[논문 리뷰] Strategic Reasoning with Language Models
이 논문은 사전학습된 언어 모델이 검색 구조, 가치 배정, 신념 추적을 체계적으로 구성하는 프롬프트를 사용하여 매트릭스 게임과 협상 게임에서 유연한 전략적 추론을 수행할 수 있음을 보여주며, 소수-shot 시연으로 새로운 게임과 목표에 일반화 가능성을 제공한다.
Strategic reasoning enables agents to cooperate, communicate, and compete with other agents in diverse situations. Existing approaches to solving strategic games rely on extensive training, yielding strategies that do not generalize to new scenarios or games without retraining. Large Language Models (LLMs), with their ability to comprehend and generate complex, context-rich language, could prove powerful as tools for strategic gameplay. This paper introduces an approach that uses pretrained LLMs with few-shot chain-of-thought examples to enable strategic reasoning for AI agents. Our approach uses systematically generated demonstrations of reasoning about states, values, and beliefs to prompt the model. Using extensive variations of simple matrix games, we show that strategies that are derived based on systematically generated prompts generalize almost perfectly to new game structures, alternate objectives, and hidden information. Additionally, we demonstrate our approach can lead to human-like negotiation strategies in realistic scenarios without any extra training or fine-tuning. Our results highlight the ability of LLMs, guided by systematic reasoning demonstrations, to adapt and excel in diverse strategic scenarios.
연구 동기 및 목표
- AI 에이전트가 새로운 전략적 시나리오에서 일반화 격차를 해소하도록 동기를 부여하고 다룬다.
- LLMs에 전략적 계획 능력을 부여하는 프롬프트 기반 방법 제안.
- few-shot 시연을 통해 새로운 게임 구조, 목표 및 부분 정보에 대한 일반화를 가능하게 한다.
- 현실적인 시나리오에서 재훈련 없이 인간에 가까운 협상 행동을 시연한다.
제안 방법
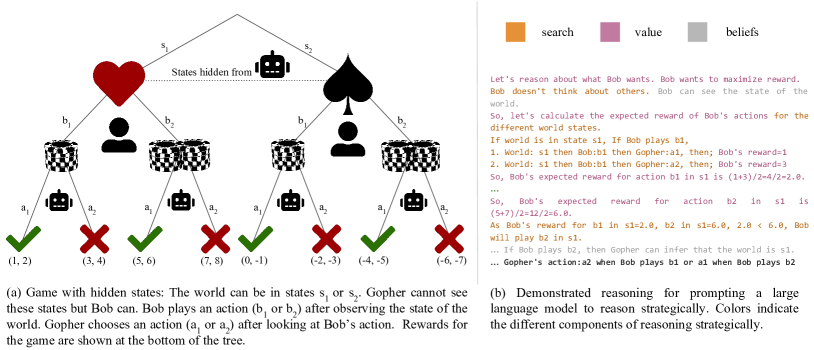
- 전략적 추론(검색, 가치 할당, 신념 추적)의 시연을 자동으로 생성하는 프롬프트 컴파일러를 개발.
- 행동 선택 전에 체인 오브 생각 추론 프롬프트를 통해 인-컨텍스트 시연으로 LLM을 편향시킨다.
- 매트릭스 게임에서 보상, 플레이어, 관찰 가능성, 턴을 다양화하여 일반화를 테스트.
- 협상 게임에서 값과 신념에 대해 모델의 추론을 이끌기 위해 인간 시연에 주석을 달아 활용한다.
- 도구(검색 및 계산)를 도입하여 맥락 제한 내에서 큰 의사결정 공간과 복잡한 추론을 관리한다.
- 다수의 LLM(코드-davinci-002 및 여러 텍스트 모델)로 벤치마크 및 절편 실험과 비교 평가.
실험 결과
연구 질문
- RQ1LLMs가 체계적으로 생성된 프롬프트를 사용하여 새로운 게임 구조와 목표에 대해 전략적 추론을 일반화할 수 있는가?
- RQ2추론을 검색, 가치 배정, 신념 추적으로 분해하는 것이 일반 프롬프트 대비 신뢰성을 개선하는가?
- RQ3LLMs가 추가 학습 없이 현실적인 설정에서 인간과 협상하고 인간과 유사한 행동을 보일 수 있는가?
- RQ4부분 관찰성과 정보의 변화가 모델의 전략적 추론 및 신념 형성에 어떤 영향을 미치는가?
주요 결과
- 검색, 가치 배정, 신념 추정을 구조화하는 프롬프트가 새로운 보상 및 게임 구조에 일반화를 가능하게 한다.
- 요인화된 추론은 새로운 게임 구조 및 부분 정보에 거의 완전한 일반화를 이끌어 벤치마크 프롬프트와 절편보다 우수하다.
- 이 접근법은 재훈련 없이도 인간에 가까운 현실성과 품질의 협상 행동을 지원한다.
- LLMs는 예시 시연으로 제로샷으로 새로운 목표(예를 들어 복지 극대화 또는 사용자 정의 daxity 메트릭)로 적응할 수 있다.
- 반복적 추론은 협상 공정성 지표를 향상시켜 Deal or No Deal 시나리오에서 신념 형성 없는 모델보다 우수하게 만든다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.