[논문 리뷰] Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
SPIRES는 고정된 스키마 기반 프롬프트 방식을 사용한 제로샷 학습으로 중첩 지식을 추출하고 지식 기반을 구축하며, 오픈 소스 OntoGPT 구현과 강력한 grounding 성능을 제공합니다. 학습 데이터 없이 새로운 작업을 가능하게 하고, 식별자 grounding을 위해 온톨로지스를 활용합니다.
Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
연구 동기 및 목표
- 자연어 텍스트로부터 작업 특화 학습 데이터 없이도 복잡하고 중첩된 지식 스키마를 자동으로 채우게 한다.
- 외부 온톨로지의 지속 가능한 식별자로 엔터티를 grounding하면서 프롬프트 기반 추출에 LLM을 활용한다.
- 중첩된 특성 구조를 처리하고 추론을 위한 OWL로의 변환을 지원하는 유연하고 스키마 기반 프레임워크를 제공한다.
- 여러 도메인에서 SPIRES를 시연하고 기본 LLM 프롬프트와의 grounding 정확도를 비교한다.
제안 방법
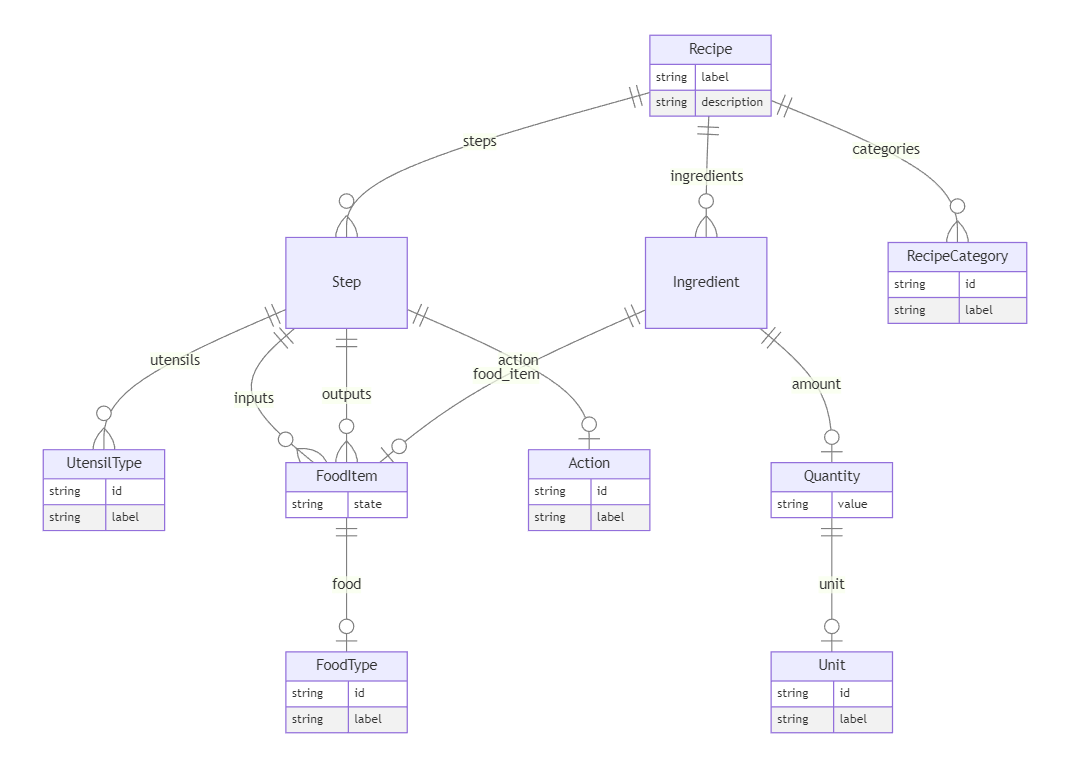
- 속성과 값 범위를 갖는 클래스들의 모음으로 지식 스키마 S를 정의하되, 다값 속성 및 중첩된 인라인 클래스를 포함한다.
- S, 대상 클래스 C, 입력 텍스트 T로부터 구조화된 프롬프트 p를 생성하되, 의사 YAML 속성 템플릿과 TextIntro 블록을 사용한다.
- 프롬프트를 완성하기 위해 LLM에 질의하고 구조화된 형태의 응답 r을 얻는다.
- r을 구문 분석하여 S에 부합하는 인스턴스 i를 재귀적으로 채우고, 리프 엔터티를 온톨로지(예: FOODON, Wikidata)와 도구(Gilda, OGER)를 통해 식별자로 grounding한다.
- 채워진 인스턴스를 선택적으로 OWL로 번역하고 OWL 도구(ROBOT, Elk)로 추론한다.
- 다중 도메인에 대해 미리 만들어진 스키마를 포함한 OntoGPT 기반의 파이썬 구현을 제공하고, 스키마 정의에는 LinkML, grounding에는 OAKlib를 사용한다.
실험 결과
연구 질문
- RQ1SPIRES가 임의로 중첩된 지식 스키마를 비구조화된 텍스트에서 아무 training 데이터 없이 채울 수 있는가?
- RQ2일반 프롬프트만 사용하는 LLM과 비교하여 SPIRES가 지속 가능한 온톨로지 식별자로의 엔터티 grounding을 어느 정도 개선하는가?
- RQ3MeSH/온톨로지에 grounding될 때 고전된 생물의학 관계 추출 작업에서 SPIRES의 성능은 어떤가?
- RQ4다양한 도메인(레시피, 신호 경로, 질병 치료 등)에 걸친 SPIRES의 실용성과 정확성은 어느 정도인가?
주요 결과
- SPIRES가 높은 grounding 정확도를 달성했으며, 예를 들어 GPT-3.5-turbo에서 100개 중 98개, GPT-4-turbo에서 100개 중 97개를 grounding했다.
- SPIRES 없이 GPT-3.5-turbo는 GO 용어에 대해 올바른 식별자가 거의 나오지 않는 등 grounding 없이 대량의 망상을 보여주었다.
- EMAPA 온톨로지에서 GPT-3.5-turbo로 모든 100개 용어에 대해 올바른 식별자를 산출했고, GPT-4-turbo는 일부 온톨로지에 대해 grounding을 일관되게 거부했다.
- BioCreative 화학-질환 관계 태스크에서 SPIRES가 청크를 사용한 경우 F=41.16(P=0.43, R=0.39), 청크 없는 경우 F=36.64(P=0.63, R=0.26)로, GPT-3.5-turbo에서 나타났으며, GPT-4-turbo는 F=43.80(P=0.69, R=0.32)을 달성했다.
- GPT-3.5-turbo가 BC5CDR에서 혼합적이지만 경쟁력 있는 성능을 보였고, 이는 학습 데이터를 사용한 18개 팀의 평균보다 약간 아래였으며, GPT-4-turbo는 grounding 동작이 달랐다.
- grounding은 프롬프트만 사용하는 접근법보다 현저히 개선되며, 새로운 학습 데이터 없이 제로샷, 스키마 기반 KB 채우기의 타당성을 뒷받침한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.