[논문 리뷰] Studying LLM Performance on Closed- and Open-source Data
이 논문은 OpenAI Codex 스타일의 LLM을 오픈 소스 코드와 마이크로소프트의 폐쇄 소스 코드에서 코드 완성, 요약, 생성에 대해 비교합니다. C#에서는 차이가 거의 없었지만 C++에서는 폐쇄 소스 데이터에서 성능 저하가 뚜렷하게 나타났고; 몇-shot 학습과 BM25로 검색된 예제가 일부 격차를 완화할 수 있습니다.
Large Language models (LLMs) are finding wide use in software engineering practice. These models are extremely data-hungry, and are largely trained on open-source (OSS) code distributed with permissive licenses. In terms of actual use however, a great deal of software development still occurs in the for-profit/proprietary sphere, where the code under development is not, and never has been, in the public domain; thus, many developers, do their work, and use LLMs, in settings where the models may not be as familiar with the code under development. In such settings, do LLMs work as well as they do for OSS code? If not, what are the differences? When performance differs, what are the possible causes, and are there work-arounds? In this paper, we examine this issue using proprietary, closed-source software data from Microsoft, where most proprietary code is in C# and C++. We find that performance for C# changes little from OSS --> proprietary code, but does significantly reduce for C++; we find that this difference is attributable to differences in identifiers. We also find that some performance degradation, in some cases, can be ameliorated efficiently by in-context learning.
연구 동기 및 목표
- Open 소스 데이터로 학습된 LLM이 대규모 소프트웨어 공급업체(Microsoft)의 폐쇄 소스 코드에 적용될 때도 비슷한 성능을 보이는지 평가합니다.
- OSS와 폐쇄 소스 데이터셋 간에 C#과 C++의 언어별 차이를 평가합니다.
- 성과 격차의 잠재적 원인과 몇-shot 인-context 학습 또는 검색 기반 예제가 이를 해소할 수 있는지 조사합니다.
- OSS 예제를 통해 폐쇄 소스 코드에서 인-context 학습 기법으로 성능을 개선할 수 있는지 탐색합니다.]
- method:[
- Code-Davinci-002와 GPT-3.5-Turbo의 두 가지 일반용 LLM을 미세 조정 없이 사용합니다.
- CodeXGLUE 듀의 네 가지 작업(토큰 완성, 행 완성, 코드 요약, 코드 생성)을 평가합니다.
- OSS 대 폐쇄 소스 성능을 C#과 C++에 대해 비교합니다.
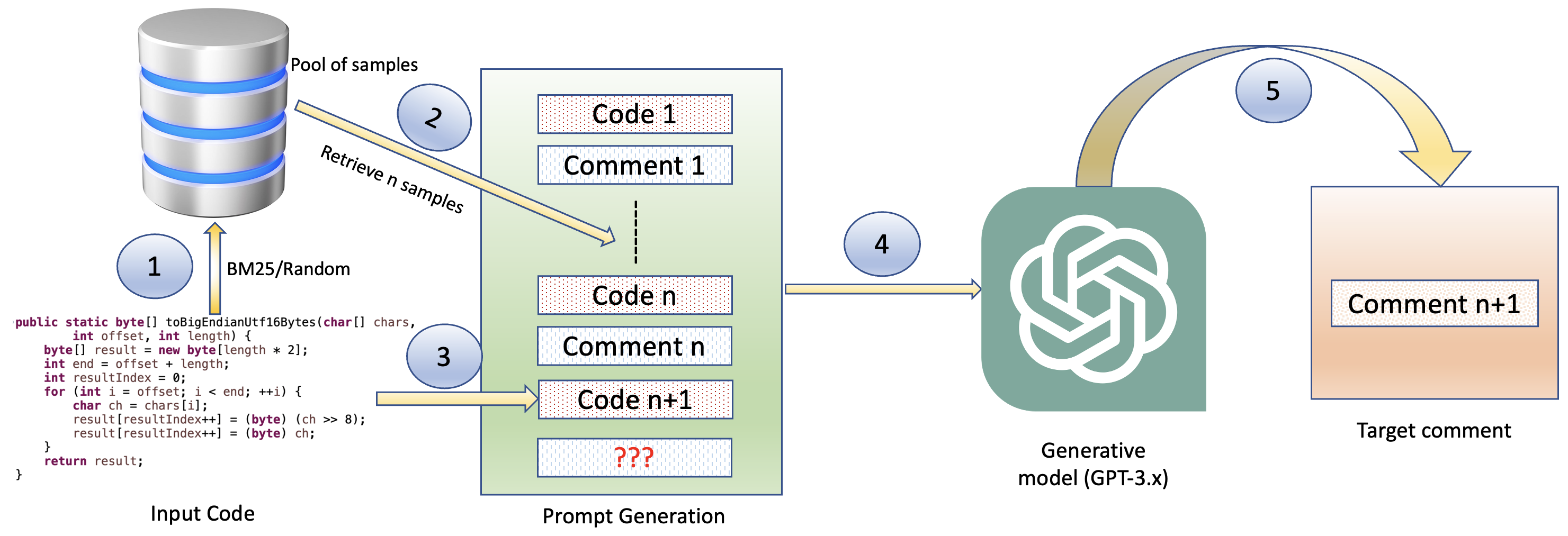
- 코드 요약 및 코드 생성을 위한 예제로 임의로 선택된 샘플과 BM25로 검색된 샘플을 사용한 few-shot 학습을 적용합니다.
