[논문 리뷰] Statler: State-Maintaining Language Models for Embodied Reasoning
Statler는 쌍으로 이루어진 세계 상태 읽기-쓰기 LLM이 명시적으로 추정된 세계 상태를 유지하고 업데이트하여 구현된 로봇 계획을 안내하는 프레임워크를 도입하며, 시뮬레이션과 실제 로봇에서 장기적 시야의 작업에 대해 Code-as-Policies에 비해 강력한 이득을 달성한다.
There has been a significant research interest in employing large language models to empower intelligent robots with complex reasoning. Existing work focuses on harnessing their abilities to reason about the histories of their actions and observations. In this paper, we explore a new dimension in which large language models may benefit robotics planning. In particular, we propose Statler, a framework in which large language models are prompted to maintain an estimate of the world state, which are often unobservable, and track its transition as new actions are taken. Our framework then conditions each action on the estimate of the current world state. Despite being conceptually simple, our Statler framework significantly outperforms strong competing methods (e.g., Code-as-Policies) on several robot planning tasks. Additionally, it has the potential advantage of scaling up to more challenging long-horizon planning tasks.
연구 동기 및 목표
- LLMs로 명시적으로 세계 상태를 유지함으로써 장기간의 로봇 계획을 동기 부여하고 가능하게 한다.
- 현재 상태에 따라 행동을 조건화하기 위해 세계 상태 읽기/쓰기 모듈을 사용하는 모델 기반 접근법을 개발한다.
- 시뮬레이션된 탁상 도메인과 실제 로봇에 걸친 세계 상태 유지의 강인성과 확장성을 입증한다.
제안 방법
- 질의와 현재 상태를 기반으로 실행 가능한 행동을 생성하는 세계 상태 읽기 모듈과, 행동 실행 후 상태를 업데이트하는 세계 상태 쓰기 모듈의 두 가지 특화된 LLM에 프롬트한다.
- 잠재적 동역학을 추적하기 위해 단계 간에 읽고 업데이트되는 외부의 JSON 형식의 세계 상태 표현을 유지한다.
- 데모를 사용하여 읽기/쓰기 프롬트를 학습시키거나 조정한다; 선택적으로 통합형 대 분리형 읽기/쓰기 구성을 비교한다.
- 여러 탁상 조작 과제에서 Code-as-Policies(CaP) 및 Chain-of-Thought 프롬프트를 가진 CaP를 통해 Statler를 평가한다.
- 별도의 읽기/쓰기 구성 요소 및 다양한 상태 유지 전략의 기여를 보여주는 제거 실험을 제시한다.
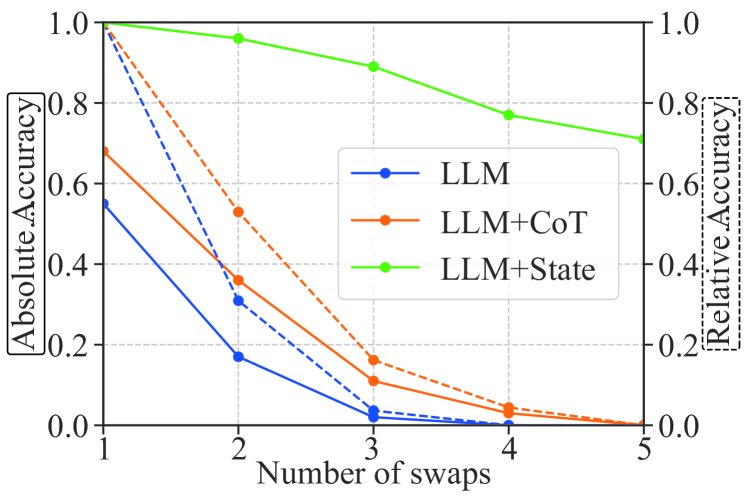
실험 결과
연구 질문
- RQ1명시적으로 유지된 세계 상태가 무상태 정책과 비교하여 다단계 로봇 계획을 향상시킬 수 있는가?
- RQ2분리된 세계 상태 읽기/쓰기 LLM들이 장기 과제에서 통합 프롬프트에 비해 측정 가능한 이점을 제공하는가?
- RQ3과거 상호작용을 추론할 때 Statler는 시뮬레이션 도메인과 실제 로봇 실험에서 어떻게 수행하는가?
- RQ4상태 유지 제거의 영향은 태스크 성공률 및 매단계 정확도에 어떤 영향을 주는가?
주요 결과
- Statler는 시뮬레이션에서 피킹-앤-플레이스, 소독, 및 중량 추론 과제에서 CaP 및 CaP+CoT를 크게 능가한다.
- 비-시간적 질의는 CaP에 대해 거의 완벽에 가까우나, 시간적 질의는 CaP의 성능 붕괴를 보인다; Statler는 기억 기반 질문에서 높은 성능을 유지한다.
- 실제 로봇 실험에서 Statler는 CaP보다 에피소드 및 단계 성공률이 더 높으며, LLM 추론이 주요 실패 원인(지각/조작도 기여한다).
- 제거 실험은 별도의 세계 상태 읽기/쓰기 구성을 유지하는 것이 통합 모델보다 더 나은 성능을 낳고, 에피소드 완료를 위해 상태 유지가 필수적임을 보여준다.
- Statler는 도메인 간 강건성을 보여주며 더 긴 호흡의 계획 과제에 대한 확장성을 약속한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.