[논문 리뷰] TDN: Temporal Difference Networks for Efficient Action Recognition
이 논문은 시간 차분 모듈(TDM)을 사용하여 다중 척도 운동 패턴을 캡처하는 경량이고 효율적인 비디오 동작 인식 프레임워크인 시간 차분 네트워크(TDN)를 제안한다. 국소적(연속 프레임) 및 전역적(세그먼트 수준) 척도에서 시간 차분을 적용함으로써, 최소한의 계산 부담으로도 동작 인식 정확도를 향상시켜 Something-Something V1/V2에서 새로운 최고 성능을 달성하고, Kinetics-400에서는 경쟁력 있는 성능을 보였다.
Temporal modeling still remains challenging for action recognition in videos. To mitigate this issue, this paper presents a new video architecture, termed as Temporal Difference Network (TDN), with a focus on capturing multi-scale temporal information for efficient action recognition. The core of our TDN is to devise an efficient temporal module (TDM) by explicitly leveraging a temporal difference operator, and systematically assess its effect on short-term and long-term motion modeling. To fully capture temporal information over the entire video, our TDN is established with a two-level difference modeling paradigm. Specifically, for local motion modeling, temporal difference over consecutive frames is used to supply 2D CNNs with finer motion pattern, while for global motion modeling, temporal difference across segments is incorporated to capture long-range structure for motion feature excitation. TDN provides a simple and principled temporal modeling framework and could be instantiated with the existing CNNs at a small extra computational cost. Our TDN presents a new state of the art on the Something-Something V1 & V2 datasets and is on par with the best performance on the Kinetics-400 dataset. In addition, we conduct in-depth ablation studies and plot the visualization results of our TDN, hopefully providing insightful analysis on temporal difference modeling. We release the code at https://github.com/MCG-NJU/TDN.
연구 동기 및 목표
- 비디오 동작 인식에서 효율적이고 효과적인 시간 모델링에 도전하는 것.
- 광학 흐름이나 고비용 3D 컨볼루션에 의존하지 않고, 시간 차분을 통해 외형과 운동을 동시에 캡처할 수 있는 통합형 엔드 투 엔드 훈련 가능한 프레임워크를 설계하는 것.
- 이중 수준의 차분 모델링 파라다임을 통해 단기 및 장기 운동 모델링을 체계적으로 연구하는 것.
- 표준 2D CNN에 경량 시간 차분 모듈을 통합하여 낮은 계산 비용으로 높은 정확도를 달성하는 것.
- 제거 및 시각화 연구를 통해 시간 차분 기반 운동 모델링에 대한 통찰을 제공하는 것.
제안 방법
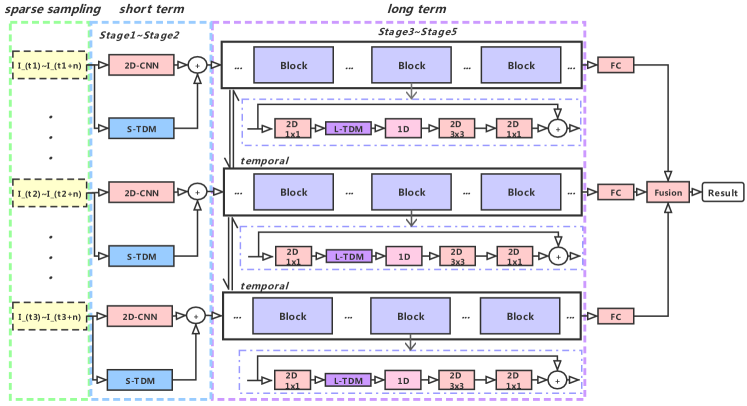
- 연속 프레임 간의 차분을 계산하여 미세한 운동 패턴을 추출하는 국소적 모델링을 위한 시간 차분 모듈(TDM)을 도입한다.
- 세그먼트 전역에서 다중 척도 및 양방향 차분 모듈을 활용하여 장거리 시간적 구조를 캡처하고 전역적 운동 자극을 달성한다.
- 국소적 차분(프레임 수준 운동)과 전역적 차분(세그먼트 수준 운동)을 결합한 이중 수준 차분 모델링 전략을 적용한다.
- 시간 차분 특징을 2D CNN에 주입하기 위해 횡방향 연결을 적용하여 최소한의 파rameter 증가로 엔드 투 엔드 훈련을 가능하게 한다.
- 전체적 및 희소 샘플링을 활용하여 비디오 전반에서 효율적으로 시간 정보를 추출한다.
- Grad-CAM을 활용하여 TDM의 주의 메커니즘을 분석하고 검증한다.
![Figure 1: Video classification performance comparison on Something-Something V1 [ 8 ] in terms of Top1 accuracy, computational cost, and model size. Our proposed TDN achieves the best trade-off between accuracy and efficiency, when compared with previous methods such as NL I3D [ 40 ] , ECO [ 46 ] ,](https://ar5iv.labs.arxiv.org/html/2012.10071/assets/x1.png)
실험 결과
연구 질문
- RQ1시간 차분 연산이 비디오 인식에서 광학 흐름이나 3D 컨볼루션을 효과적으로 대체할 수 있는가?
- RQ2국소적 시간 차분 모델링과 전역적 시간 차분 모델링이 동작 인식 성능에 미치는 영향은 어떠한가?
- RQ3이중 수준 차분 모델링 프레임워크가 다중 척도 운동 패턴을 캡처하는 데 기여하는 바는 무엇인가?
- RQ4TDM이 특징 활성화 맵과 모델 해석 가능성에 미치는 영향은 무엇인가?
- RQ5기존 최고 성능 기법들과 비교해 TDN의 계산 효율성은 어떠한가?
주요 결과
- TDN은 UCF101에서 97.4%의 최고 Top-1 정확도와 HMDB51에서 76.3%의 정확도를 기록하여 TSM, I3D, S3D와 같은 이전 방법들을 능가했다.
- Something-Something V1 데이터셋에서 TDN은 정확도와 효율성 간 최적의 균형을 달성하여 NL I3D, ECO, TSM 등의 방법들을 능가했다.
- Tesla V100에서 1개 비디오당 22.1ms(약 45.2 FPS)로 실행되어, 일부 기준보다는 높은 지연 시간을 가짐에도 불구하고 실시간 추론을 달성했다.
- 제거 연구 결과 시간 차분 연산이 성능 향상에 크게 기여하며, S-TDM와 L-TDM가 국소 및 전역 운동 모델링에 기여하는 것으로 확인되었다.
- Grad-CAM을 통한 시각화 결과 TDN에 TDM가 적용된 경우 기준 모델보다 더 많은 운동 관련 영역에 집중하는 것으로 나타나, 향상된 특징 학습이 이루어졌음을 시사한다.
- 이 방법은 일반화 능력이 뛰어나 Kinetics-400에서 작은 데이터셋인 UCF101과 HMDB51로의 전이가 효과적으로 이루어졌으며, 운동이 많은 HMDB51에서 두드러진 성능 향상을 보였다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.