[논문 리뷰] TIM: Teaching Large Language Models to Translate with Comparison
TIM은 출력 및 선호도 비교를 활용하여 오픈 소스 LLM의 번역을 미세 조정해 번역 품질, 제로샷 성능, 모델 크기에 따른 강건성을 향상시킵니다.
Open-sourced large language models (LLMs) have demonstrated remarkable efficacy in various tasks with instruction tuning. However, these models can sometimes struggle with tasks that require more specialized knowledge such as translation. One possible reason for such deficiency is that instruction tuning aims to generate fluent and coherent text that continues from a given instruction without being constrained by any task-specific requirements. Moreover, it can be more challenging for tuning smaller LLMs with lower-quality training data. To address this issue, we propose a novel framework using examples in comparison to teach LLMs to learn translation. Our approach involves presenting the model with examples of correct and incorrect translations and using a preference loss to guide the model's learning. We evaluate our method on WMT2022 test sets and show that it outperforms existing methods. Our findings offer a new perspective on fine-tuning LLMs for translation tasks and provide a promising solution for generating high-quality translations. Please refer to Github for more details: https://github.com/lemon0830/TIM.
연구 동기 및 목표
- 표준 명령 학습(instruction tuning)을 넘어서 오픈소스 LLM의 번역 성능 향상을 촉진한다.
- 새로운 비교 메커니즘을 통해 작지만 고품질의 번역 데이터 세트를 활용한다.
- 출력 비교 신호와 선호도 비교 신호를 도입하여 번역 학습을 정규화하고 유도한다.
- TIM이 모델 크기에 따라 확장되고 제로샷 번역으로 일반화되는 방식을 평가한다.
- 번역 품질에 영향을 주는 추론 전략과 데이터 유형에 대한 통찰을 제공한다.
제안 방법
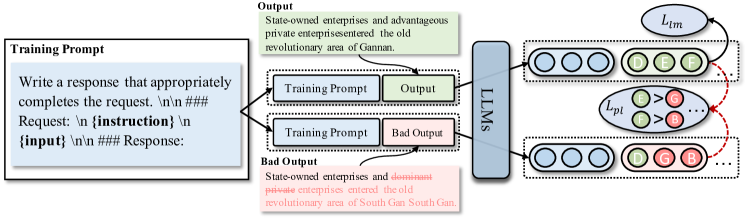
- 동일 입력에 대해 서로 다른 지시에 대한 응답을 학습하기 위해 출력 비교를 도입한다.
- 더 나은 번역과 더 나쁜 번역을 구분하기 위한 선호도 비교 손실을 도입한다.
- 출력을 규제로 하기 위해 토큰 수준의 선호 손실 L_pl를 추가한다(논문에 L_pl 수식이 제공되어 있습니다).
- 표준 언어 모델링 손실(L_lm)과 L_pl를 결합한다(L = L_lm + λ L_pl, λ = 1.0).
- 비교를 위한 세 가지 데이터 유형을 구성한다: order-guided(정렬 지시 기반), dictionary-guided(사전 기반), 및 error-guided(오류 기반) 데이터.
- 매개변수 효율성과 성능을 평가하기 위해 세 가지 튜닝 전략(LoRA, FixEmb, Full)을 탐색한다.
- EN ⇄ DE 및 ZH ⇄ EN에서 WMT22 및 FLORES-200를 대상으로 평가하고, 다수의 백본 모델(BLOOMZ-7b-mt, LLaMA-2-7b/13b 등)을 사용한다.

실험 결과
연구 질문
- RQ1비교 기반 미세 조정이 오픈 소스 LLM에서 표준 지시 조정보다 번역 품질을 향상시킬 수 있는가?
- RQ2출력 비교 및 선호도 비교가 번역의 허위 진술(hallucination)을 줄이고 정확성에 어떻게 기여하는가?
- RQ3데이터 유형들(order-guided, dictionary-guided, error-guided)이 번역 품질과 강건성에 어떤 영향을 미치는가?
- RQ4모델 크기 및 언어 방향 전반에서 TIM의 성능이 어떻게 확장되며 제로샷 설정을 포함하는가?
- RQ5표준 MT 벤치마크에서 TIM으로 미세 조정된 모델이 감독 학습 기준선(supervised baselines)이나 다국어 MT 모델과 경쟁적이거나 우수한가?
주요 결과
- TIM 및 그 변형은 WMT22 및 FLORES-200에서 네 가지 번역 방향으로 여러 베이스라인(예: Alpaca-*, MT-*, WMT22 수상자)을 지속적으로 능가한다.
- TIM-LLaMA-13b는 영어↔독일어 번역에서 참조 없이도 top-1 품질 추정 성능을 달성한다.
- TIM의 개선은 작은 모델에서 더 두드러져 비교 신호와 결합되었을 때 효율성이 더 높음을 시사한다.
- TIM의 제로샷 다국어 번역 능력은 여러 오픈 소스 모델에 비해 강력한 성능을 보이며, 많은 방향에서 특히 Ja→En에서 NLLB-3.3B와의 격차를 좁힌다.
- 소거 연구는 사전 기반 데이터, 출력 비교, LM 기반 bad-output 변종이 유의미한 신호를 제공하는 반면 무작위 노이즈는 덜 효과적임을 시사한다.
- MT 지표 평가에서 TIM-LLaMA-13b와 TIM-BLOOMZ-7b는 MQM 점수와의 상관관계에서 레퍼런스없는 지표를 능가할 수 있음(시스템 수준 정확도 및 피어슨 상관).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.