[논문 리뷰] TopicGPT: A Prompt-based Topic Modeling Framework
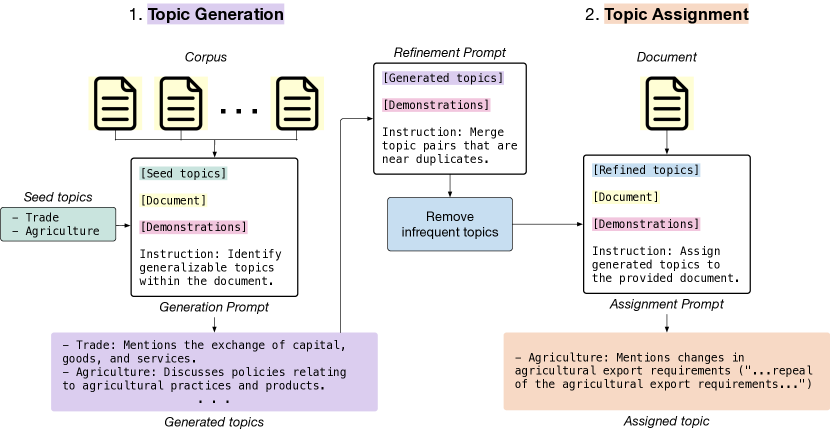
TopicGPT는 프롬프트 기반 대형 언어 모델을 사용하여 텍스트 코퍼스에서 해석 가능한 주제를 생성하고 할당하며, LDA 및 BERTopic보다 인간-정답 주제와의 정렬이 더 높고 재훈련 없이 주제 Refinement 및 계층 구성을 지원합니다.
Topic modeling is a well-established technique for exploring text corpora. Conventional topic models (e.g., LDA) represent topics as bags of words that often require "reading the tea leaves" to interpret; additionally, they offer users minimal control over the formatting and specificity of resulting topics. To tackle these issues, we introduce TopicGPT, a prompt-based framework that uses large language models (LLMs) to uncover latent topics in a text collection. TopicGPT produces topics that align better with human categorizations compared to competing methods: it achieves a harmonic mean purity of 0.74 against human-annotated Wikipedia topics compared to 0.64 for the strongest baseline. Its topics are also interpretable, dispensing with ambiguous bags of words in favor of topics with natural language labels and associated free-form descriptions. Moreover, the framework is highly adaptable, allowing users to specify constraints and modify topics without the need for model retraining. By streamlining access to high-quality and interpretable topics, TopicGPT represents a compelling, human-centered approach to topic modeling.
연구 동기 및 목표
- 인간 중심의 주제 모델링 프레임워크를 개발하여 해석 가능한 주제를 자연어 레이블과 설명으로 제공한다.
- 재훈련 없이 문서 샘플에서 주제를 생성하고 정제하기 위해 반복적 LLM 프롬프트를 활용한다.
- 결과의 검증 가능성을 높이기 위해 supporting quotes를 담은 문서-주제 할당을 제공한다.
- 필요 시 서브 토픽과 더 미세한 정밀도를 탐색하기 위한 계층 확장을 가능하게 한다.
- 주제 출력의 견고성, 안정성 및 인간 주석에 대한 정렬성을 평가한다.
제안 방법
- 샘플 문서와 기존 시드 토픽에서 토픽을 생성하기 위해 LLM을 반복적으로 프롬프트한다.
- 임베딩과 빈도 임계치를 사용하여 근사 중복 병합 및 드문 주제 제거로 토픽을 정제한다.
- 선택적으로 연관 문서에 기반한 하위 주제에 대한 프롬프트를 통해 토픽 계층 구조 확장을 한다.
- 토픽 레이블, 설명 및 지원 인용문을 반환하는 LLM 프롬프트를 통해 문서를 주제에 할당한다.
- 주제 할당의 망상 및 형식 문제를 수정하는 자기 수정 단계를 도입한다.
실험 결과
연구 질문
- RQ1TopicGPT로 생성된 주제는 데이터셋 전반에 걸쳐 LDA 및 BERTopic보다 인간 주석 기반의 정답 주제와 더 일치하는가?
