[논문 리뷰] Textbooks Are All You Need
저자들은 작은 고품질 데이터 혼합(CodeTextbook와 CodeExercises)을 사용하여 1.3B 파라미터의 코드 모델 phi-1을 훈련시키고, 인간 평가(HumanEval)와 MBPP에서 pass@1 점수를 포함한 강력한 코드 생성 성능을 이전 모델들보다 데이터와 계산량이 크게 적은 상태에서 보여준다.
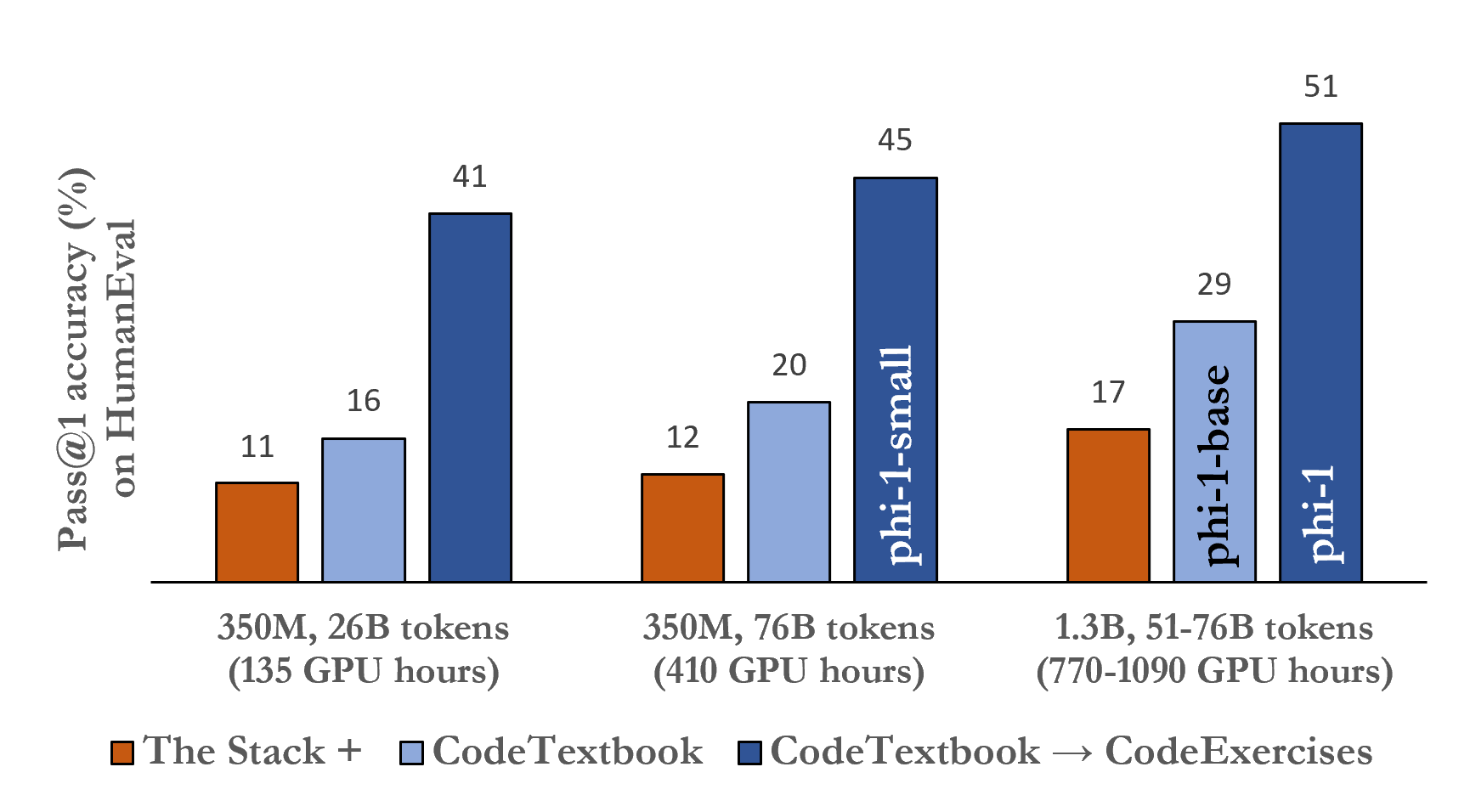
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
연구 동기 및 목표
- 고품질의 교과서 스타일 데이터가 소규모 규모에서 코드-언어 모델의 성능을 크게 향상시킬 수 있는지 조사한다.
