[논문 리뷰] The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
tldr: Hallucinations Leaderboard를 소개합니다, 학습 없이 다수의 작업에서 사실성 및 충실도에 대해 LLM의 환각 경향을 정량화하는 개방형 플랫폼인 Hallucinations Leaderboard를 소개합니다. 이 연구는 모델 패밀리, 지시 미세조정, 크기 효과를 분석합니다.
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
연구 동기 및 목표
- 다양한 작업과 설정에서 LLM이 얼마나 자주 환각을 생성하는지 정량화합니다.
- 환각을 사실성(factuality)과 충실도(faithfulness) 범주로 구분합니다.
- 모델 패밀리, 크기, 지시 미세조정이 환각 경향에 미치는 영향을 평가합니다.
제안 방법
- 제로샷 및 페어샷 평가를 위해 EleutherAI Evaluation Harness를 채택합니다.
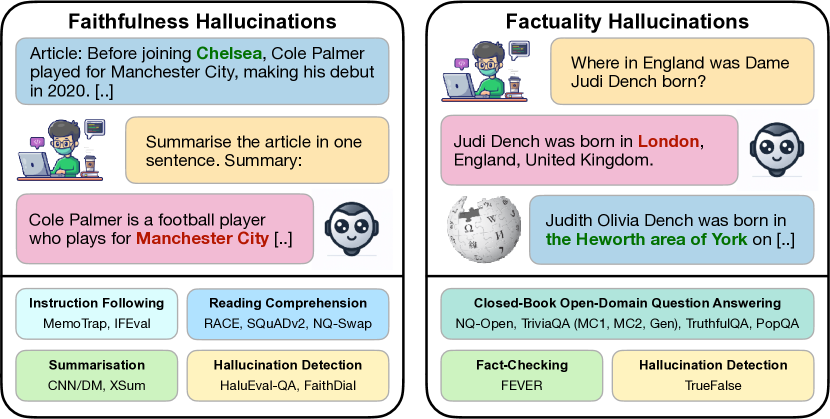
- 작업 전반에 걸친 두 가지 환각 범주를 정의합니다: 사실성(factuality)과 충실도(faithfulness).
- 작업 지표를 평균하여 두 가지 종합 점수(사실성 점수와 충실도 점수)를 사용합니다.
- 여러 모델 패밀리와 크기에 걸쳐 오픈 소스 백본 및 미세조정 변형을 평가합니다.
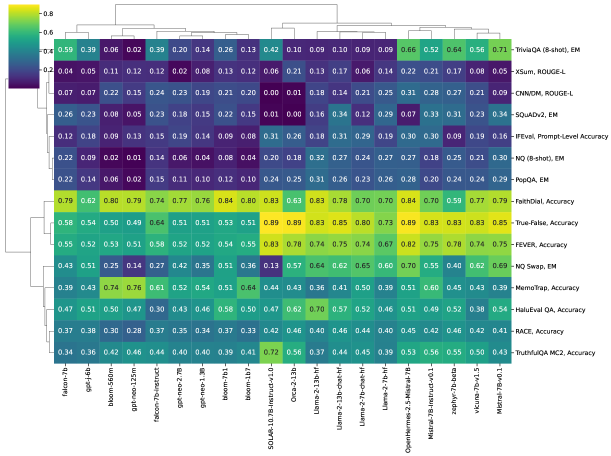
- 모델과 작업 간의 패턴을 식별하기 위해 히트맵과 계층적 클러스터링으로 결과를 분석합니다.
실험 결과
연구 질문
- RQ1다양한 LLM 패밀리는 작업 전반에서 사실성 및 충실도에서 어떻게 비교되나요?
- RQ2지시 미세조정이 환각 경향에 미치는 영향은 무엇인가요?
- RQ3모델 크기가 사실성에 비해 충실도에 어떤 영향을 미치나요?
- RQ4지시를 따르는 것과 사실적 정확성 사이에 트레이드오프가 있나요?
- RQ5이번 연구의 결과가 환각에서의 모델 사전지식(model priors)과 기억(memory)에 관한 기존 연구와 일치하나요?
주요 결과
- 지시 미세조정된 모델은 일반적으로 충실도를 향상시키지만 사실성에서는 혼합되거나 제한적인 이득을 보입니다.
- 사실성은 충실도보다 모델 크기가 커질수록 더 많은 이점을 얻는 경향이 있습니다.
- 모델 클러스터링은 개별 아키텍처보다는 모델 패밀리와의 정렬 경향이 있어 공유된 학습/데이터 영향력을 시사합니다.
- GPT-Neo 및 Llama-2 계통은 QA, 요약, 탐지 과제에서 다양한 강점을 보여줍니다.
- 기억 기반 작업(예: NQ-open)은 기본 진실 표현에도 불구하고 표면적 사실성은 약하게 드러납니다.
- The Hallucinations Leaderboard는 지시를 따르는 것(충실도)과 사실적으로 정확한 콘텐츠를 생성하는 것(사실성) 간의 기존 트레이드오프를 강조합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.