[논문 리뷰] SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
SweetDreamer는 2D 확산 기하학적 priors와 거친 3D 기하를 정렬하여 3D-일관된 텍스트-투-3D 결과를 달성하고, 기존 파이프라인에 최첨단 일관성과 함께 원활하게 통합 가능하게 한다.
It is inherently ambiguous to lift 2D results from pre-trained diffusion models to a 3D world for text-to-3D generation. 2D diffusion models solely learn view-agnostic priors and thus lack 3D knowledge during the lifting, leading to the multi-view inconsistency problem. We find that this problem primarily stems from geometric inconsistency, and avoiding misplaced geometric structures substantially mitigates the problem in the final outputs. Therefore, we improve the consistency by aligning the 2D geometric priors in diffusion models with well-defined 3D shapes during the lifting, addressing the vast majority of the problem. This is achieved by fine-tuning the 2D diffusion model to be viewpoint-aware and to produce view-specific coordinate maps of canonically oriented 3D objects. In our process, only coarse 3D information is used for aligning. This "coarse" alignment not only resolves the multi-view inconsistency in geometries but also retains the ability in 2D diffusion models to generate detailed and diversified high-quality objects unseen in the 3D datasets. Furthermore, our aligned geometric priors (AGP) are generic and can be seamlessly integrated into various state-of-the-art pipelines, obtaining high generalizability in terms of unseen shapes and visual appearance while greatly alleviating the multi-view inconsistency problem. Our method represents a new state-of-the-art performance with an 85+% consistency rate by human evaluation, while many previous methods are around 30%. Our project page is https://sweetdreamer3d.github.io/
연구 동기 및 목표
- 다중 시점에서 2D 확산 결과를 3D로 올릴 때 발생하는 불일치를 줄여야 할 필요성을 동기 부여한다.
- 거친 정렬(coarse alignment)을 사용하여 2D 기하학적 priors를 정준 3D 기하학과 맞추는 방법을 제안한다.
- AGP가 여러 3D 표현과 파이프라인에 어떻게 통합될 수 있는지 보여준다.
- 2D 확산의 일반화 가능성을 유지하면서 3D 일관성이 개선되는 것을 입증한다.
제안 방법
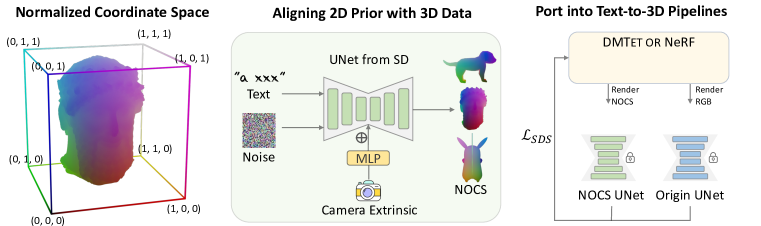
- 정준 방향으로 배치된 3D 물체에서 viewpoint-conditioned canonical coordinates maps(CCMs)을 생성하도록 2D diffusion 모델을 미세 조정한다.
- 거친 3D 깊이 맵을 CCM으로 렌더링하고 카메라 외부 파라미터를 MLP를 통해 확산 모델에 조건으로 공급한다.
- VAE를 통한 재인코딩/재디코딩 없이 CCM을 학습하기 위해 Stable Diffusion의 잠재 공간 학습 설정을 사용한다.
- 텍스트-투-3D 파이프라인에 거친 3D priors를 주입하여 기하를 감독(SDS 손실)하고 외관 priors은 그대로 유지한다.
- 정렬된 기하 감독 용어를 추가하여 Fantasia3D(DMTet) 및 DreamFusion(NeRF) 파이프라인과의 통합을 입증한다.
- 필터링 후 270k 개의 Objaverse 객체로부터 데이터와 거친 카메라 샘플링을 활용하여 CCM-조건부 확산 모델을 학습한다.

실험 결과
연구 질문
- RQ12D 확산 priors를 정준 3D 기하학으로 정렬하는 것이 텍스트-투-3D 리핑에서 다중 시점 불일치를 줄일 수 있는가?
- RQ2거친 정렬된 기하 priors가 2D 일반화를 보존하면서 3D 일관성을 향상시키는가?
- RQ3AGP를 여러 3D 표현에 통합하는 것이 외관 품질을 훼손하지 않고 가능한가?
- RQ4카메라 조건 설정과 CCM이 다양한 프롬프트와 형상에서 3D 일관성에 미치는 영향은 무엇인가?
- RQ5AGP가 인간 인지 기준의 3D 일관성에서 기존 기준선과 비교해 어떤 성능을 보이는가?
주요 결과
- AGP는 두 파이프라인에서 사람 기반 평가 일관성 비율 85% 이상으로 최첨단 3D 일관성을 달성한다.
- AGP 기반 방법은 일관성 측면에서 DreamFusion-IF, Magic3D-IF, TextMesh-IF, SJC, Fantasia3D와 같은 기준선보다 현저히 우수하다.
- 학습에는 거친 3D 기하 맵만 사용하며 고해상도 3D 외관 데이터에 대한 강한 의존을 피한다.
- AGP는 여러 3D 표현(DMTet 및 NeRF)과 호환되며 추가 감독 분기로 통합될 수 있다.
- 이 접근법은 보지 못한 형태와 외관에 대해 2D diffusion 모델의 풍부한 생성 가능성을 유지한다.
- 사용자 연구는 3D 일관성 측면에서 AGP 지원 결과를 기준선에 비해 강건하게 선호하는 경향을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.