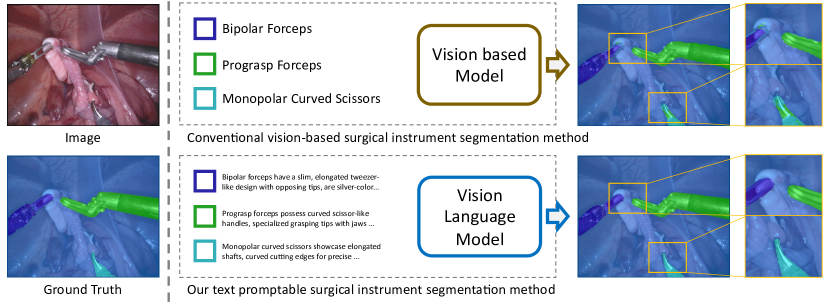
[논문 리뷰] Text Promptable Surgical Instrument Segmentation with Vision-Language Models
CLIP 기반의 이미지 및 텍스트 인코더와 텍스트 프롬프트 가능한 마스크 디코더, 프롬프트 혼합 메커니즘, 그리고 하드 영역 강화 모듈을 활용하여 수술 도구 유형에 걸친 세분화를 개선하고 새로운 범주에 일반화하는 텍스트 프롬프트 가능한 수술 도구 세분화 프레임워크를 제안한다.
In this paper, we propose a novel text promptable surgical instrument segmentation approach to overcome challenges associated with diversity and differentiation of surgical instruments in minimally invasive surgeries. We redefine the task as text promptable, thereby enabling a more nuanced comprehension of surgical instruments and adaptability to new instrument types. Inspired by recent advancements in vision-language models, we leverage pretrained image and text encoders as our model backbone and design a text promptable mask decoder consisting of attention- and convolution-based prompting schemes for surgical instrument segmentation prediction. Our model leverages multiple text prompts for each surgical instrument through a new mixture of prompts mechanism, resulting in enhanced segmentation performance. Additionally, we introduce a hard instrument area reinforcement module to improve image feature comprehension and segmentation precision. Extensive experiments on several surgical instrument segmentation datasets demonstrate our model's superior performance and promising generalization capability. To our knowledge, this is the first implementation of a promptable approach to surgical instrument segmentation, offering significant potential for practical application in the field of robotic-assisted surgery. Code is available at https://github.com/franciszzj/TP-SIS.
연구 동기 및 목표
- 레이블 재지정 및 재학습 없이 새로운 다양하고 다양한 수술 도구 유형에 대한 세분화의 일반화 한계를 해결한다.
- 시각-언어 사전학습을 활용해 이미지 영역을 텍스트 도구 프롬프트와 정렬하여 유연한 개방형 세분화를 달성한다.
- 주의 기반 및 컨볼루션 기반 프롬프팅으로 텍스트 프롬프트 가능한 마스크 디코더를 개발해 수술 도구의 위치 추정정을 점진적으로 정제한다.
- 다양한 변이에 대해 강건한 세분화를 위해 다중 텍스트 프롬프트를 융합하는 프롬프트 혼합 메커니즘(MoP)을 도입한다.
- MAE 유사 재구성 목적을 통합한 하드 도구 영역 강화 모듈을 통해 어려운 영역에서 특징 학습을 강화한다.
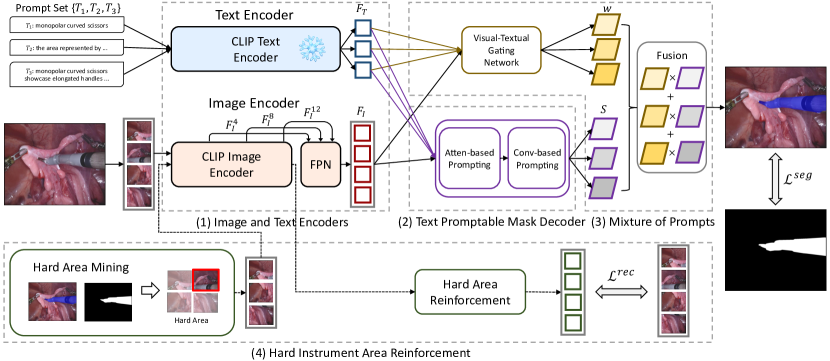
제안 방법
- CLIP 이미지 및 텍스트 인코더를 백본으로 사용하여 내시경 이미지와 도구 설명에서 시각적 및 텍스트 특징을 추출한다.
- 두 가지 프롬프트 스킴으로 텍스트 프롬프트 가능한 마스크 디코더를 구현한다: 주의 기반 프롬프팅(F_T와의 자기 주의 및 교차 주의) 및 컨볼루션 기반 프롬프팅(F_T에서 유도된 동적 커널 파라미터).
- 다중 프롬프트를 시각-텍스트 게이팅 네트워크와 함께 도입해 프롬프트로 유도된 여러 점수 맵을 픽셀 단위로 융합한다.
- 어려운 영역을 탐지하고 MAE 유사 재구성 목적을 적용해 어려운 영역의 특징 학습을 강화하는 하드 도구 영역 강화 모듈을 도입한다.
- 세분화 손실(바이너리 크로스엔트로피) 및 MAE 기반 모듈의 재구성 손실(L2)로 학습하고, 텍스트 인코더를 고정하고 이미지 인코더를 미세조정한다.
실험 결과
연구 질문
- RQ1레이블 재지정이나 재학습 없이 미지의 수술 도구 유형에 대해 텍스트-프롬프트 가능 세분화 프레임워크가 일반화될 수 있는가?
- RQ2시각-텍스트 게이팅 네트워크를 통한 다중 텍스트 프롬프트 융합이 도구 범주 간 세분화 정확도를 향상시키는가?
- RQ3어려운 수술 현장에서 경계 정밀도와 범주 구분을 개선하는가?
- RQ4다중 스케일 이미지 특징 융합과 텍스트 가이드가 EndoVis 데이터셋의 세분화 성능에 어떤 영향을 미치는가?
주요 결과
- EndoVis2017 및 EndoVis2018 데이터셋에서 최첨단 성능을 달성하며 전통적인 사전 정의 범주 방법 및 다른 텍스트 프롬프트 가능 방법들을 능가한다.
- EndoVis2017에서 Our(896)은 Ch_IoU 79.90, ISI_IoU 77.83, mc_IoU 56.22로 prior 방법들을 상회한다.
- EndoVis2018에서 Our(896)은 Ch_IoU 84.92, ISI_IoU 83.61, mc_IoU 65.44로 강한 교차 데이터셋 일반화를 나타낸다.
- 교차 데이터셋(EndoVis2018에서 학습하고 EndoVis2017에서 테스트)은 개방형 도구 범주에 대한 일반화를 시사하는 경쟁력 있는 결과를 낳는다.
- 다중 스케일 특징 증강, CLS 기반 텍스트 특징, 주의-컨볼루션 프롬프팅의 조합이 성능을 크게 향상시킨다는 추론 연구가 나타난다.
- MoP 프레임워크 내 GPT-4 생성 프롬프트가 프롏프트 유형 중 최적의 이득을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.