[논문 리뷰] SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
SyncDreamer은 3D 인지 특징 주의와 동기화된 다중 뷰 확산을 사용하여 한 입력 뷰에서 다중 뷰 일관된 이미지를 생성하고, 뷰 간 일관성 없는 출력 없이 3D 재구성을 향상시킨다.
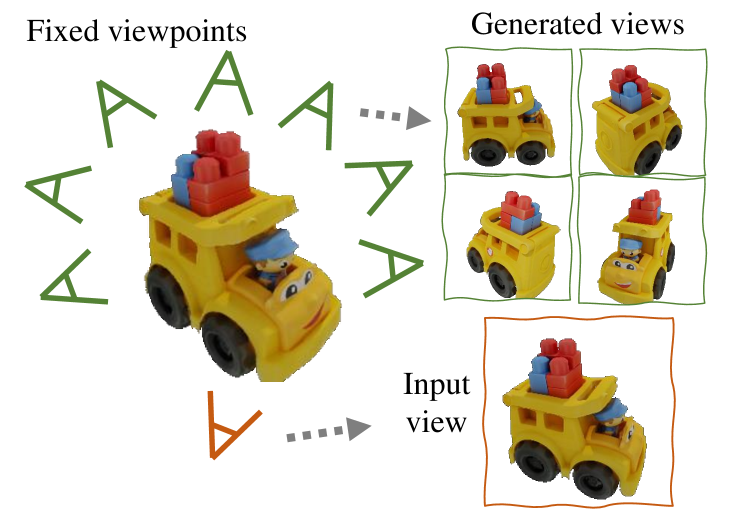
In this paper, we present a novel diffusion model called that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
연구 동기 및 목표
- 임의의 객체 전반에 걸쳐 강건한 단일 뷰에서 다중 뷰 3D 재구성을 가능하게 하고 동기를 부여한다.
- 공동 다중 뷰 확산 모델을 사용하여 생성된 이미지의 다중 뷰 간 불일치를 극복한다.
- 노이즈 제거 과정에서 교차 뷰 정보를 동기화하기 위해 3D 인식 특징 주의 메커니즘을 활용한다.
- 다양한 입력 스타일에 걸친 일반화 능력을 보존하기 위해 사전 학습된 2D 확산 모델에서 초기화한다.
제안 방법
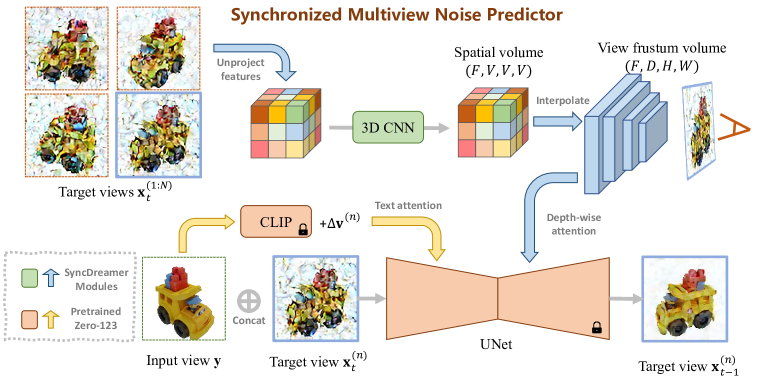
- N개의 동기화된 노이즈 예측기를 사용하여 N 뷰의 공동 분포를 모델링하도록 확산 모델을 확장한다.
- Zero123(Stable Diffusion 기반)에서 초기화된 공유 UNet을 모든 뷰의 백본으로 사용한다.
- 전역 공간 부피에서 파생된 뷰 프러스텀에 대해 깊이 방향 주의 메커니즘을 구성하는 3D 인식 특징 주의를 도입한다.
- 매 스텝에서 임의로 선택된 뷰의 노이즈를 예측하는 손실을 사용해 학습하여 뷰 간 동기화를 가능하게 한다.
- 고정된 시점 집합(N = 16)을 렌더링하고 Objaverse 데이터를 사용해 교차 뷰 일관성을 학습한다.
실험 결과
연구 질문
- RQ1확산 과정이 단일 입력 이미지로부터 다중 뷰를 공동으로 모델링하고 동기화하여 교차 뷰 일관성을 보장하도록 확장될 수 있는가?
- RQ2노이즈 제거 중 교차 뷰 정보를 어떻게 인코딩하고 전파하여 뷰 간 기하학 및 색상 일관성을 보장할 수 있는가?
- RQ3강력한 2D 확산 백본(Zero123)에서 초기화하는 것이 3D 재구성을 위한 임의의 객체 및 입력 스타일에 대한 일반화를 향상시키는가?
- RQ43D 인지 주의 메커니즘이 다중 뷰 일관성과 하위 3D 재구성 품질에 미치는 영향은 무엇인가?
주요 결과
| 지표 | RealFusion | Zero123 | Ours |
|---|---|---|---|
| NVS - PSNR | 15.26 | 18.93 | 20.05 |
| NVS - SSIM | 0.722 | 0.779 | 0.798 |
| NVS - LPIPS | 0.283 | 0.166 | 0.146 |
| NVS - #Points | 4010 | 95 | 1123 |
| SVR - Chamfer Dist. | 0.0819 | 0.0339 | 0.0261 |
| SVR - Volume IoU | 0.2741 | 0.5035 | 0.5421 |
- SyncDreamer는 Google Scanned Object 데이터셋에서 베이스라인보다 더 높은 다중 뷰 일관성과 재구성 품질을 달성한다.
- 새로운 시점 합성에서 RealFusion, Zero123, SyncDreamer의 PSNR/SSIM/LPIPS는 각각 15.26/0.722/0.283, 18.93/0.779/0.166, 20.05/0.798/0.146이며, #Points는 4010, 95, 1123이다.
- 단일 뷰 재구성에서 SyncDreamer는 Chamfer Distance 0.0261 및 Volume IoU 0.5421을 달성하여 RealFusion(0.0819, 0.2741) 및 Zero123(0.0339, 0.5035)보다 우수하다.
- 본 방법은 시드를 바꾸어 같은 입력으로부터 여러 개의 그럴듯한 인스턴스를 생성하는 것을 지원한다.
- 변인 실험은 3D 인지 주의와 백본으로 Zero123를 사용하는 것이 2D 스타일과 그림 전반에 걸친 일반화에 필요함을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.