[논문 리뷰] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism
논문은 다양한 벤치마크 및 모델에서 탐욕적 디코딩과 샘플링을 비교하여 LLM 생성의 비결정성을 조사하고 있으며, 보통 탐욕적 방식이 우세하지만 주목할 예외가 있으며, 정렬(alignment), 스케일링, 그리고 best-of-N 전략의 영향을 강조한다.
Current evaluations of large language models (LLMs) often overlook non-determinism, typically focusing on a single output per example. This limits our understanding of LLM performance variability in real-world applications. Our study addresses this issue by exploring key questions about the performance differences between greedy decoding and sampling, identifying benchmarks' consistency regarding non-determinism, and examining unique model behaviors. Through extensive experiments, we observe that greedy decoding generally outperforms sampling methods for most evaluated tasks. We also observe consistent performance across different LLM sizes and alignment methods, noting that alignment can reduce sampling variance. Moreover, our best-of-N sampling approach demonstrates that smaller LLMs can match or surpass larger models such as GPT-4-Turbo, highlighting the untapped potential of smaller LLMs. This research shows the importance of considering non-determinism in LLM evaluations and provides insights for future LLM development and evaluation.
연구 동기 및 목표
- 단일 결정론적 결과가 아닌 LLM 출력의 비결정성 평가의 필요성을 제시한다.
- 다양한 벤치마크에서 탐욕적 디코딩이 샘플링보다 우수한 시점과 그렇지 않은 시점을 특징지낸다.
- 모델 크기 및 정렬 방법에 따른 비결정성 효과의 일관성을 평가한다.
- 스케일링, 정렬, 온도, 반복 페널티 등 비결정적 생성을 좌우하는 요인을 탐구한다.
- 작은 LLM의 역량을 끌어내기 위한 best-of-N 샘플링의 가능성을 시연한다.
제안 방법
- AlpacaEval 2, Arena-Hard, WildBench v2, MixEval, MMLU-Redux, GSM8K, 및 HumanEval를 포함한 7개 벤치마크에서 탐욕적 디코딩과 핵심 샘플링(nucleus sampling)을 비교한다.
- 다수의 오픈-가중치 LLM과 독점형 GPT-4-Turbo 기준선을 평가한다.
- 대부분의 벤치마크에 대해 16개의 완성을 샘플링하고, MMLU-Redux에는 32개, GSM8K 및 HumanEval에는 128개를 샘플링한다.
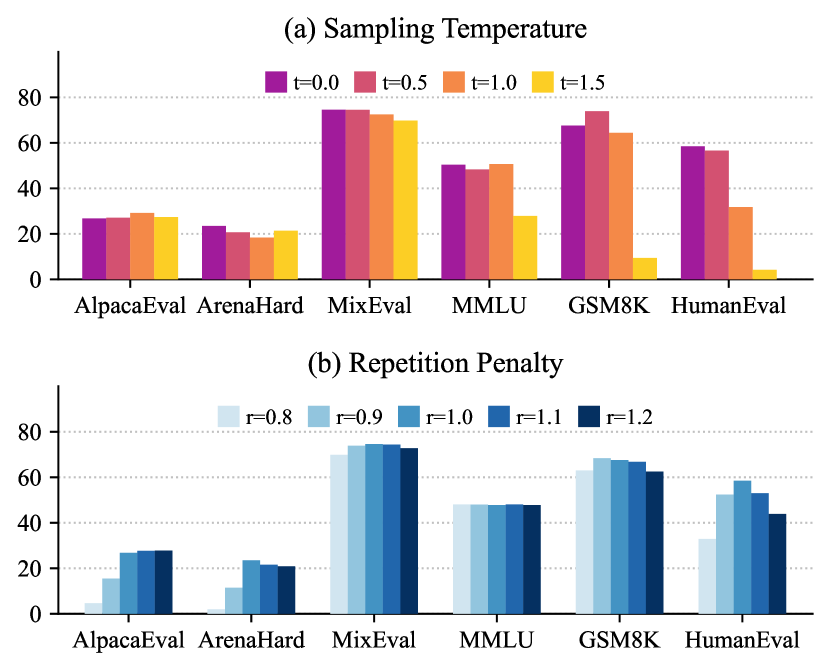
- 스케일링, 정렬 방법(DPO, KTO, SimPO 등), 온도, 반복 페널티 효과를 조사한다.
- reward 모델을 이용한 best-of-N 샘플링으로 상위 응답을 랭크하고 선택하며, 오라클 상한과 비교한다.
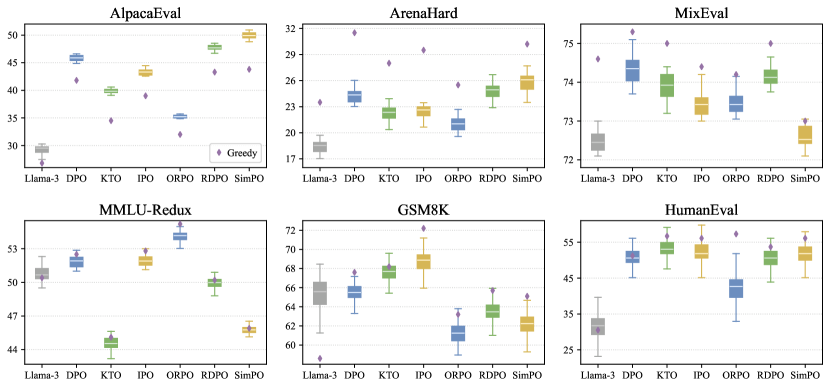
실험 결과
연구 질문
- RQ1Q1: 벤치마크와 모델에 따라 탐욕적 디코딩과 샘플링 간 성능 차이가 어떻게 달라지는가?
- RQ2Q2: 어떤 경우에 탐욕적 디코딩이 샘플링보다 낫고, 어떤 경우에 반대이며 그 이유는 무엇인가?
- RQ3Q3: 비결정성과 관련해 가장 일관된 벤치마크와 가장 일관성이 낮은 벤치마크는 무엇인가?
- RQ4Q4: 어떤 모델이 작업 간에 특징적인 비결정성 패턴을 보이는가?
주요 결과
- 대부분의 벤치마크에서 탐욕적 디코딩이 일반적으로 샘플링보다 우수하지만, 순위는 구성을 바꿔가며 달라질 수 있다.
- AlpacaEval은 샘플링이 더 높은 승률을 보이는 예외이다.
- 출력 공간이 제한된 벤치마크(예: MixEval, MMLU)는 더 높은 안정성을 보이고, 수학 및 코딩 과제(GSM8K, HumanEval)는 샘플링 변동성의 영향을 더 많이 받는다.
- 다른 모델 크기와 계열에서도 결과가 일치하며, 정렬 방법이 많은 과제에서 샘플링 변동성을 줄일 수 있다.
- reward 모델을 사용하는 best-of-N 샘플링은 소형 LLM이 여러 과제에서 GPT-4-Turbo와 일치하거나 능가하게 할 수 있으며, 오라클 best-of-N은 상한 잠재력을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.