[논문 리뷰] The Platonic Representation Hypothesis
본 논문은 AI 모델의 표현이 아키텍처, 모달리티 및 과제 전반에 걸쳐 관찰 가능한 공유된 플라토닉 현실 표현으로 수렴하며, 규모의 확장이 이러한 수렴을 촉진한다는 것을 주장한다.
We argue that representations in AI models, particularly deep networks, are converging. First, we survey many examples of convergence in the literature: over time and across multiple domains, the ways by which different neural networks represent data are becoming more aligned. Next, we demonstrate convergence across data modalities: as vision models and language models get larger, they measure distance between datapoints in a more and more alike way. We hypothesize that this convergence is driving toward a shared statistical model of reality, akin to Plato's concept of an ideal reality. We term such a representation the platonic representation and discuss several possible selective pressures toward it. Finally, we discuss the implications of these trends, their limitations, and counterexamples to our analysis.
연구 동기 및 목표
- 신경 표현이 현실의 공유된 통계적 모델(플라토닉 표현)로 수렴한다는 아이디어를 동기 부여하고 형식화한다.
- 표현 정렬(representation alignment)을 정의하고, 모델과 모달리티 전반에 걸친 커널 기반 유사도 지표로 이를 측정한다.
- 아키텍처, 목표, 데이터 모달리티, 그리고 뇌 유사 표현 간의 수렴을 조사한다.
- 규모 및 성능이 표현 정렬 및 다운스트림 태스크 이전으로 어떤 관계를 가지는지 살펴본다.
- 한계와 반례를 논의하고 향후 기초 모델에 대한 시사점을 제시한다.
제안 방법
- 표현은 유사도 구조를 포착하기 위해 연결된 커널과 함께 벡터 임베딩으로 다뤄진다.
- 표현 정렬은 CKD/CKA 및 상호 최근접 이웃 지표와 같은 커널 정렬 지표를 사용하여 정량화된다.
- 실험은 다양한 아키텍처와 학습 목표를 가진 78개의 비전 모델 간의 정렬을 비교한다.
- 교차 모달 정렬은 공통 데이터셋(예: 위키피디아 자막)에서 비전과 언어 모델을 짝지어 유도 커널을 비교함으로써 측정된다.
- 정렬의 증거는 모델의 역량, 규모 및 다운스트림 태스크 이전 성능과 연결된다.

실험 결과
연구 질문
- RQ1다양한 아키텍처와 목표에서 나온 신경 표현은 모델이 확장되고 다양화될수록 서로 정렬되는가?
- RQ2교차 모달 표현(시각 및 언어)이 공유된 표현으로 수렴하는가?
- RQ3표현 정렬과 다운스트림 태스크 성능 사이에 측정 가능한 관계가 있는가?
- RQ4표현이 뇌 표현과 어느 정도까지 정렬되며, 이것이 데이터의 보편적 구조에 대해 무엇을 시사하는가?
- RQ5표현 수렴의 한계와 경계 조건은 무엇인가(예: 센서 차이)?
주요 결과
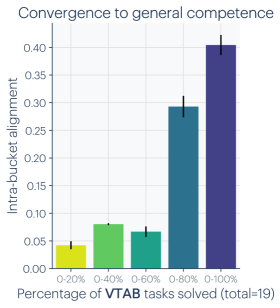
- 다양한 목표를 가진 서로 다른 모델의 표현은 역량이 커질수록 정렬이 증가한다.
- 시각 및 언어 모델은 모델 품질이 높아질수록 강화되는 교차 모달 정렬을 보이고, 명시적인 언어 감독(예: CLIP)이 이 정렬에 영향을 미친다.
- 모델 간 정렬은 규모와 성능이 커질수록 증가하며, 역량 있는 모델은 더 촘촘한 표현 클러스터를 형성한다.
- 더 잘 정렬된 모델이 다운스트림 태스크(예: 일반상식 추론, 수학 문제)에서 더 잘 수행하는 경향이 있다는 실증적 증거가 있다.
- 신경망은 뇌 표현과의 정렬을 보이며, 지각 데이터의 처리에 공통된 기저 구조를 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.