[논문 리뷰] TD-MPC2: Scalable, Robust World Models for Continuous Control
TD-MPC2는 TD-MPC를 견고성 및 확장성 개선으로 확장하여 단일 하이퍼파라미터 세트로 104개의 연속 제어 태스크에서 강력한 성능을 달성하고, 다중 작업 학습을 위해 월드 모델을 최대 317M 파라미터까지 확장합니다.
TD-MPC is a model-based reinforcement learning (RL) algorithm that performs local trajectory optimization in the latent space of a learned implicit (decoder-free) world model. In this work, we present TD-MPC2: a series of improvements upon the TD-MPC algorithm. We demonstrate that TD-MPC2 improves significantly over baselines across 104 online RL tasks spanning 4 diverse task domains, achieving consistently strong results with a single set of hyperparameters. We further show that agent capabilities increase with model and data size, and successfully train a single 317M parameter agent to perform 80 tasks across multiple task domains, embodiments, and action spaces. We conclude with an account of lessons, opportunities, and risks associated with large TD-MPC2 agents. Explore videos, models, data, code, and more at https://tdmpc2.com
연구 동기 및 목표
- 크고 다듬어지지 않은 다중태스크 데이터 세트를 활용할 수 있는 견고하고 일반화 가능한 모델 기반 RL의 동기를 부여합니다.
- 작업 특화 조정 없이 다양한 구현체와 행동 공간에서 작동하는 확장 가능한 월드 모델 아키텍처를 개발합니다.
- 더 큰 모델과 데이터 세트가 다중 작업 설정에서 점진적으로 더 나은 능력을 제공한다는 것을 보여줍니다.
- 더 넓은 채택과 재현성을 촉진하기 위해 오픈 리소스(모델, 데이터, 코드)를 제공합니다.
제안 방법
- 액션 시퀀스에 조건화된 결과를 예측하는 암시적이고 디코더 없는 월드 모델을 학습합니다.
- 관측치를 디코딩하지 않고 공동 임베딩 예측, 보상 예측, TD-학습을 사용하여 월드 모델을 학습합니다.
- 훈련 안정화를 위해 보상 및 가치 타깃을 로그 변환 공간에서 이산 회귀(크로스 엔트로피) 형태로 사용합니다.
- TD 타깃의 편향을 줄이기 위해 Q-함수 앙상블을 학습하고 EMA 타깃을 사용합니다.
- 찾기를 가이드하기 위해 정책 사전 정보를 갖춘 상태에서 모델 예측 경로 적분(MPPI)을 이용한 모델 예측 제어로 계획하고, 학습된 종말 값을 통해 부트스트랩합니다.
- 다중 작업 설정에서 모든 구성요소를 조건화하기 위한 고정 차원의 정규화된 작업 임베딩을 학습하고, 가변 관찰/행동 공간을 다루기 위해 액션 마스킹을 사용합니다.
실험 결과
연구 질문
- RQ1TD-MPC2가 데이터 효율적인 연속 제어 태스크에서 최첨단 모델 프리 및 모델 기반 방법과 어떻게 비교되는가?
- RQ2TD-MPC2의 알고리즘적 혁신이 단일 하이퍼파라미터 세트를 사용하여 다양한 태스크에 걸쳐 견고한 성능을 제공할 수 있는가?
- RQ3더 큰 모델과 더 많은 데이터가 대규모 다중 작업 TD-MPC2 에이전트의 능력을 개선하며, 하나의 에이전트가 도메인 전반에 걸쳐 많은 작업을 수행할 수 있는가?
- RQ4설계 선택(정규화, 회귀 목표, Q-함수 수)의 성능에 대한 영향은 무엇이며, 계획은 얼마나 중요한가?
- RQ5학습된 작업 임베딩이 의미론적으로 의미가 있고, 대규모 다중 작업 에이전트가 보지 않은 작업에 적응할 수 있는가?
주요 결과
- TD-MPC2는 한 개의 하이퍼파라미터 세트를 사용하여 104개 태스크에서 강력한 기준값(SAC, DreamerV3, 원래 TD-MPC)을 능가합니다.
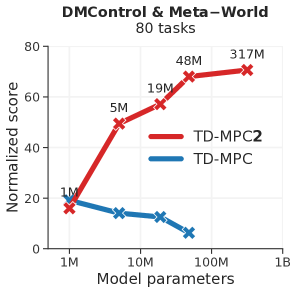
- 모델 및 데이터 크기가 커질수록 에이전트의 능력이 향상되며, 317M 파라미터 월드 모델은 도메인 전반에 걸쳐 80개의 태스크를 달성합니다.
- 다중 작업 TD-MPC2 모델은 작업 임베딩이 역학/객체 상호 작용에 따라 군집화되며, 더 큰 모델이 명확한 포화 없이 지속적으로 개선됨을 보여줍니다.
- TD-MPC2는 이전 방법이 발산하던 어려운 작업에서도 안정성을 유지하고, 계획이 성능에 상당한 기여를 합니다.
- 학습 비용은 모델 규모에 따라 증가하며, 예를 들어 317M 파라미터 모델은 약 33 GPU일로 학습되어 80-태스크 데이터셋에서 약 70.6의 정규화 점수를 달성했습니다.
- TD-MPC2는 보류된 작업에서 소수 샷 학습을 위한 미세 조정을 가능하게 하며, 낮은 데이터 상황에서 무에서 시작하는 것 대비 약 2배의 개선을 보여줍니다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.