[논문 리뷰] The Impact of Positional Encoding on Length Generalization in Transformers
노포(NoPE) (no positional encoding)는 디코더-전용 Transformer에서 길이 일반화에 대해 명시적 위치 인코딩을 능가하며, 추론 및 수학 과제 전반에 걸쳐 작동하고, NoPE는 절대 위치와 상대 위치를 모두 표현할 수 있으며, 종종 T5의 Relative PE처럼 동작한다.
Length generalization, the ability to generalize from small training context sizes to larger ones, is a critical challenge in the development of Transformer-based language models. Positional encoding (PE) has been identified as a major factor influencing length generalization, but the exact impact of different PE schemes on extrapolation in downstream tasks remains unclear. In this paper, we conduct a systematic empirical study comparing the length generalization performance of decoder-only Transformers with five different position encoding approaches including Absolute Position Embedding (APE), T5's Relative PE, ALiBi, and Rotary, in addition to Transformers without positional encoding (NoPE). Our evaluation encompasses a battery of reasoning and mathematical tasks. Our findings reveal that the most commonly used positional encoding methods, such as ALiBi, Rotary, and APE, are not well suited for length generalization in downstream tasks. More importantly, NoPE outperforms other explicit positional encoding methods while requiring no additional computation. We theoretically demonstrate that NoPE can represent both absolute and relative PEs, but when trained with SGD, it mostly resembles T5's relative PE attention patterns. Finally, we find that scratchpad is not always helpful to solve length generalization and its format highly impacts the model's performance. Overall, our work suggests that explicit position embeddings are not essential for decoder-only Transformers to generalize well to longer sequences.
연구 동기 및 목표
- 처음부터 학습된 디코더-전용 트랜스포머에서 서로 다른 위치 인코딩 체계가 길이 일반화에 어떤 영향을 미치는지 조사한다.
- Absolute Position Embedding (APE), T5의 Relative PE, ALiBi, Rotary, 및 NoPE를 일련의 추론 및 수학 과제에서 비교한다.
- 다운스트림 과제에서 무위치 인코딩(NoPE)이 길이 일반화를 지원하거나 이를 능가할 수 있는지 평가한다.
제안 방법
- 자연스러운 시작부터 학습된 ~107M 매개변수를 가진 일반적인 디코더-전용 트랜스포머를 사용하고 자기회귀 objective로 학습한다.
- 다섯 가지 위치 인코딩 방식 평가: APE(사인파 형태), T5의 Relative Bias, ALiBi, Rotary, 그리고 NoPE (no PE).
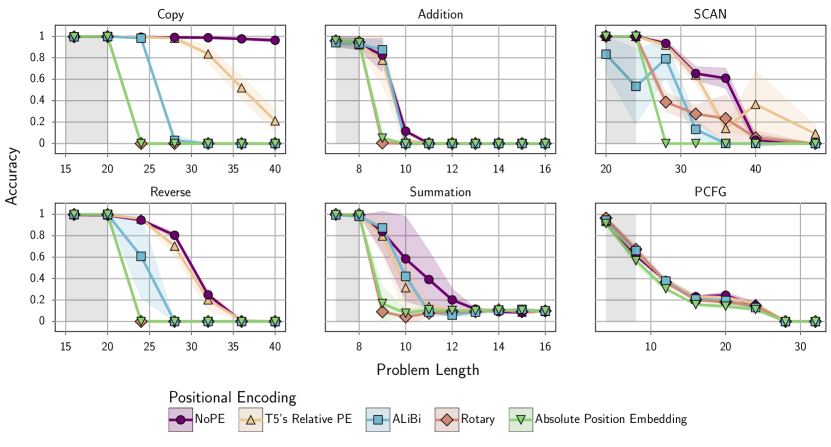
- 프리미티브(복사 Copy, 역방향 Reverse) 및 수학/추론 작업(Addition, Polynomial Eval., Sorting, Summation, Parity, LEGO) 및 고전 데이터셋(SCAN, PCFG)을 포함하는 합성 작업 세트에서 성능을 평가한다.
- L까지의 길이(기본값 L=20)에서 학습하고 2L까지의 길이에서 평가하여 길이 일반화를 테스트하며, IISD/확장 길이 시나리오를 포함한다.
- 주의 패턴과 스크래치패드(Chain-of-Thought) 형식을 분석하여 PE와 길이 일반화 간의 상호작용을 이해한다.
- NoPE가 절대 위치 인코딩과 상대 위치 인코딩을 모두 표현할 수 있음을 보이는 이론적 결과를 제공하고, SGD로 학습시킨 실험에서 NoPE가 T5의 RPE와 유사한 상대 인코딩을 닮아 가는 경험적 근거를 제시한다.
실험 결과
연구 질문
- RQ1명시적 위치 인코딩(NoPE)을 제거하는 것이 디코더-전용 트랜스포머에서 다양한 다운스트림 작업 전반에 걸친 길이 일반화를 개선하는가?
- RQ2APE, T5 Relative Bias, ALiBi, Rotary, 그리고 NoPE 중에서 어떤 PE 체계가 더 긴 시퀀스로의 외삽(extrapolation)을 가장 잘 제공하는가?
- RQ3NoPE가 절대 위치와 상대 위치를 암묵적으로 모두 표현할 수 있는가, 처음부터 학습했을 때 실제로 어떤 것을 닮는가?
- RQ4Scratchpad(CoT) 형식이 다양한 PE와 길이 일반화에서 어떻게 상호작용하는가?
- RQ5각 PE가 유발하는 주의 패턴의 차이가 무엇이며, 이것이 길이 일반화 성능과 어떻게 관련되는가?
주요 결과
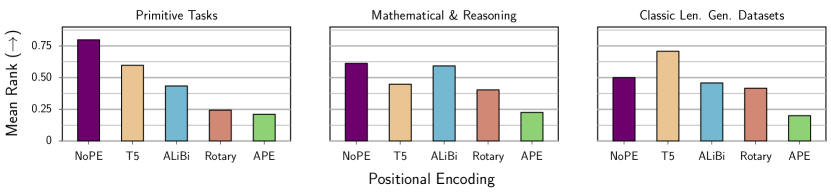
- NoPE는 여러 과제에서 길이 일반화에 대해 명시적 위치 인코딩(APE, ALiBi, Rotary, 심지어 T5의 Relative Bias)보다 일관되게 우수하다.
- NoPE는 주의에서 추가적인 계산 없이도 유사하거나 더 나은 일반화를 달성하는 반면, 명시적 PE는 여분의 항을 필요로 한다.
- 이론적 결과는 NoPE가 절대 위치 인코딩과 상대 위치 인코딩을 모두 표현할 수 있음을 보여주지만, SGD로 학습된 NoPE의 동작은 T5의 RPE와 유사한 상대 위치 주의 패턴과 일치한다.
- Scratchpad는 일부 과제에서만 길이 일반화를 향상시키며(모든 과제가 아니고), 형식과 사용된 PE에 따라 달라진다.
- 주의 분석에 따르면 NoPE와 T5의 Relative PE는 길고 짧은 범위의 위치 모두에 주의를 기울이도록 하는 반면, ALiBi는 최근 토큰에 편향되고, Rotary는 APE의 행동과 유사한 경향을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.