[논문 리뷰] Synthetic Data Generation with LLM for Improved Depression Prediction
본 논문은 LLM을 사용한 체인-오브-사고(사고 흐름) 프롬프트 파이프라인을 제시하여 DAIC-WOZ 대본에서 합성 시놉시스 및 감정 데이터를 생성하고, 실제 데이터를 보강하여 우울 증상 정도 예측을 개선하되 프라이버시 및 데이터 불균형 문제를 해결한다.
Automatic detection of depression is a rapidly growing field of research at the intersection of psychology and machine learning. However, with its exponential interest comes a growing concern for data privacy and scarcity due to the sensitivity of such a topic. In this paper, we propose a pipeline for Large Language Models (LLMs) to generate synthetic data to improve the performance of depression prediction models. Starting from unstructured, naturalistic text data from recorded transcripts of clinical interviews, we utilize an open-source LLM to generate synthetic data through chain-of-thought prompting. This pipeline involves two key steps: the first step is the generation of the synopsis and sentiment analysis based on the original transcript and depression score, while the second is the generation of the synthetic synopsis/sentiment analysis based on the summaries generated in the first step and a new depression score. Not only was the synthetic data satisfactory in terms of fidelity and privacy-preserving metrics, it also balanced the distribution of severity in the training dataset, thereby significantly enhancing the model's capability in predicting the intensity of the patient's depression. By leveraging LLMs to generate synthetic data that can be augmented to limited and imbalanced real-world datasets, we demonstrate a novel approach to addressing data scarcity and privacy concerns commonly faced in automatic depression detection, all while maintaining the statistical integrity of the original dataset. This approach offers a robust framework for future mental health research and applications.
연구 동기 및 목표
- 텍스트에서의 우울 탐지에서 합성 데이터를 생성하여 데이터 부족과 개인정보 문제를 해결한다.
- 우울 점수에 조건화된 두 단계 시놉시스 및 감정 분석 생성 프로세스를 개발한다.
- 우울 정도 예측 개선을 위한 합성 데이터의 충실도, 활용도, 개인정보 보호를 평가한다.
제안 방법
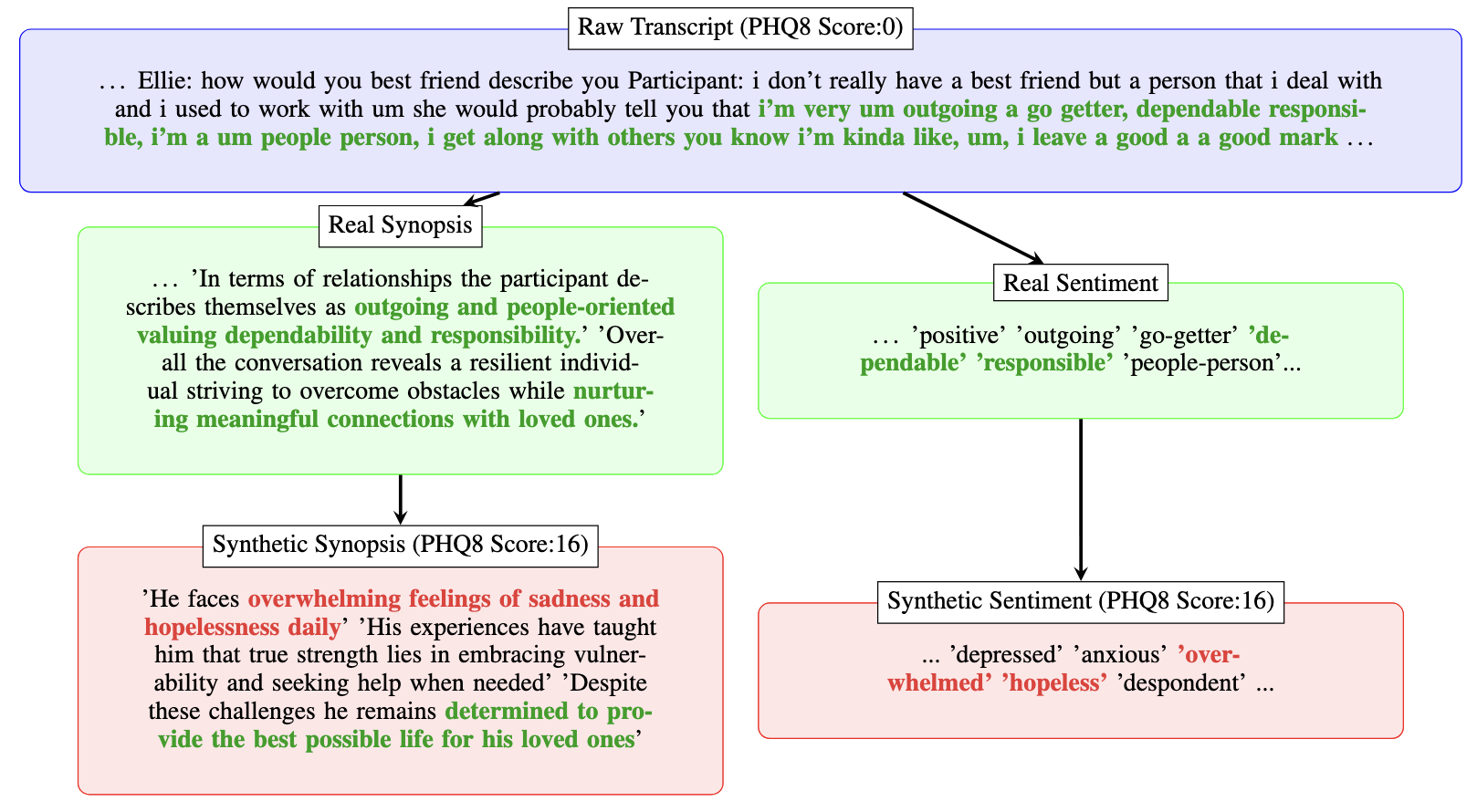
- 원본 대본으로부터 초기 시놉시스와 감정 분석을 생성하기 위해 Meta Llama 3.2-3B-Instruct를 사용한다.
