[논문 리뷰] Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
Tag-LLM은 도메인 입력 태그와 기능 입력 태그를 학습 가능한 임베딩으로 도입하여 일반 LLM을 특수 도메인에 적응시키고 제로샷 일반화와 NLP 번역 및 단백질/ SMILES 특성 예측 및 약물-표적 결합 친화도와 같은 비언어적 태스크에서 경쟁력 있거나 우수한 성능을 가능하게 한다.
Large Language Models (LLMs) have demonstrated remarkable proficiency in understanding and generating natural language. However, their capabilities wane in highly specialized domains underrepresented in the pretraining corpus, such as physical and biomedical sciences. This work explores how to repurpose general LLMs into effective task solvers for specialized domains. We introduce a novel, model-agnostic framework for learning custom input tags, which are parameterized as continuous vectors appended to the LLM's embedding layer, to condition the LLM. We design two types of input tags: domain tags are used to delimit specialized representations (e.g., chemical formulas) and provide domain-relevant context; function tags are used to represent specific functions (e.g., predicting molecular properties) and compress function-solving instructions. We develop a three-stage protocol to learn these tags using auxiliary data and domain knowledge. By explicitly disentangling task domains from task functions, our method enables zero-shot generalization to unseen problems through diverse combinations of the input tags. It also boosts LLM's performance in various specialized domains, such as predicting protein or chemical properties and modeling drug-target interactions, outperforming expert models tailored to these tasks.
연구 동기 및 목표
- 일반 목적 LLM이 특수 도메인에서 성능이 떨어지는 이유를 제시하고, 전체 미세조정 없이 LLM을 조건화하기 위한 재사용 가능한 태깅 프레임워크를 제안한다.
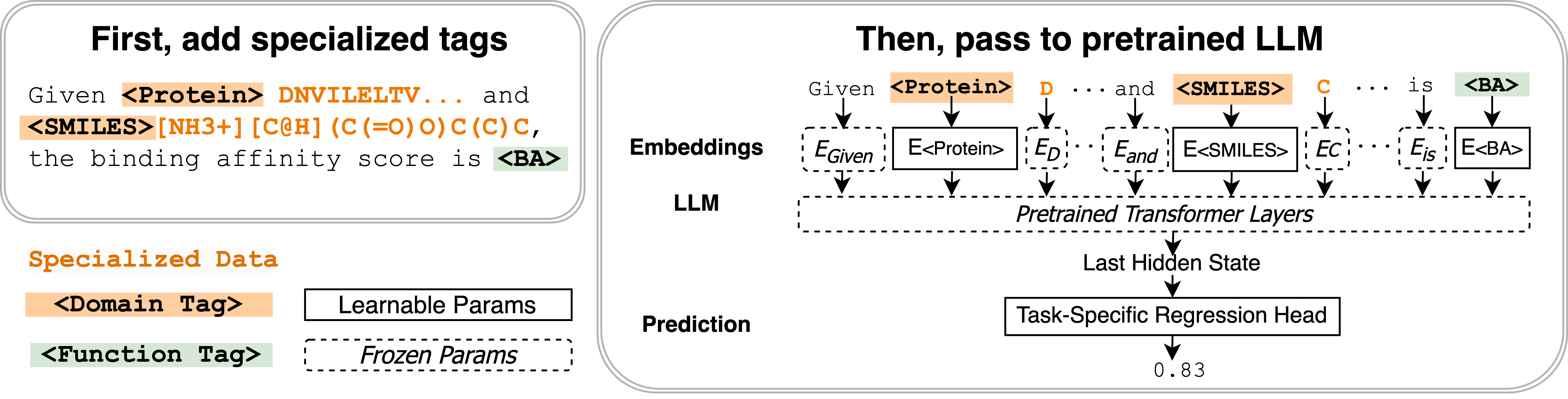
- LLM 입력에 임베딩으로 매개변수화된 두 가지 유형의 학습 가능 입력 태그(도메인 태그와 기능 태그)를 도입한다.
- 보조 도메인 데이터 및 도메인 지식을 활용하여 도메인 태그와 기능 태그를 학습하기 위한 세 단계 학습 프로토콜을 개발한다.
- 다언어 번역 및 비언어적 태스크(단백질, SMILES, 신약 발견)에 대해 제로샷 일반화 및 경쟁력 있는 성능을 시연한다.
- Tag-LLM의 모델 무관성 및 플러그-앤-플레이 특성 및 새로운 도메인과 태스크에 대한 확장성을 강조한다.
제안 방법
- 두 가지 태그 유형을 정의한다: 도메인 태그는 도메인별 데이터를 구분하고 도메인 수준 정보를 인코딩하며, 기능 태그는 태스크 의미를 인코딩하고 도메인 간에 공유될 수 있다.
- 각 태그를 학습 가능한 p-by-d 임베딩 행렬로 표현하여 LLM 임베딩 공간에 추가하고, 어휘 전체에서 평균 토큰 임베딩으로 초기화한다.
- 세 단계 학습 프로토콜: (Stage 1) unlabeled in-domain data에서 다음 토큰 예측을 통해 도메인 태그를 학습; (Stage 2) 입력에 도메인 태그를 포함시켜 라벨 데이터로 단일 도메인 기능 태그를 학습; (Stage 3) 여러 도메인 태그를 가진 교차 도메인 기능 태그를 학습하여 공유 능력을 학습.
- 비텍스트 출력에 대한 회귀 헤드를 사용해 기능 태그를 확장하여 수치 예측 태스크를 개선한다.
- 점진적 태그 추가와 구성적 문제 해결을 가능하게 하는 모듈식의 계층적 태깅 프레임워크를 채택한다.
실험 결과
연구 질문
- RQ1학습 가능한 입력 태그의 모듈식 집합이 보지 못한 도메인-태스크 조합에 대한 제로샷 일반화를 가능하게 할 수 있는가?
- RQ2도메인 태그와 기능 태그가 도메인 지식과 작업 지시를 분리하여 표준 프롬프트 튜닝보다 성능을 향상시키는가?
- RQ3도메인 특화 또는 일반 기준선과 비교하여 Tag-LLM이 다국어 번역 및 비언어적 과학 태스크(단백질, SMILES, 신약 발견)에서 어떻게 수행하는가?
- RQ4태그 길이, 강화, 회귀 헤드 포함이 예측 정확도에 미치는 영향은 무엇인가?
- RQ5적은 양의 라벨 데이터로 새로운 도메인과 태스크에 확장될 수 있는 모델-무관 tagging 프레임워크가 가능한가?
주요 결과
- 도메인 태그는 특수 데이터에 대한 효과적인 컨텍스트 스위처로 작용한다.
- 하나의 공유 기능 태그가 여러 도메인을 지원하여 다양한 태스크를 다룰 수 있다.
- Tag-LLM은 보인 도메인과 보지 못한 도메인-태스크 조합에서도 경쟁력 있는 다국어 번역 성능을 달성한다.
- Tag-LLM은 다수의 신약 발견 데이터셋에서 최첨단 결과를 달성하고 종종 기본 PEFT 방법보다 우수하다.
- 도메인 태그를 작업 관련 지식으로 보강하면 성능이 향상되고; 회귀 헤드는 비텍스트 출력 및 수치 예측에 도움을 준다.
- 이 접근법은 도메인 태그와 기능 태그의 조합을 통해 보지 못한 문제에 대한 제로샷 일반화를 보여준다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.