[논문 리뷰] T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
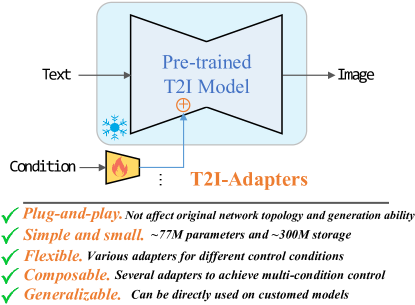
이 논문은 외부 제어 신호를 사전 학습된 텍스트-투-이미지 확산 모델과 정렬시키는 경량 모듈인 T2I-Adapters를 도입하여 기본 모델 재학습 없이 보다 정교한 제어를 달성한다.
The incredible generative ability of large-scale text-to-image (T2I) models has demonstrated strong power of learning complex structures and meaningful semantics. However, relying solely on text prompts cannot fully take advantage of the knowledge learned by the model, especially when flexible and accurate controlling (e.g., color and structure) is needed. In this paper, we aim to ``dig out" the capabilities that T2I models have implicitly learned, and then explicitly use them to control the generation more granularly. Specifically, we propose to learn simple and lightweight T2I-Adapters to align internal knowledge in T2I models with external control signals, while freezing the original large T2I models. In this way, we can train various adapters according to different conditions, achieving rich control and editing effects in the color and structure of the generation results. Further, the proposed T2I-Adapters have attractive properties of practical value, such as composability and generalization ability. Extensive experiments demonstrate that our T2I-Adapter has promising generation quality and a wide range of applications.
연구 동기 및 목표
- 작은 어댑터가 T2I 모델의 내부 지식을 드러내고 이를 이용해 제어 가능성을 향상시킬 수 있음을 보여준다.
- 베이스 확산 모델의 재학습 없이 색상, 구조 등의 유연하고 조합 가능하며 일반화된 제어 신호를 가능하게 한다.
- 적은 데이터 및 계산으로 어댑터를 학습하고 플러그-앤-플레이 방식으로 삽입할 수 있음을 보여준다.
제안 방법
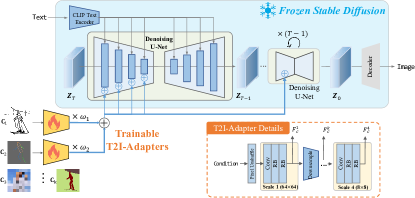
- 다중 스케일 특징 추출을 갖춘 경량의 T2I-Adapter 아키텍처를 도입하고, 조건 특징을 SD UNet의 인코더에 주입한다.
- Stable Diffusion 모델을 동결한 채 어댑터를 학습시키고, 어댑터 가이던스와 확산 디노이징을 정렬하는 손실(L_AD)을 최적화한다.
- 가중치를 조정 가능한 어댑터를 조합하여 다중 조건 제어를 지원한다(Eq. 5).
- 학습 중 비균일(세제곱) 시간 스텝 샘플링을 사용하여 가이던스가 가장 중요한 초기 추론 단계를 강조한다.
- 공간 색상 맵을 통해 다양한 제어 신호(스케치, 세그먼테이션, 깊이, 키포즈) 및 색 팔레트와의 호환성을 입증한다.
실험 결과
연구 질문
- RQ1경량 어댑터가 외부 제어 신호를 사전 학습된 T2I 확산 모델의 내부 지식과 정렬하여 더 정교한 제어를 달성할 수 있는가?
- RQ2어댑터가 원래의 확산 모델을 수정하지 않고도 조합 가능하고 다중 조건이며 일반화 가능한 제어를 가능하게 하는가?
- RQ3생성 품질과 제어 가능성에 대한 어댑터 배치 및 학습 전략의 영향은 어떤가?
주요 결과
- 어댑터는 기본 모델의 생성 능력을 바꾸지 않고도 제어 가능한 가이던스를 달성한다.
- 해당 방법은 COCO 검증에서 기준선 대비 FID/CLIP 점수에서 경쟁력 있거나 향상된 성능을 보인다.
- 다중 조건 어댑터를 조합하여 깊이 + 키포즈, 스케치 + 색상 등 결합 제어를 실현할 수 있다.
- 어댑터는 SD 버전(SD-v1.4에서 SD-v1.5) 간 일반화되며 동일한 기반에서 미세 조정된 커스텀 모델에도 적용된다.
- 세제곱 시간 스텝 샘플링으로 학습하면 색상 및 구조 가이던스가 강화된다.
- 매개변수 수가 감소한 소형 어댑터 버전에서도 효과적인 제어를 유지한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.