[논문 리뷰] Tensor Network Quantum Simulator With Step-Dependent Parallelization
이 논문은 단계에 따라 병렬화되는 텐서 네트워크 양자 시뮬레이터를 제안하며, 이는 현재까지 가장 대규모의 QAOA 회로 시뮬레이션—1,024개 노드의 Theta 슈퍼컴퓨터에서 210 큐비트, 1,785 게이트—을 가능하게 한다. 이 방법은 단계에 따라 변수를 선택하는 새로운 슬라이싱 알고리즘을 사용하여 수축 폭과 메모리 사용량을 줄이며, 비병렬화된 접근 방식 대비 최대 512배의 속도 향상을 달성하면서도 여러 시뮬레이션에 걸쳐 높은 효율성을 유지한다.
In this work, we present a new large-scale quantum circuit simulator. It is based on the tensor network contraction technique to represent quantum circuits. We propose a novel parallelization algorithm based on \stepslice . In this paper, we push the requirement on the size of a quantum computer that will be needed to demonstrate the advantage of quantum computation with Quantum Approximate Optimization Algorithm (QAOA). We computed 210 qubit QAOA circuits with 1,785 gates on 1,024 nodes of the the Cray XC 40 supercomputer Theta. To the best of our knowledge, this constitutes the largest QAOA quantum circuit simulations reported to this date.
연구 동기 및 목표
- 대규모 양자 회로, 특히 QAOA의 고전적 시뮬레이션의 한계를 극복하여 양자 우월성의 임계점을 정의한다.
- 텐서 네트워크 수축을 사용한 깊은 양자 회로 시뮬레이션의 높은 메모리 및 계산 비용 문제를 해결한다.
- 텐서 네트워크 시뮬레이션에서 수축 폭과 메모리 사용량을 줄이는 스케일러블하고 고성능의 병렬화 전략을 개발한다.
- 최적화 및 분석을 위해 여러 QAOA 파라미터 변형에 걸쳐 수축 순서를 효율적으로 재사용할 수 있도록 한다.
제안 방법
- 시뮬레이터는 양자 회로를 텐서 네트워크로 표현하고, 수축 순서 생성에 버킷 제거 알고리즘을 사용한다.
- 단계에 따라 변수를 선택하는 새로운 슬라이싱 알고리즘이 현재 수축 단계에 따라 슬라이싱 변수를 동적으로 선택하여 최대 수축 폭을 줄인다.
- 이 방법은 수축 세그먼트를 사전에 수축시켜 식을 더 작은 부분으로 나누어 반복적인 제거 순서 계산의 필요성을 최소화한다.
- 알고리즘은 분산 시스템(Theta 슈퍼컴퓨터)에 구현되었으며, 최대 1,024개의 노드와 213 TB의 메모리를 사용한다.
- 동일한 수축 순서를 재사용함으로써 여러 진폭의 효율적 시뮬레이션을 가능하게 하며 최소한의 오버헤드를 제공한다.
- 성능는 다양한 수의 병렬 인덱스에 걸쳐 최대 수축 폭을 최소화하도록 슬라이싱 전략을 최적화하였다.
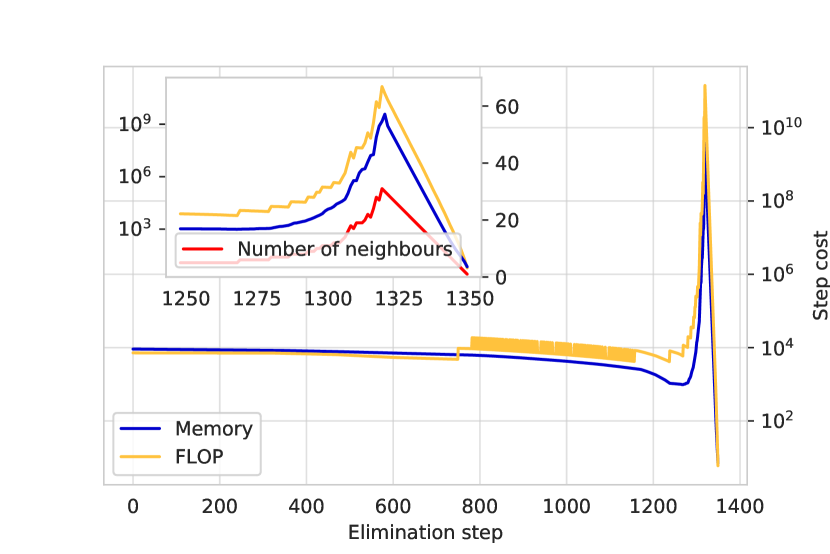
실험 결과
연구 질문
- RQ1단계에 따라 변하는 슬라이싱은 대규모 텐서 네트워크 시뮬레이션에서 수축 폭과 메모리 사용량을 크게 줄일 수 있는가?
- RQ2고도로 발전한 병렬화를 사용한 텐서 네트워크 수축을 통해 QAOA 회로에서 도달할 수 있는 최대 큐비트 수는 얼마인가?
- RQ3속도 향상과 메모리 효율성 측면에서 단계에 따라 변하는 슬라이싱은 표준 병렬화 방법보다 성능가능성이 높은가?
- RQ4다른 QAOA 파라미터 세트에 걸쳐 단일 수축 순서를 얼마나 효율적으로 재사용할 수 있는가?
- RQ5병렬 인덱스 수를 늘릴 경우 최소 수축 폭과 전체 시뮬레이션 시간에 어떤 영향을 미치는가?
주요 결과
- 시뮬레이터는 1,785개의 게이트를 가진 210 큐비트 QAOA 앤사츠 상태를 성공적으로 시뮬레이션하여 현재까지 가장 대규모의 QAOA 회로 시뮬레이션 기록을 수립했다.
- Theta 슈퍼컴퓨터의 1,024개 노드를 사용하여 64노드 실행 대비 시간을 3배로 단축했으며, 수축 폭은 29로 감소시켰다.
- 단계에 따라 변하는 슬라이싱 알고리즘이 비병렬화된 수축 단계 대비 최대 512배의 속도 향상을 달성했으며, 간단한 병렬화의 이론적 한계인 64배를 초월했다.
- 누적 메모리 사용량은 64노드에서 이용 가능한 13TB의 60%로 줄었으며, 이는 순차적 접근 방식 대비 35배 이상의 메모리 절감을 의미한다.
- 슬라이싱 인덱스 수가 증가할수록 최소 수축 폭이 매번 1씩 감소하여 예측 가능하고 스케일러블한 성능 향상을 입증했다.
- 알고리즘은 다양한 QAOA 파라미터 세트 간 수축 순서의 효율적 재사용을 가능하게 하여 대규모 파rameter 최적화 및 각도 이식 가능성 연구를 지원한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.