[논문 리뷰] Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs
논문은 숫자 토큰화 방향(왼쪽에서 오른쪽 vs 오른쪽에서 왼쪽)이 GPT-3.5 및 GPT-4의 산술 성능에 현저히 영향을 미치며, R2L이 일반적으로 더 나은 결과를 낳는 경향이 있으며; 모델은 토큰화를 변환해 성능을 회복할 수 있고, 효과는 더 큰 모델에서도 지속된다.
Tokenization, the division of input text into input tokens, is an often overlooked aspect of the large language model (LLM) pipeline and could be the source of useful or harmful inductive biases. Historically, LLMs have relied on byte pair encoding, without care to specific input domains. With the increased use of LLMs for reasoning, various number-specific tokenization schemes have been adopted, with popular models like LLaMa and PaLM opting for single-digit tokenization while GPT-3.5 and GPT-4 have separate tokens for each 1-, 2-, and 3-digit numbers. In this work, we study the effect this choice has on numerical reasoning through the use of arithmetic tasks. We consider left-to-right and right-to-left tokenization for GPT-3.5 and -4, finding that right-to-left tokenization (enforced by comma separating numbers at inference time) leads to largely improved performance. Furthermore, we find that model errors when using standard left-to-right tokenization follow stereotyped error patterns, suggesting that model computations are systematic rather than approximate. We show that the model is able to convert between tokenizations easily, thus allowing chain-of-thought-inspired approaches to recover performance on left-to-right tokenized inputs. We also find the gap between tokenization directions decreases when models are scaled, possibly indicating that larger models are better able to override this tokenization-dependent inductive bias. In summary, our work performs the first study of how number tokenization choices lead to differences in model performance on arithmetic tasks, accompanied by a thorough analysis of error patterns. We hope this work inspires practitioners to more carefully ablate number tokenization-related choices when working towards general models of numerical reasoning.
연구 동기 및 목표
- 프런티어 LLMs에서 수치 추론의 잠재적 귀납 바이어스로서 숫자 토큰화를 신중히 조사하도록 동기를 부여한다.
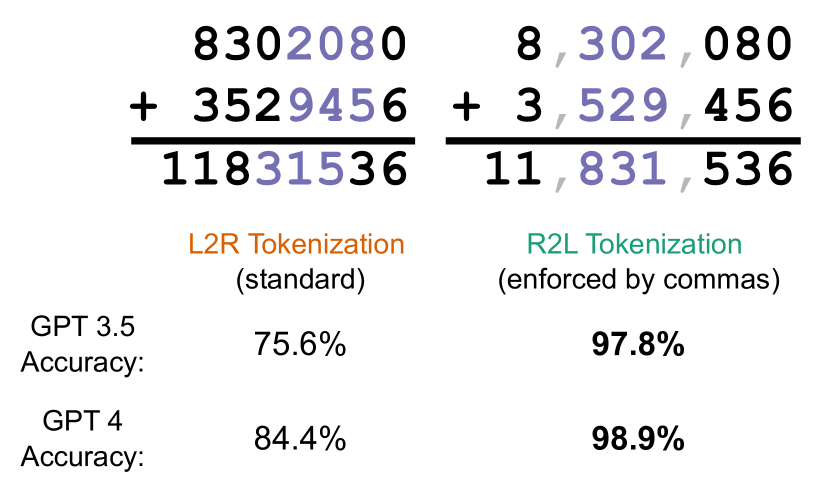
- GPT-3.5와 GPT-4에서 L2R(좌→우) 및 R2L(우→좌) 토큰화 하에서의 산술 성능을 비교한다.
- 토큰화가 추론 과정에 미치는 영향을 이해하기 위해 오류 패턴을 분석한다.
- 모델 규모가 토큰화 관련 바이어스를 완화하는지 평가한다.
제안 방법
- 실험 구성은 OpenAI Chat Completions API를 사용하여 피제수가 7–9자리인 덧셈 태스크를 few-shot 덧셈 태스크로 테스트한다.
- 입력 분절을 바꾸기 위해 세 자리마다 구분자(쉼표나 다른 구분자)를 삽입하여 R2L 토큰화를 강제한다.
- 1-, 2-, 4-, 8-shot 프롬프트에서의 정확도와 모델 버전(GPT-3.5, GPT-4 및 변형) 전반에서의 정확도를 측정한다.
- 출력과 토큰화 방향을 분리하는 프롬프트를 포함한 대체 구분자 및 형식 선행(포맷팅 프라이어)과 '생각 토큰'을 제어하기 위한 제거 연구(ablations)을 수행한다.
- 오류 패턴을 분석하여 L2R 토큰화가 성능이 떨어지는 경우(예: 길이 불일치 케이스)와 오류의 본질(숫자 수준의 오류)을 특징짓는다.
실험 결과
연구 질문
- RQ1토큰화 방향(L2R vs R2L)이 프런티어 LLM의 산술 정확도에 어떠한 영향을 미치는가?
- RQ2토큰화로 인한 효과가 모델 버전 및 더 큰 모델에서도 지속되는가?
- RQ3다른 토큰화 방식에서 어떤 오류 패턴이 나타나며, 이는 체계적 계산과 근사 매칭 중 어느 쪽을 시사하는가?
- RQ4입력 간 토큰화 간 변환을 모델에게 유도하는 프롬프트가 성능 차이를 완화시킬 수 있는가?
- RQ5관찰된 효과가 토큰 경계에 의해 좌우되는가, 아니면 더 넓은 학습 데이터 선행에 의해 좌우되는가?
주요 결과
- 제어된 실험에서 R2L 토큰화가 GPT-3.5 및 GPT-4에서 L2R보다 산술 정확도가 현저히 높게 나오며(예: 정확도 최대 20% 차이).
- R2L과 L2R 간의 정확도 차이는 더 많은 샷에서 커지지만 포화되며, 8-shot 실험에서도 R2L의 견고한 이득을 보인다.
- 길이 불일치 케이스(정답이 피제수보다 긴 경우)는 L2R 성능을 불균형적으로 악화시키며, 입력과 출력 간의 토큰화로 인한 불일치를 드러낸다.
- L2R 토큰화는 길이 불일치 상황에서 매우 고정된 숫자-4 오류를 생성하여 단순한 잡음이 아닌 체계적인 처리 패턴을 시사한다.
- 모델은 L2R 입력을 R2L 출력으로 변환하여 정확도를 회복할 수 있으며, few-shot 프롬프트를 통해 모델이 선호하는 토큰화로 문제를 재생산하도록 할 수 있다.
- 토큰화 의존 효과는 일반적으로 GPT-4 변형을 포함한 최신 모델에도 확장되지만, 규모 및 구성에 따라 그 크기가 달라질 수 있다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.