[논문 리뷰] SVIT: Scaling up Visual Instruction Tuning
SVIT는 4.2 million-instruction 데이터셋을 구축하여 비주얼 인스트럭션 튜닝을 확장하고, 새로운 코어스트 데이터 레시피와 전체 및 LoRA 파인튜닝을 사용하여 SVIT-v1.5가 다중 벤치마크에서 최첨단 멀티모달 LLM을 능가함을 보여준다.
Thanks to the emerging of foundation models, the large language and vision models are integrated to acquire the multimodal ability of visual captioning, question answering, etc. Although existing multimodal models present impressive performance of visual understanding and reasoning, their limits are still largely under-explored due to the scarcity of high-quality instruction tuning data. To push the limits of multimodal capability, we Scale up Visual Instruction Tuning (SVIT) by constructing a dataset of 4.2 million visual instruction tuning data including 1.6M conversation question-answer (QA) pairs, 1.6M complex reasoning QA pairs, 1.0M referring QA pairs and 106K detailed image descriptions. Besides the volume, the proposed dataset is also featured by the high quality and rich diversity, which is generated by prompting GPT-4 with the abundant manual annotations of images. We also propose a new data recipe to select subset with better diversity and balance, which evokes model's superior capabilities. Extensive experiments verify that SVIT-v1.5, trained on the proposed dataset, outperforms state-of-the-art Multimodal Large Language Models on popular benchmarks. The data and code are publicly available at https://github.com/BAAI-DCAI/Visual-Instruction-Tuning.
연구 동기 및 목표
- 다중모달 모델의 데이터 부족을 극복하기 위해 시각 지시 튜닝 확장 동기를 제시한다.
- GPT-4 프롬프트를 통해 생성된 대규모, 다양하고 고품질 VG/COCO 기반 지시 데이터셋을 구성한다.
- 다양성 및 균형을 위한 코어스트 선정을 포함한 데이터-그다음 모델 전략을 제안한다.
- SVIT-v1.5가 표준 벤치마크에서 기존 MLLM을 능가한다는 것을 입증한다.
제안 방법
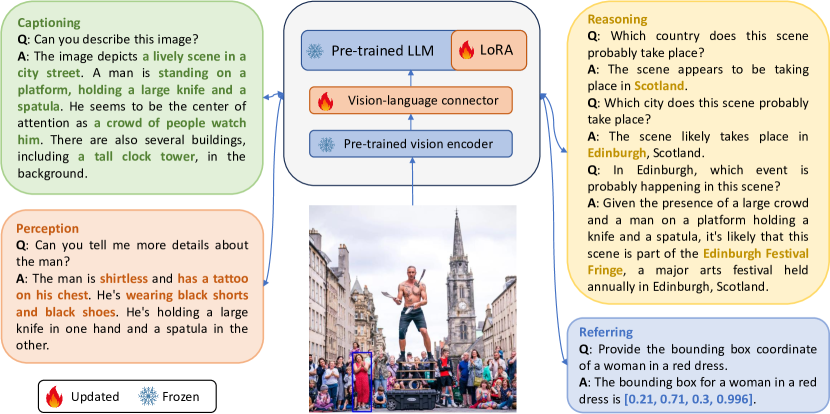
- Rich annotations가 있는 Visual Genome 및 COCO로부터 SVIT를 구성하고 Four task types를 생성하기 위해 GPT-4 프롬프트를 사용한다: 대화 QA, 복합 추론 QA, referential QA, 상세 이미지 설명.
- 이미지-텍스트 쌍에서 비전-언어 커넥터를 사전 학습하되 비전 인코더와 LLM은 고정하고, 그 후 커넥터와 LLM(전체 또는 LoRA)을 시각 지시 데이터로 미세조정하는 두 단계 학습 파이프라인을 사용한다.
- 다양성 및 균형 인식 코어스트로서 SVIT-core-150K를 GPT-4 구동 컨셉 중첩 필터와 예/아니오 균형 조정을 통해 도입한다.
- SVIT-mix-665K를 기존 데이터의 일부를 SVIT-core-150K로 교체하여 데이터 효율성을 테스트하고 더 큰 이득을 얻기 위해 SVIT-train으로 확장한다.
실험 결과
연구 질문
- RQ1고품질 시각 지시 데이터의 확장이 표준 벤치마크에서 다중모달 모델의 성능에 어떤 영향을 미치는가?
- RQ2다양성 및 균형을 고려한 데이터 서브세트(코어스트)가 지시-튜닝의 효율성과 효과를 개선할 수 있는가?
- RQ3SVIT 데이터로 학습될 때 전체 파라미터 미세튜닝과 LoRA 미세튜닝의 이점은 무엇인가?
- RQ4데이터 규모를 늘리는 것이 (SVIT-train) 지각 및 인지 과제에서 일관된 개선을 가져오는가?
주요 결과
- SVIT-v1.5 (Full)는 LLaVA-v1.5 및 기타 모델보다 대부분의 벤치마크에서 우수한 성능을 보이며, MME 지각 및 인지에서 강한 이점을 보인다.
- SVIT-v1.5 (LoRA)는 LLaVA-v1.5 (LoRA)보다 MME 인지에서 우수하며, 효율적인 파인튜닝으로 상당한 이점을 보여준다.
- 다양성 중심의 SVIT-80K-D가 무작위로 선택된 SVIT-80K보다 성능을 20.3 포인트 향상시킨다.
- 학습 데이터에서 Yes/No 질문의 균형을 맞추면 SVIT-80K 대비 MME에서 7.1%의 향상을 달성한다.
- SVIT-train(더 큰 데이터) 확장은 SVIT-80K 대비 총 MME 점수를 +12.7% 올리며, 객체 존재 여부, 색상 및 OCR 과제에서 주목할 만한 이득을 얻는다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.