[논문 리뷰] The Generative AI Paradox: "What It Can Create, It May Not Understand"
Paper는 Generative AI Paradox를 테스트합니다: 언어 및 시각 전반에서 모델의 생성 능력이 인간과 같은 이해를 초과하는 경향이 있음을 보여주며, 생성과 이해 사이의 정렬 약화를 드러냅니다.
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.
연구 동기 및 목표
- Motivate and formalize the Generative AI Paradox hypothesis: generation can exceed understanding in generative models compared to humans.
- Design controlled experiments to compare generation vs. understanding in language and vision models.
- Quantify how discrimination (understanding) performance relates to generation across tasks and modalities.
- Assess robustness of understanding to adversarial inputs and task difficulty.
- Discuss implications for interpreting AI capabilities beyond human-like intelligence.
제안 방법
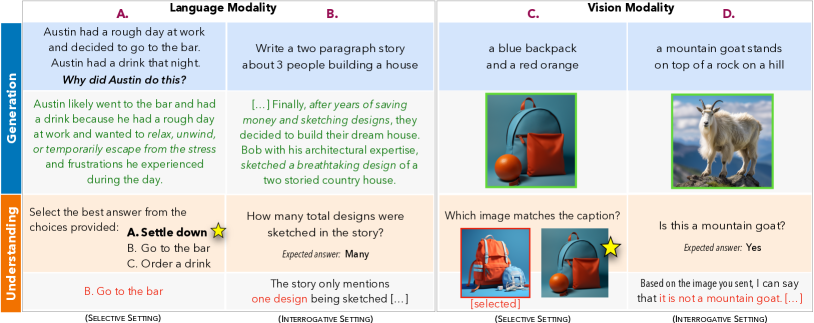
- Define generation as producing content to satisfy an input prompt; define understanding via selective (discriminative) and interrogative evaluations.
- Test GPT-3.5, GPT-4 on language tasks and Midjourney/CLIP/OpenCLIP/BLI P-2, BingChat, Bard on vision tasks across selective and interrogative setups.
- Use discriminative tasks (e.g., multiple-choice) to gauge understanding alongside generation performance.
- In vision, compare generation quality (image prompts) with discriminative tasks using CLIP/OpenCLIP.
- Conduct interrogative evaluation by prompting models to answer questions about their own generated content (language) or about generated images (vision).
- Incorporate hard vs. easy negative candidates to probe robustness of discrimination under adversarial conditions
실험 결과
연구 질문
- RQ1Does generative performance of state-of-the-art models exceed human performance on the same tasks?
- RQ2Do models lag behind humans in discriminative understanding when generation capabilities are matched?
- RQ3Are models able to answer questions about their own generated outputs (interrogative evaluation) with human-like accuracy?
- RQ4How does task difficulty and negative candidate quality affect model understanding vs. generation?
- RQ5Do differences between language and vision modalities shape the generation-understanding relationship?
주요 결과
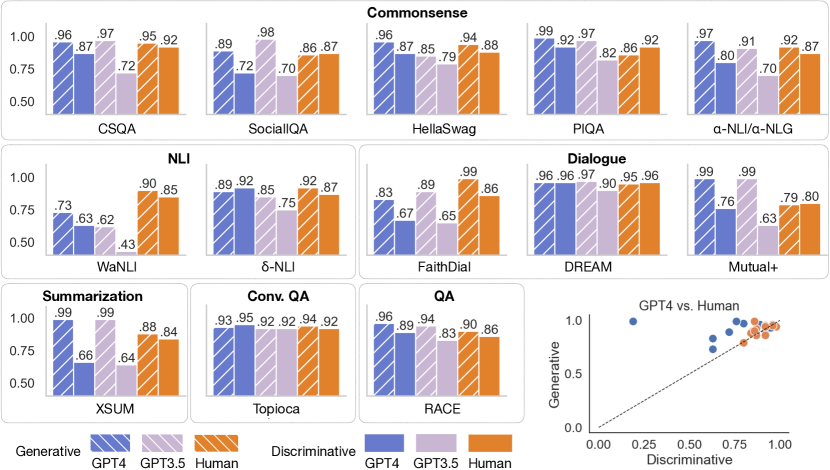
- Models often outperform humans in generation but underperform humans in discriminative understanding across multiple datasets.
- Discrimination performance is more tightly linked to generation performance in humans than in GPT-4.
- Humans exhibit greater robustness to adversarial inputs in discrimination than models, widening the model–human gap with task difficulty.
- In interrogative evaluations, models frequently err when answering questions about their own generated content, while humans keep higher accuracy.
- Vision results show generation surpassing humans in quality but understanding lags in answering content-related questions about generated images.
- Across language, 10 of 13 datasets show sub-hypothesis 1 support in at least one model; 7 of 13 show it in both models (GPT-3.5 and GPT-4).
- In vision, discriminative accuracy by CLIP/OpenCLIP falls short of human accuracy, while generation quality remains high.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.