[논문 리뷰] Tight Auditing of Differentially Private Machine Learning
이 논문은 f-DP/GDP를 활용하여 두 차례의 학습 실행만으로 자연 데이터세트에 대해 이론적 프라이버시 보장에 근접한 보장을 제공하는 DP-SGD에 대한 촘촘한 감사 체계를 도입한다. 또한 이 접근법이 프라이버시 관련 코드의 구현 버그를 드러낼 수 있음을 보여준다.
Auditing mechanisms for differential privacy use probabilistic means to empirically estimate the privacy level of an algorithm. For private machine learning, existing auditing mechanisms are tight: the empirical privacy estimate (nearly) matches the algorithm's provable privacy guarantee. But these auditing techniques suffer from two limitations. First, they only give tight estimates under implausible worst-case assumptions (e.g., a fully adversarial dataset). Second, they require thousands or millions of training runs to produce non-trivial statistical estimates of the privacy leakage. This work addresses both issues. We design an improved auditing scheme that yields tight privacy estimates for natural (not adversarially crafted) datasets -- if the adversary can see all model updates during training. Prior auditing works rely on the same assumption, which is permitted under the standard differential privacy threat model. This threat model is also applicable, e.g., in federated learning settings. Moreover, our auditing scheme requires only two training runs (instead of thousands) to produce tight privacy estimates, by adapting recent advances in tight composition theorems for differential privacy. We demonstrate the utility of our improved auditing schemes by surfacing implementation bugs in private machine learning code that eluded prior auditing techniques.
연구 동기 및 목표
- 최악의 경우 감사를 넘어서 더 타이트하고 실용적인 경험적 프라이버시 추정이 필요하다는 이유를 제시한다.
- DP-SGD 하에서 자연 데이터셋에 대해 타이트한 프라이버시 추정을 산출하는 감사 체계를 개발한다.
- 감사의 계산 부담을 수천 번의 학습에서 작고 현실 가능한 수로 축소한다.
- 프라이버시 관련 버그를 탐지하기 위해 DP-SGD 구현을 직접 점검할 수 있도록 한다.
제안 방법
- 메커니즘의 실제 프라이버시 트레이드오프를 포착하기 위해 f-DP/GDP 설정에서 감사를 프레이밍한다.
- 프라이버시 손실 분포(PLD)와 Gaussian DP를 적용하여 프라이버시 매개변수의 타이트한 하한을 얻는다.
- 관찰된 false positive/false negative 비율로부터 프라이버시 매개변수를 한계짓기 위해 Clopper-Pearson 및 베이즈 기법을 사용한다.
- GDP 기반 감사를 표준 (epsilon,delta)-DP 감사와 비교하고 더 적은 관찰로 더 타이트한 경계가 나오는 것을 보인다.
- 현실적 공격자 능력을 고려하여 화이트박스에서 블랙박스에 이르는 위협 모델을 조사하고 감사 효과를 평가한다.
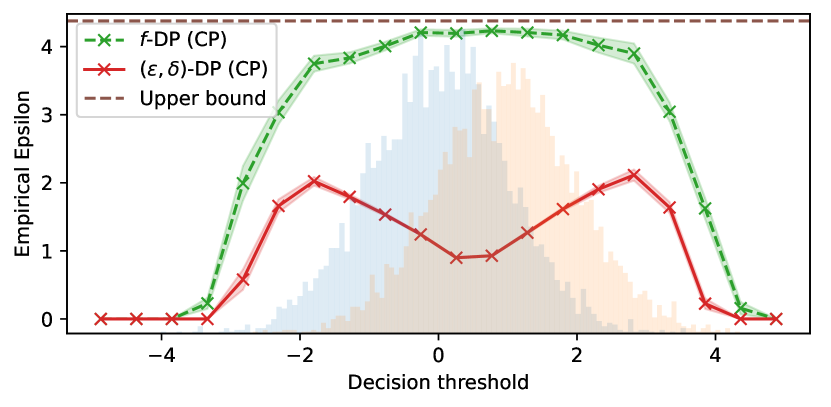
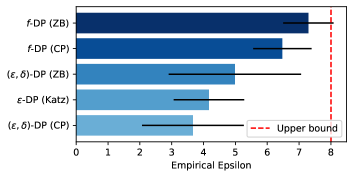
실험 결과
연구 질문
- RQ1DP-SGD의 경험적 프라이버시 누출이 Worst-case가 아닌 자연 데이터셋에서 타이트하게 추정될 수 있는가?
- RQ2DP-SGD에 대해 타이트한 경험적 프라이버시 경계를 얻기 위해 필요한 학습 실행 수는 얼마인가?
- RQ3특정 프라이버시 메커니즘(f-DP/GDP)에 맞춘 감사가 보편적 DP 감사 방식보다 우수한가?
- RQ4감사를 통해 DP-SGD 구현의 이전 방법들이 놓친 버그를 드러낼 수 있는가?
- RQ5다른 공격자 위협 모델이 프라이버시 감사의 타이트함과 실용성에 어떤 영향을 미치는가?
주요 결과
- GDP를 활용한 감사가 전통적 epsilon-delta 감사를 훨씬 더 타이트한 경험적 프라이버시 경계를 제공하며 관찰이 훨씬 적은 경우에도 이론적 값에 근접한 경계를 달성한다.
- 제안된 체계는 자연 데이터셋에서 DP-SGD에 대해 타이트한 프라이버시 추정을 산출하기 위해 단 두 번의 학습 실행만 필요하다.
- Gaussian/functional DP 프레임워크에 맞춘 감사와 PLD를 사용하면 구성 및 서브샘플링 하에서 DP-SGD의 프라이버시 손실에 대한 정확한 경계가 가능하다.
- 감사를 통해 DP-SGD 구현의 구현 버그가 이전 감사 기법에서 놓친 것을 드러낼 수 있다.
- 화이트박스 및 블랙박스 설정을 포함한 위협 모델-인식 감사는 업데이트나 데이터 접근이 경험적 프라이버시 추정의 타이트함에 어떤 영향을 미치는지 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.