이 포함된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.