- RQ2프롬프트 변형, 샘플 선택, 오픈 소스 대 비공개 소스 LLM에 대한 TopicGPT 출력은 얼마나 견고한가?
- RQ3TopicGPT가 해석 가능한 주제와 자연어 레이블 및 할당을 지원하는 서술적 인용문을 안정적으로 생성할 수 있는가?
- RQ4TopicGPT를 계층 구조로 확장하면 주제의 정밀도와 유용성이 향상되는가?
- RQ5시드 토픽의 질 및 양이 주제의 응집성과 정렬성에 어떤 영향을 미치는가?
주요 결과
| 데이터 세트 | 설정 | TopicGPT P1 | TopicGPT ARI | TopicGPT NMI | LDA P1 | LDA ARI | LDA NMI | BERTopic P1 | BERTopic ARI | BERTopic NMI |
|---|---|---|---|---|---|---|---|---|---|---|
| Wiki | Default (k=31) | 0.73 | 0.58 | 0.71 | 0.71 | 0.59 | 0.65 | 0.44 | 0.65 | 0.50 |
| Wiki | Refined (k=22) | 0.74 | 0.60 | 0.70 | 0.70 | 0.64 | 0.67 | 0.52 | 0.58 | 0.50 |
| Bills | Default (k=79) | 0.57 | 0.42 | 0.47 | 0.52 | 0.39 | 0.47 | 0.21 | 0.47 | 0.40 |
| Bills | Refined (k=24) | 0.57 | 0.40 | 0.46 | 0.52 | 0.32 | 0.46 | 0.39 | 0.12 | 0.34 |
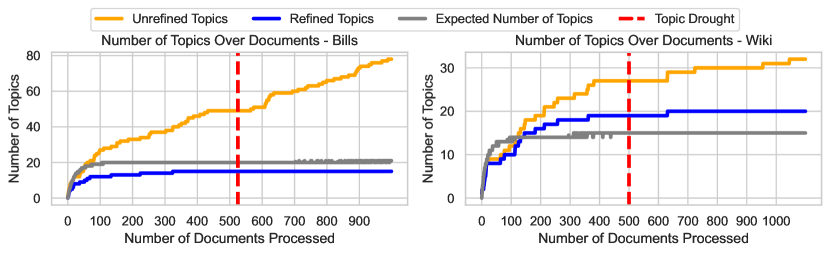
- TopicGPT는 Wiki 및 Bills 데이터 세트에서 LDA 및 BERTopic보다 인간-정답 레이블과의 주제 정렬이 더 높은 것으로 나타났습니다(예: Wiki P1=0.73, ARI=0.58, NMI=0.71; Bills P1=0.57, ARI=0.42, NMI=0.47 기본 설정에서).
- 정제는 해석 가능성을 개선하고 잘못 정렬된 주제를 줄여줍니다(예: 정제된 Wiki P1=0.74, ARI=0.60; 정제된 Bills P1=0.57, ARI=0.40).
- 다양한 프롬프트 및 데이터 샘플에서도 TopicGPT 할당은 안정적으로 유지되며 정렬 지표에서 LDA보다 같거나 우수한 성능을 보인다; 파이프라인을 두 번 실행하면 높은 안정성(P1=0.95, ARI=0.92, NMI=0.92)을 얻는다.
- 오픈 소스 LLM은 주제 할당을 처리할 수 있지만(Mistral-7B-Instruct가 할당에 대해 비교적 잘 작동), 오픈 소스 모델은 GPT-4에 비해 주제 생성에서는 어려움을 겪는다.
- TopicGPT는 비정제 및 정제된 형태 모두에서 LDA보다 정답에 더 가까운 의미적 주제를 생성하며, 정제는 잘못 정렬된 주제를 크게 감소시킨다.
- 계층적 TopicGPT는 부모 주제 및 해당 문서에 기반한 정보성 하위 주제를 생성할 수 있어 더 풍부한 분석이 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.