[논문 리뷰] The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
FineWeb은 96 Common Crawl 스냅샷에서 파생된 15-trillion-token 오픈 프리트레이닝 데이터 세트이며, 교육용 하위 집합 FineWeb-Edu의 1.3 trillion tokens; 저자들은 엔드투엔드 큐레이션 및 ablation 연구를 통해 강력한 오픈 데이터 성능을 달성했다.
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
연구 동기 및 목표
- 오픈 LLM을 위한 공개적으로 문서화된 고품질 프리트레이닝 데이터의 필요성을 동기부여한다.
- 투명한 큐레이션 파이프라인을 갖춘 대규모 웹 텍스트 데이터 세트(FineWeb)를 개발하고 공개한다.
- 필터링, 중복 제거 및 텍스트 추출 선택을 체계적으로 ablate하고 문서화하여 다운스트림 성능에 대한 영향을 이해한다.
- 지식 및 추론이 강한 콘텐츠를 선별하기 위해 합성 주석을 사용한 교육용 하위집합(FineWeb-Edu)을 생성한다.
- 재현성 및 추가 연구를 지원하기 위해 도구(datatrove)와 학습된 모델을 제공한다.
제안 방법
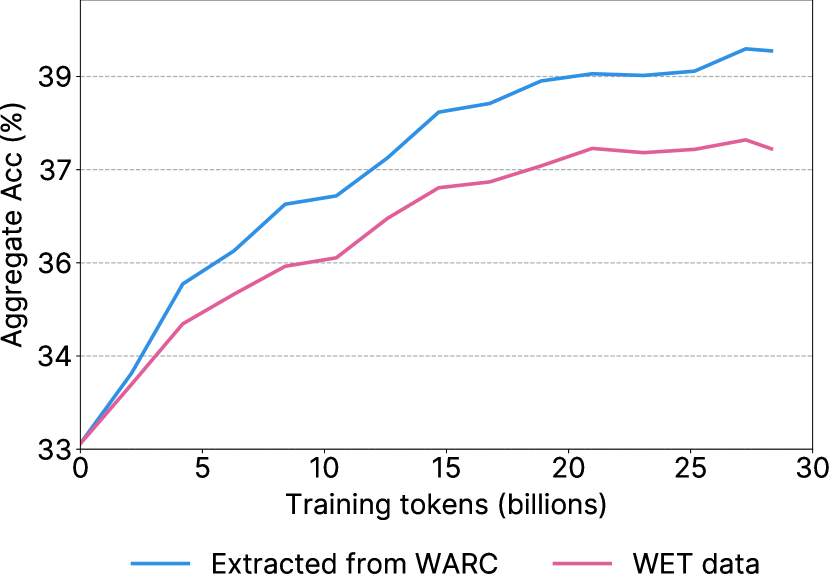
- WARC 파일에서 Trafilatura 라이브러리를 사용하여 WET 기반 추출보다 더 높은 품질의 텍스트를 추출한다.
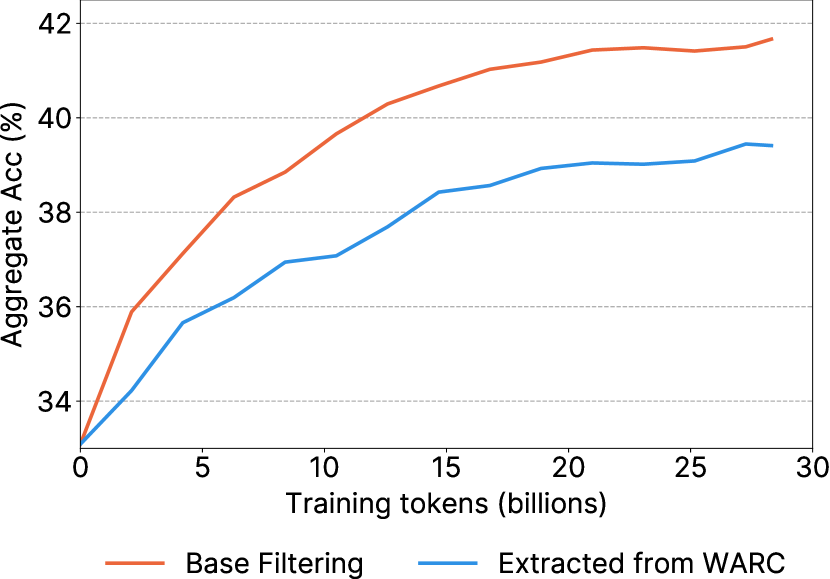
- URL 차단 목록, 영어에 대한 fastText 언어 필터링, 및 MassiveText에서 영감을 받은 품질/반복 필터를 포함한 기본 필터링 파이프라인을 적용한다.
- 14개의 버킷에 걸쳐 5-그램과 112개의 해시 함수로 중복을 줄이기 위해 크롤링당 MinHash 중복 제거를 수행한다.
- 선정된 C4-스타일 휴리스틱 필터로 필터링을 보강하여 과도한 토큰 손실 없이 벤치마크 성능을 개선한다.
- 고품질 및 저품질 데이터 분포를 분석하고 집계 점수를 높이는 3개의 필터를 선택하여 추가 휴리스틱 필터를 개발한다.
- 재현성을 가능하게 하기 위해 데이터셋, datatrove 처리 라이브러리 및 ablated 모델을 공개한다.
실험 결과
연구 질문
- RQ1텍스트 추출, 필터링 및 중복 제거 결정이 공개 데이터세트에서의 다운스트림 LLM 성능에 어떤 영향을 미치는가?
- RQ2크롤당 중복 제거 및 표적 필터가 전역 중복 제거를 능가하여 모델 품질을 향상시키는가?
- RQ3C4-스타일 필터와 맞춤 휴리스틱을 도입하면 기본 필터링만을 사용하는 것보다 측정 가능한 이점을 얻는가?
- RQ4특히 선별된 교육 콘텐츠 하위집합(FineWeb-Edu)이 지식 및 추론 중심 벤치마크를 개선하는가?
주요 결과
- WARC 기반 텍스트 추출이 Trafilatura를 사용했을 때 WET 기반 추출보다 더 나은 성능을 보인다.
- 기본 필터링이 원시 데이터에 비해 상당한 향상을 제공한다.
- 크롤당(independent) MinHash 중복 제거가 전역 중복 제거보다 평균 성능을 향상시킨다.
- All-C4-type 필터를 함께 적용하면 최고 단일 C4 필터보다 우수한 성능을 보이며 토큰 손실도 더 적다.
- 맞춤 휴리스틱 필터가 집계 벤치마크 점수를 추가로 개선하고 C4만 사용하는 것보다 데이터 손실이 적게도 이를 능가할 수 있다.
- FineWeb-Edu는 MMLU 및 ARC와 같은 교육 벤치마크에서 더 나은 성능을 달성한다(예: MMLU 및 ARC와 같은).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.