- 새로 무작위로 생성된 PHQ-8 점수에 대한 합성 시놉시스 및 감정 분석 생성을 위해 체인-오브-사고 프롬프트를 적용한다.
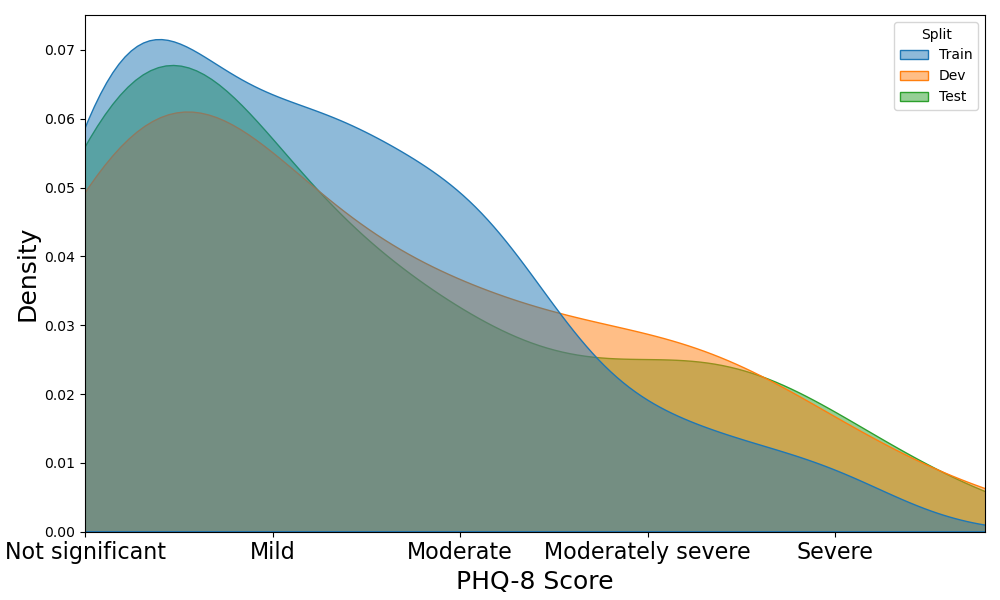
- 편향을 줄이기 위해 합성 데이터에서 더 높은 PHQ-8 점수를 오버샘플링하여 데이터 분포를 균형 있게 한다.
- 합성 데이터로 모델을 학습한 뒤 실데이터와 통합하여 성능 향상을 평가한다.
- 합성 데이터와 실데이터 간 임베딩 거리 지표를 통해 프라이버시를 평가하고, 시놉시스 임베딩의 PCA로 충실도를 시각화한다.
실험 결과
연구 질문
- RQ1체인-오브-사고 프롬프트로 생성된 합성 데이터가 실제 데이터에 추가되었을 때 우울 증상의 예측을 개선할 수 있는가?
- RQ2시놉시스 기반 합성 대본이 원래 데이터의 주요 통계적 특성(충실도)을 보존하고 참가자 프라이버시를 보호하는가?
- RQ3실제 데이터만 학습된 모델과 비교하여 합성 데이터가 모델 학습에 미치는 영향은 어떤가?
- RQ4PHQ-8 점수의 클래스 불균형 처리에 대한 합성 샘플로의 데이터 보강이 미치는 영향은 무엇인가?
주요 결과
- 합성 데이터만으로 PHQ-8 점수 예측에서 RMSE 4.80 및 MAE 4.06을 얻어 일부 실제 데이터 기반 기준선보다 우수하다.
- 원본 데이터와 합성 데이터를 결합하면 RMSE 4.64 및 MAE 3.66으로 최상의 결과를 얻는다.
- 이 설정에서 결합 데이터로 학습된 BERT 모델이 Random Forest 및 GPT-4o 기준선보다 더 우수하다.
- 시놉시스 임베딩의 PCA는 원본 데이터와 합성 데이터 간 겹침을 보이고, 합성 데이터가 심한 우울 영역으로 확장된다.
- 프라이버시 분석에서 Real vs. Synthetic의 평균 임베딩 거리가 Real vs. Real보다 높아 실데이터와 더 큰 이질성을 나타내고 더 나은 프라이버시 보호를 시사한다.
- 합성 데이터가 데이터 다양성을 개선하고 PHQ-8 점수 분포의 균형을 돕는 등 모델 성능 향상에 기여한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.