- 정확 일치(Exact-match), BLEU 변형, ROUGE-L, METEOR, 편집 유사도 등을 평가 지표로 사용하며, 가능하면 통계적 검정을 보고합니다.]
- research_questions:[
- RQ1: 연구된 언어와 작업에서 오픈 소스 대 폐쇄 소스 데이터에 대해 LLM이 다른 성능을 보이나요?
- RQ2: 오픈 소스 예제를 사용하는 few-shot 학습이 폐쇄 소스 데이터의 성능을 개선할 수 있나요?
- RQ3: OSS와 폐쇄 소스 데이터 간의 C#과 C++의 성능 차이가 무엇에 의해 발생하나요?
제안 방법
- 이를 위한 2개의 일반-목적 LLM(Code-Davinci-002, GPT-3.5-Turbo)을 파인 튜닝 없이 사용합니다.
- CodeXGLUE 모음의 네 가지 태스크(토큰 완성, 행 완성, 코드 요약, 코드 생성)를 평가합니다.
- C#과 C++에 대해 OSS 대 폐쇄 소스 성능을 비교합니다.
- few-shot 학습을 무작위로 선택된 샘플과 BM25로 검색된 샘플을 예제로 사용하여 코드 요약 및 코드 생성에 적용합니다.
- 정확 매칭, BLEU 변형, ROUGE-L, METEOR, 편집 유사도와 같은 평가 지표를 사용하고 필요한 경우 통계적 검정을 보고합니다.]
- research_questions:
- RQ1: 연구된 언어와 작업에서 오픈 소스 대 폐쇄 소스 데이터에 대해 LLM이 다른 성능을 보이나요?
- RQ2: 오픈 소스 예제를 사용하는 few-shot 학습이 폐쇄 소스 데이터의 성능을 개선할 수 있나요?
- RQ3: OSS와 폐쇄 소스 데이터 간의 C#과 C++의 성능 차이가 무엇에 의해 발생하나요?
실험 결과
연구 질문
- RQ1RQ1: 연구된 언어와 작업에서 오픈 소스 대 폐쇄 소스 데이터에 대해 LLM이 다른 성능을 보이나요?
- RQ2RQ2: 오픈 소스 예제를 사용하는 few-shot 학습이 폐쇄 소스 데이터의 성능을 개선할 수 있나요?
- RQ3RQ3: OSS와 폐쇄 소스 데이터 간의 C#과 C++의 성능 차이가 무엇에 의해 발생하나요?
주요 결과
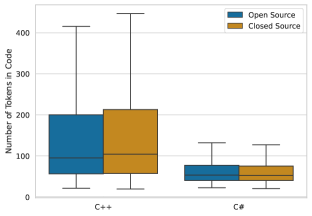
- 토큰 완성에서 C#은 Code-Davinci-002로 OSS와 폐쇄 소스 간 차이가 유의하게 나타나지 않음(OSS 71.32% 대 폐쇄 71.59%; p=0.67).
- C++의 토큰 완성에서 OSS(71.93%)에서 폐쇄소스(64.42%)로의 유의한 감소가 나타남(Code-Davinci-002; p<0.01).
- 행 완성은 동일한 언어 격차를 보임: C#은 OSS 대 폐쇄 소스 간 차이가 유의하지 않지만 C++은 폐쇄 소스 성능이 감소.
- few-shot 학습 및 BM25로 검색된 예제로 C#의 경우 OSS 대 폐쇄 소스 격차를 줄이는 경향이 있음; BM25가 어느 정도 이점을 제공하지만, C++의 격차는 지속되며 모델에 따라 BM25 사용 시 더 커질 수 있음.
- 코드 생성은 요약에 비해 일반적으로 성능이 낮고, 특히 C++에서 OSS와 폐쇄 소스 간 차이가 더 크며 few-shot 학습에도 개선이 제한적임.
- 전반적으로 C#은 OSS/폐쇄 소스 간 일관된 성능을 보이나, C++는 폐쇄 소스 데이터에서 실질적인 저하를 보이며 BM25로 검색된 few-shot 샘플이 일부 격차를 완화시킬 수는 있으나 모든 격차를 해소하지는 못합니다.]
- table_headers translated: [
- 언어
- 모델
- 작업
- OSS_성능
- 폐쇄 소스 성능
- p-값
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.