[논문 리뷰] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
SWE-bench는 저장소 전체 패치를 필요로 하는 2,294개의 실세계 GitHub 이슈를 실행 기반 벤치마크로 평가합니다; 최첨단 모델은 가장 간단한 작업만 해결하며, oracle 검색에서 Claude 2는 4.8%와 GPT-4는 1.7%에 불과하고 BM25 컨텍스트 검색에서는 더 나쁘게 나타납니다.
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We find real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. To this end, we introduce SWE-bench, an evaluation framework consisting of $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere $1.96$% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
연구 동기 및 목표
- 대형 언어 모델이 GitHub 이슈를 해결하기 위해 패치 파일을 생성함으로써 실제 코드베이스를 편집할 수 있는지 평가합니다.
- 다양하고 긴 컨텍스트의 코드 편집 작업을 다수의 파이썬 저장소에 걸쳐 제공하는 도전적이고 최신의 벤치마크를 제공합니다.
- 실행 기반 검증을 기존 테스트 스위트를 사용하여 재현 가능한 평가 프레임워크를 제공합니다.
- 더 자율적인 코드 편집 LMs를 촉진하기 위한 학습 데이터 및 미세 조정 모델을 공개합니다.
제안 방법
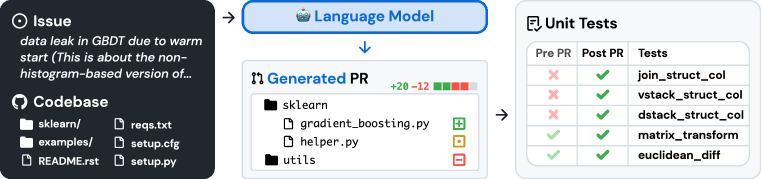
- 테스트 및 이슈를 테스트를 수정하고 이슈를 해결하는 PR에 연결하여 12개의 유명한 파이썬 저장소로부터 SWE-bench를 구성합니다.
- 3단계 파이프라인(저장소 수집, 속성 필터링, 실행 기반 필터링)을 통해 2,294개의 작업 인스턴스로 축소합니다.
- 작업을 이슈 텍스트와 코드베이스 스냅샷으로 표현하고, 모델은 저장소 전체에 걸친 패치 파일을 생성합니다.
- 패치를 적용하고 저장소 테스트를 실행하여 편집을 평가합니다; 주요 지표로 합격률을 측정합니다.
- 길고 큰 코드베이스 내에서 관련 컨텍스트를 제공하기 위한 검색 전략(BM25 희소 검색 및 오라클 검색)을 탐구합니다.
- 37개 저장소의 19,000개의 추가 이슈-PR 쌍에 대해 LoRA로 SWE-Llama 7b/13b를 미세 조정하여 경쟁력 있는 개방형 모델 기준선을 만듭니다.
실험 결과
연구 질문
- RQ1대형 코드베이스에 대한 패치를 생성해 실제 소프트웨어 엔지니어링 이슈를 해결할 수 있는 현재 LM의 능력은 어느 정도인가?
- RQ2맥락 검색 전략과 패치 생성 형식이 모델 성능에 어떤 영향을 미치는가?
- RQ3오픈 모델의 미세 조정으로 저장소 규모의 코드 편집에서 독점 모델과의 격차를 줄일 수 있는가?
- RQ4작업 난이도, 컨텍스트 길이, 저장소 특성이 SWE-bench에서 LM 성능에 어떤 영향을 미치는가?
주요 결과
- 대부분의 최첨단 모델은 가장 간단한 작업을 넘어서 해결하지 못합니다; Claude 2는 4.8%를 달성하고 GPT-4는 1.7%를 달성합니다(오라클 검색 하에서).
- BM25 기반 검색은 성능을 더 악화시키며(Claude 2는 1.96%로 떨어집니다).
- 미세 조정된 SWE-Llama 모델(7b/13b)은 제한된 성공을 보이고 컨텍스트 분포 변화에 민감할 수 있습니다.
- 모델 편집은 보통 금색 패치보다 더 짧고 단순한 경향이 있으며 더 적은 줄과 파일을 편집하는 경향이 있습니다.
- 컨텍스트 길이를 늘리면 큰 컨텍스트 내에서 관련 편집을 국지화하기 어려워 성능이 떨어질 수 있습니다.
- 오라클 검색 컨텍스트가 제공되더라도 모델이 올바르고 형식이 잘 갖춰진 패치 파일을 생성하는 경우는 드물며, 생성된 패치의 절반가량은 금색보다 짧고 여러 파일을 편집하는 경우가 적습니다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.