[논문 리뷰] Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time-LLM은 입력 시계열을 텍스트 프로토타입으로 재프로그램하고 프롬프트-프리픽스(Prompt-as-Prefix)를 가진 동결 LLM을 사용하여 예측하며, 백본 파인튜닝 없이도 강한 소샷, 제로샷 및 전반적인 최첨단 성능을 달성한다.
Time series forecasting holds significant importance in many real-world dynamic systems and has been extensively studied. Unlike natural language process (NLP) and computer vision (CV), where a single large model can tackle multiple tasks, models for time series forecasting are often specialized, necessitating distinct designs for different tasks and applications. While pre-trained foundation models have made impressive strides in NLP and CV, their development in time series domains has been constrained by data sparsity. Recent studies have revealed that large language models (LLMs) possess robust pattern recognition and reasoning abilities over complex sequences of tokens. However, the challenge remains in effectively aligning the modalities of time series data and natural language to leverage these capabilities. In this work, we present Time-LLM, a reprogramming framework to repurpose LLMs for general time series forecasting with the backbone language models kept intact. We begin by reprogramming the input time series with text prototypes before feeding it into the frozen LLM to align the two modalities. To augment the LLM's ability to reason with time series data, we propose Prompt-as-Prefix (PaP), which enriches the input context and directs the transformation of reprogrammed input patches. The transformed time series patches from the LLM are finally projected to obtain the forecasts. Our comprehensive evaluations demonstrate that Time-LLM is a powerful time series learner that outperforms state-of-the-art, specialized forecasting models. Moreover, Time-LLM excels in both few-shot and zero-shot learning scenarios.
연구 동기 및 목표
- 일반화 가능하고 데이터 효율적인 LLM 능력이 이점이 될 수 있는 도메인으로 시계열 예측의 필요성을 제기한다.
- Time-LLM을 제안하여 시계열 입력을 텍스트 프로토타입으로 재프로그램하고 프롬프트로 보강하여 LLM 추론을 안내한다.
- Time-LLM이 벤치마크 전반에서 및 소샷/제로샷 설정에서 최첨단의 전문 예측 모델보다 우수함을 입증한다.
제안 방법
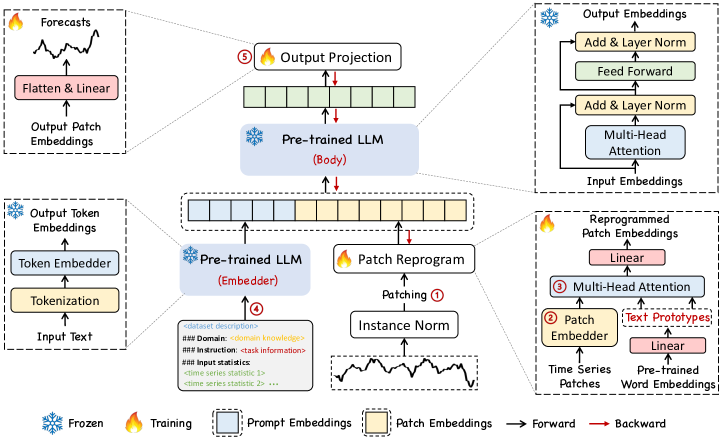
- 패치 기반 입력 변환: 다변량 시계열을 정규화하고 패치화하여 임베딩합니다; 패치로 분할하고 임베딩을 생성합니다.
- 패치 재프로그래밍: 축소된 텍스트 프로토타입 어휘와 교차 어텐션을 사용하여 패치 임베딩을 LLM의 입력 공간으로 매핑하되 백본을 업데이트하지 않습니다 (E, E′, W^Q, W^K, W^V).
- Prompt-as-Prefix (PaP): 작업 지시, 데이터세트 맥락, 입력 통계를 프리픽스로 추가하여 LLM의 추론을 풍부하게 하고 패치 변환을 안내합니다.
- 출력 투영: 재프로그램된 패치를 동결된 LLM에 투입한 다음, 생성된 표현을 평탄화하고 선형적으로 투영하여 예측을 얻습니다.
- 백본: 사전 학습된 LLM을 동결된 상태로 유지(예: Llama-7B)하고 입력 변환 및 출력 투영 모듈만 경량으로 학습합니다.
- 최적화: 예측치와 실제 값 사이의 평균 제곱 오차를 최소화하되, 양자화 및 기타 효율성 기법의 선택적 통합을 허용합니다.
실험 결과
연구 질문
- RQ1Time-LLM이 백본 LLM의 미세조정 없이 시계열을 효과적으로 예측할 수 있는가?
- RQ2시계열 입력을 텍스트 프로토타입으로 재프로그램하는 것이 프롬프트를 통해 예측 추론을 어떻게 향상시키는가?
- RQ3장기 예측, 단기 예측, 소샷 및 제로샷 설정에서 Time-LLM의 성능은 최첨단 전문 예측 모델에 비해 어떤가?
주요 결과
| 데이터셋 | Time-LLM_MSE | Time-LLM_MAE |
|---|---|---|
| ETTh1 | 0.408 | 0.423 |
| ETTh2 | 0.334 | 0.383 |
| ETTm1 | 0.329 | 0.372 |
| ETTm2 | 0.251 | 0.313 |
| Weather | 0.225 | 0.257 |
| ECL | 0.158 | 0.252 |
| Traffic | 0.388 | 0.264 |
| ILI | 1.435 | 0.801 |
- Time-LLM은 벤치마크 전반에서 최첨단 예측 방법을 지속적으로 능가하며 특히 소샷 및 제로샷 시나리오에서 두드러진 성과를 보인다.
- 시계열을 텍스트 프로토타입으로 재프로그램하고 Prompt-as-Prefix를 결합하면 강력한 교차 모달 정렬이 가능해져 예측 정확도가 향상된다.
- Time-LLM은 장기 예측에서 GPT4TS 및 TimesNet보다 주목할 만한 이득을 달성하고 단기 데이터에서도 특정 태스크 트랜스포머보다 경쟁력이 있거나 우수하다.
- 어블레이션 연구는 패치 재프로그래밍, Prompt-as-Prefix, 입력 통계가 성능에 실질적으로 기여하며, 입력 통계가 특히 영향력이 크다는 것을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.