[논문 리뷰] Swin Transformer V2: Scaling Up Capacity and Resolution
이 논문은 Swin Transformer를 3B 파라미터와 1,536×1,536 이미지로 확장하는데 residual-post-norm, scaled cosine attention, log-spaced continuous position bias의 도움을 받고, self-supervised pre-training으로 지원하여 여러 비전 태스크에서 SOTA를 달성한다.
Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536$ imes$1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time. Code is available at \url{https://github.com/microsoft/Swin-Transformer}.
연구 동기 및 목표
- 언어 모델과의 용량 격차를 해소하기 위해 비전 트랜스포머의 확장을 추진한다.
- 모델 용량 확장 시 발생하는 학습 불안정성을 다룬다.
- 고해상도 입력에 대한 프리트레이닝과 파인튜닝 간 해상도 격차를 해소한다.
- 자기지도 사전학습을 통해 대규모 라벨링 데이터 의존도를 줄인다.
제안 방법
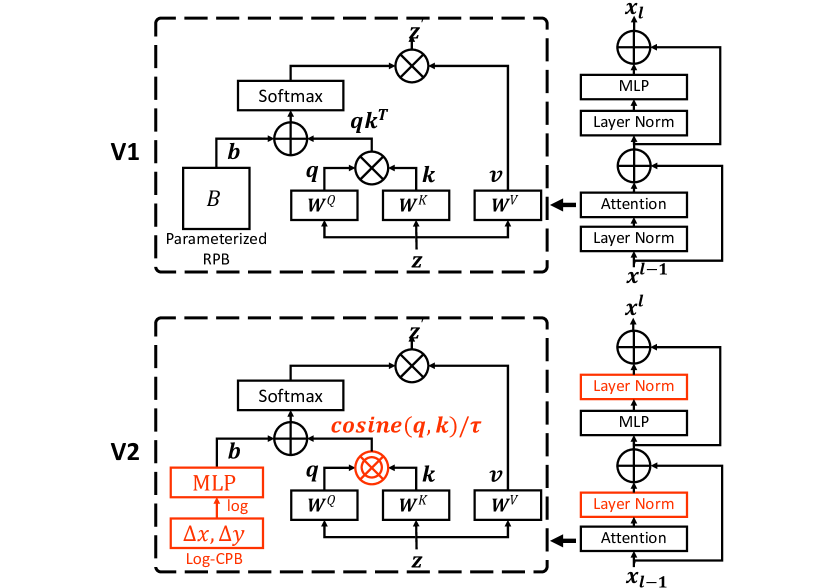
- 잔여 출력을 메인 분기로 합류하기 전에 정규화하여 학습을 안정시키기 위해 residual post-normalization (res-post-norm)을 도입한다.
- 큰 모델에서 극단적인 어텐션 값을 완화하기 위해 dot-product attention을 scaled cosine attention으로 대체한다.
- 다른 윈도우 크기 간 전이를 가능하게 하는 소형 메타 네트워크가 생성하는 log-spaced continuous position bias (Log-CPB)를 제안한다.
- 레이블링 데이터 의존성을 줄이고 매우 큰 모델의 학습을 가능하게 하려면 self-supervised pre-training (SimMIM)을 사용한다.
- 메모리 및 계산 절감을 위한 기법들(ZeRO, activation checkpointing, sequential self-attention)을 적용하여 고해상도에서 최대 3B 파라미터를 훈련한다.
실험 결과
연구 질문
- RQ1학습 안정성을 유지하면서 비전 트랜스포머를 수십억 개의 파라미터로 확장하려면 어떻게 가능할까?
- RQ2프리트레이닝을 서로 다른 입력 해상도와 윈도우 크기에서도 전이 가능하도록 어떻게 만들 수 있을까?
- RQ3대형 비전 모델에서 자기지도 사전학습이 라벨링 데이터 요구량을 줄일 수 있을까?
- RQ4대형 비전 백본을 고해상도 이미지에서 효율적으로 학습시키게 하는 어떤 아키텍처 및 최적화 전략의 조합이 가능할까?
주요 결과
- 3B 파라미터 Swin Transformer V2가 다수의 비전 태스크에서 SOTA를 달성: ImageNet-V2 top-1 84.0%, COCO 객체 탐지 63.1/54.4 box/mask AP, ADE20K 59.9 mIoU, 및 Kinetics-400 86.8% top-1.
- Res-post-norm과 스케일드 코사인 어텐션은 안정성과 정확도를 향상시키며, 특히 더 큰 모델에서 두드러진다.
- Log-spaced continuous position bias는 윈도우 크기 간 효과적인 전이를 가능하게 한다(더 작은 윈도우로 프리트레이닝하고 더 큰 윈도우로 파인튜닝).
- 자기지도 사전학습 (SimMIM)은 상당히 적은 라벨링 데이터로도 강한 성능을 달성한다(라벨링 이미지 70M 사용 vs. 선행 연구의 40× 더 많음).
- 메모리 및 계산 절감을 위한 전략들(ZeRO, activation checkpointing, sequential self-attention)은 대형 모델에서 1,536×1,536 해상도로의 학습을 가능하게 한다.
![Figure 2 : The Signal Propagation Plot [ 76 , 6 ] for various model sizes. H-size models are trained at a self-supervised learning phase, and other sizes are trained by an image classification task. * indicates that we use a 40-epoch model before it crashes.](https://ar5iv.labs.arxiv.org/html/2111.09883/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.