- 1.3B 파라미터의 트랜스포머가 제한된 학습 데이터와 계산으로도 경쟁력 있거나 최첨단 결과를 달성할 수 있는지 보여준다.
- 코딩 연습에 대해 표적화된 미세조정에서 emergent 능력과 비지역적 이점이 어떻게 나타나는지 보여준다.
- 합성 데이터셋으로 훈련된 코드 모델의 평가에서 데이터 선별, 필터링, 데이터 오염 가능성에 대해 조사한다.
제안 방법
- CodeTextbook 프리트레이닝 혼합(필터링된 The Stack/StackOverflow 코드 + 합성 교재)으로 50B 토큰 정도를 사용하는 1.3B 매개변수의 디코더-전용 트랜스포머(phi-1)를 훈련한다.
- 동일한 하드웨어 및 학습 설정에서 하이퍼파라미터를 조정하여 작은 CodeExercises 데이터셋(~180M 토큰)으로 phi-1-base을 미세조정하여 phi-1을 얻고, 같은 구성으로 미세조정한다.
- HumanEval과 MBPP에서 pass@1을 사용하여 phi-1과 더 큰 알려진 모델들을 비교하고, emergent 능력과 phi-1-base 및 phi-1-small 간의 차이를 분석한다.
- GPT-4 주석 달기와 트랜스포머 기반 분류기를 이용한 데이터 필터링의 조합으로 고품질의 교육용 코드 샘플을 선별하고 사전 학습 및 미세조정을 위해 GPT-3.5로 교과서와 연습 문제를 합성한다.
- GPT-4로 채점되는 비전형적인 문제 집합과 데이터-프 pruning 실험을 통해 데이터 오염 우려에 대한 강건성을 평가한다.
- 아키텍처, 학습 설정(fp16, AdamW, 선형 워밍업-디케이, 8x A100, Deepspeed) 및 데이터셋 구성(CodeTextbook, CodeExercises)을 보고한다.
실험 결과
연구 질문
- RQ1고품질의 교과서 스타일 데이터가 대규모 학습 데이터와 계산 자원을 대체해 강력한 코드 생성 성능을 달성할 수 있는가?
- RQ2:
- RQ3미세조정이 코드 과제 외의 작업에 미치는 영향( emergent capabilities )은 CodeExercises와 같은 작고 집중된 데이터셋에서 어떻게 나타나는가?
- RQ4데이터 선별 및 합성 데이터 생성 전략이 LLM에 프로그래밍 개념을 가르치는 데 일반 코드 코퍼스보다 의미 있게 우수한가?
- RQ5훈련 데이터에서 평가 벤치마크로의 데이터 오염이나 누수 가능성에 결과가 얼마나 강건한가?
- RQ6HumanEval과 MBPP에서 phi-1과 더 큰 벤치마크들의 비교 강점과 한계는 무엇인가?
주요 결과
- phi-1(1.3B 매개변수)은 CodeExercises로 미세조정한 후 HumanEval에서 50.6% pass@1, MBPP에서 55.5% pass@1를 달성한다.
- 미세조정 없이, CodeTextbook으로 학습된 phi-1-base은 HumanEval에서 29%를 달성하고, phi-1-small(350M)은 같은 파이프라인으로 약 45%의 HumanEval를 달성한다.
- phi-1은 훨씬 더 큰 모델들보다 HumanEval과 MBPP에서 우수한 성능을 보이나, GPT-4는 일부 경우에서 상한값으로 남아 있다.
- CodeExercises에 대한 미세조정은 큰 성능 향상을 가져오고 다른 코딩 과제 및 라이브러리 사용(e.g., Pygame, Tkinter)에서도 예상치 못한 개선을 보여준다.
- 데이터 품질 중심의 사전 학습(CodeTextbook)과 타깃 미세조정(CodeExercises)은 작은 규모에서도 강력한 성과를 달성함으로써 전통적 규모의 법칙을 깨뜨릴 수 있다.
- GPT-4 채점 및 데이터 pruning 실험은 phi-1의 성능의 강건성을 뒷받침하고 데이터 오염에 대한 우려를 완화한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.