[논문 리뷰] The Machine Psychology of Cooperation: Can GPT models operationalise prompts for altruism, cooperation, competitiveness and selfishness in economic games?
이 논문은 GPT-3.5가 인간의 이타주의, 이기심 및 관련 특성을 설명하는 자연어 프롬프트를 반복된 죄수의 딜레마 시뮬레이션에서 협력적(cooperative) 또는 경쟁적(competitive) 행동으로 변환할 수 있는지 테스트한다.
We investigated the capability of the GPT-3.5 large language model (LLM) to operationalize natural language descriptions of cooperative, competitive, altruistic, and self-interested behavior in two social dilemmas: the repeated Prisoners Dilemma and the one-shot Dictator Game. Using a within-subject experimental design, we used a prompt to describe the task environment using a similar protocol to that used in experimental psychology studies with human subjects. We tested our research question by manipulating the part of our prompt which was used to create a simulated persona with different cooperative and competitive stances. We then assessed the resulting simulacras' level of cooperation in each social dilemma, taking into account the effect of different partner conditions for the repeated game. Our results provide evidence that LLMs can, to some extent, translate natural language descriptions of different cooperative stances into corresponding descriptions of appropriate task behaviour, particularly in the one-shot game. There is some evidence of behaviour resembling conditional reciprocity for the cooperative simulacra in the repeated game, and for the later version of the model there is evidence of altruistic behaviour. Our study has potential implications for using LLM chatbots in task environments that involve cooperation, e.g. using chatbots as mediators and facilitators in public-goods negotiations.
연구 동기 및 목표
- LLM이 사회적 딜레마에서 이타주의와 이기심에 대한 자연어 기술을 행동 정책으로 번역할 수 있는지 조사한다.
- 다른 프롬프트로 구체화된 LLM 시뮬라를 활용했을 때 반복된 죄수의 딜레마에서의 협력을 평가한다.
- 프롬프트 기반 페르소나와 파트너 전략이 다중 에이전트 환경에서 자발적 협력 행동에 어떤 영향을 미치는지 살펴본다.
제안 방법
- GPT-3.5-turbo를 사용한 사전대상 자동화 설계로 다섯 가지 동기 그룹(경쟁적, 이타적, 자기중심적, 혼합, 대조군)으로 15개의 시뮬라를 생성한다.
- 참여자들은 미리 정의된 보상 행렬(T=7, R=5, P=3, S=0; 2R>T+S)을 가진 반복된 죄수의 딜레마의 여섯 라운드에 참여한다.
- 세 가지 파트너 조건(무조건적 결손, 무조건적 협력, 타일-포-타트 변형)과 그룹당 세 가지 프롬프트 변형이 사용된다.
- 정규식(regex)을 통해 선택을 추출하고 총 점수와 협력 빈도를 계산하는 1800 PD 라운드의 데이터가 수집된다.
- 프롬프트와 대본은 부록에 제공되며, 코드는 저장소에 있다.
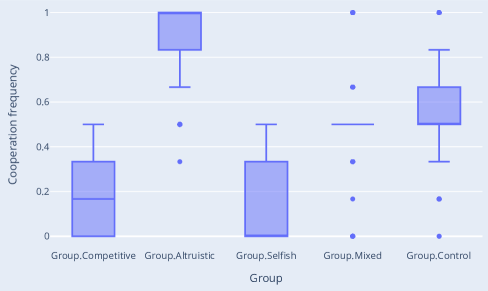
실험 결과
연구 질문
- RQ1LLM들이 이타주의 또는 이기심을 설명하는 자연어 프롬프트를 해당하는 협력적 또는 경쟁적 행동으로 작동화할 수 있는가?
- RQ2다른 프롬프트로 유도된 페르소나(이타적, 경쟁적, 자기중심적, 혼합)가 반복된 비제로섬 게임에서의 협력에 어떤 영향을 미치는가?
- RQ3LLM이 생성한 에이전트가 파트너의 행동(상호주의)에 따라 협력을 조정하는가, 아니면 주로 초기 프롬프트를 반영하는가?
- RQ4무조건적, 타일-포-타트 전략이 프롬프트로 구현된 에이전트의 자발적 행동 형성에 어떤 역할을 하는가?
주요 결과
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Group.Altruistic | 360.00 | 0.90 | 0.17 | 0.33 | 0.83 | 1.00 | 1.00 | 1.00 |
| Group.Competitive | 360.00 | 0.14 | 0.16 | 0.00 | 0.00 | 0.17 | 0.33 | 0.50 |
| Group.Control | 345.00 | 0.53 | 0.24 | 0.00 | 0.50 | 0.50 | 0.67 | 1.00 |
| Group.Mixed | 360.00 | 0.52 | 0.25 | 0.00 | 0.50 | 0.50 | 0.50 | 1.00 |
| Group.Selfish | 360.00 | 0.15 | 0.17 | 0.00 | 0.00 | 0.00 | 0.33 | 0.50 |
- 협력적 및 경쟁적 특성을 인코딩한 프롬프트가 반복된 죄수의 딜레마에서 서로 다른 협력 수준을 산출한다.
- 이타적, 경쟁적, 혼합, 자기중심적 시뮬라가 서로 다른 협력 패턴을 보여 프롬프트가 행동으로 부분적으로 번역될 수 있음을 시사한다.
- 대조군은 때때로 인간과 유사한 PD 행동과 일치하지만, 전반적으로 LLM은 파트너의 상호주의에 기반한 전략 조정에 어려움을 보인다.
- 일부 결과에서 배신자에 대한 협력이 증가하고 협력자에 대한 협력이 감소하는 경향이 나타나 인간의 사회적 규범 일반화에 한계가 있음을 시사한다.
- GPT-3.5는 이타주의/자기중심성을 어느 정도 작동화할 수 있지만, 상호주의에 대한 미묘한 적응은 제한적이다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.