[논문 리뷰] Towards A Unified Agent with Foundation Models
본 논문은 비전-언어 모델과 대형 언어 모델을 활용하여 희소 보상 로봇 스태킹 작업을 해결하는 언어 중심의 강화 학습 프레임워크를 제시하며, 작업별로 손으로 설계된 커리큘럼 없이도 효율적인 탐색, 데이터 재사용, 기술 스케줄링, 관찰 학습을 가능하게 한다.
Language Models and Vision Language Models have recently demonstrated unprecedented capabilities in terms of understanding human intentions, reasoning, scene understanding, and planning-like behaviour, in text form, among many others. In this work, we investigate how to embed and leverage such abilities in Reinforcement Learning (RL) agents. We design a framework that uses language as the core reasoning tool, exploring how this enables an agent to tackle a series of fundamental RL challenges, such as efficient exploration, reusing experience data, scheduling skills, and learning from observations, which traditionally require separate, vertically designed algorithms. We test our method on a sparse-reward simulated robotic manipulation environment, where a robot needs to stack a set of objects. We demonstrate substantial performance improvements over baselines in exploration efficiency and ability to reuse data from offline datasets, and illustrate how to reuse learned skills to solve novel tasks or imitate videos of human experts.
연구 동기 및 목표
- 기초 모델이 강화 학습 에이전트의 통합 추론 백본으로 작용할 수 있는지 탐구한다.
- 희소 보상 환경에서 탐색 효율의 향상을 시연한다.
- 오프라인 데이터를 재사용하여 순차 작업 학습을 부트스트랩하는 방법을 보여준다.
- 언어 기반 목표를 통한 기술 스케줄링 및 관찰 학습을 설명한다.
제안 방법
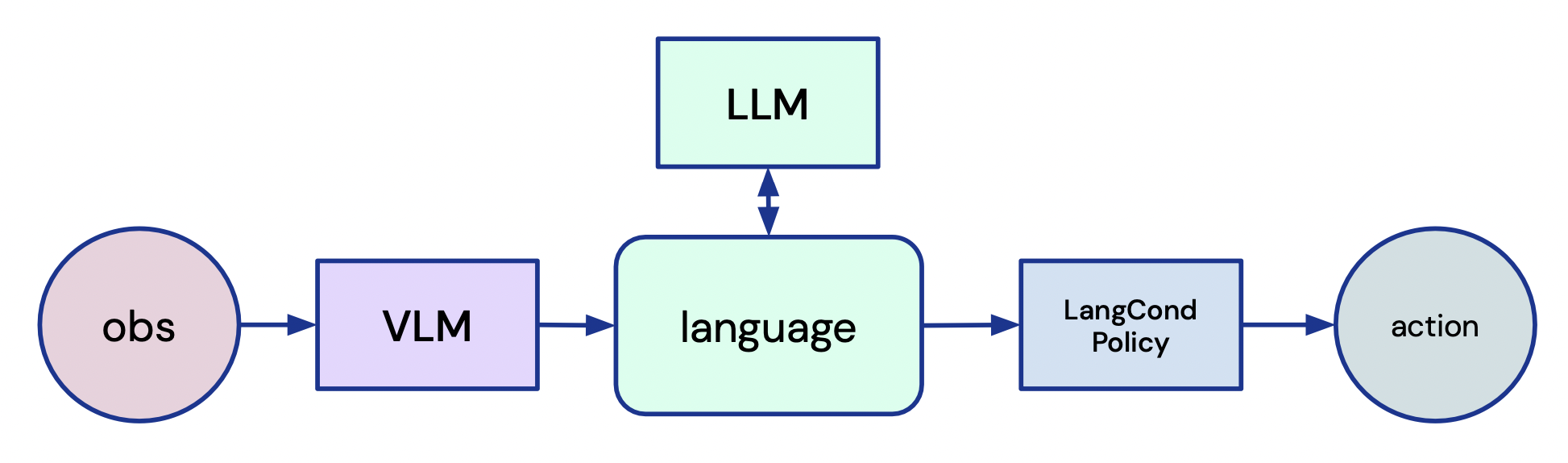
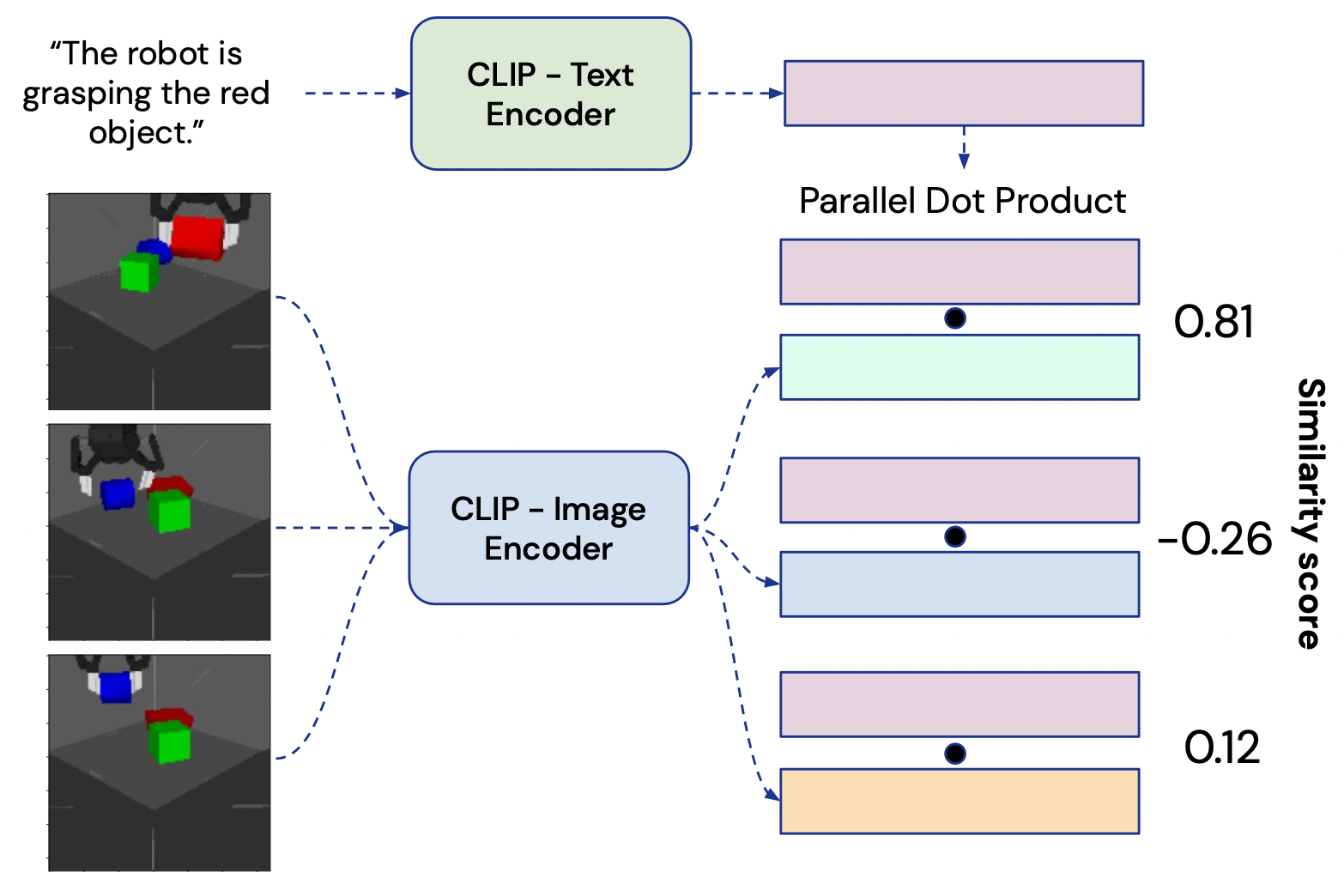
- 관찰을 CLIP 스타일 임베딩으로 기술하여 시각 정보를 텍스트에 매핑함으로써 시각과 언어를 연결한다.
- 추가 도메인 내 학습 없이 작업을 텍스트 서브-목표로 분해하기 위해 미세조정된 LLM(FLAN-T5)을 사용한다.
- RL에서 처음부터 학습한 트랜스포머 기반의 언어-조건화 정책을 통해 언어 서브-목고를 행동으로 바꾼다.
- 관찰을 대조하여 서브-목표 달성을 검증하고 내부 보상을 제공하는 Collect & Infer 루프를 채택한다.
- 공유 버퍼에 데이터를 수집하고 에피소드 후 행동 모방 학습을 수행하는 분산 에이전트 다수(N=1000)를 운용한다.
- VLM 기반 보상 재레이블링 및 CLIP 스타일 그라운딩을 사용하여 과거 경험을 새로운 작업에 연결해 오프라인 데이터 재사용을 가능하게 한다.
- 전문가 비디오 프레임을 VLM을 통해 서브-목표로 매핑하고 해당 기술을 실행함으로써 관찰 학습을 지원한다.
실험 결과
연구 질문
- RQ1기초 모델(LLMs/VLMs)이 희소 보상 환경에서 핵심 RL 문제에 대해 통합된 접근법을 제공할 수 있는가?
- RQ2언어으로 생성된 서브-목표가 손으로 설계된 보상 없이 탐색 및 커리큘럼 생성을 얼마나 효과적으로 이끌 수 있는가?
- RQ3오프라인 경험을 얼마나 재활용하여 로봇 조작의 순차적 과제 학습을 부트스트랩할 수 있는가?
- RQ4학습된 기술을 스케줄링하고 재사용하여 새로운 작업을 해결하고 관찰 학습을 가능하게 할 수 있는가?
주요 결과
- 제시된 프레임워크는 Stack Red on Blue 및 Triple Stack 과제에서 기본 환경 보상만을 사용하는 에이전트보다 학습 속도가 크게 빠르다.
- Triple Stack 과제는 기초가 극심한 희소성으로 인해 학습이 멈춘 상태인 반면 신속한 학습을 보여준다(희소성 > 10^6).
- 단일 프레임워크가 도메인 특화 보상 설계 없이 언어 구동 커리큘럼을 통해 탐색을 가능하게 한다.
- 이전 과제의 오프라인 데이터는 재레이블링 및 재사용되어 새로운 과제를 부트스트랩하고 순차 과제 학습을 가속화한다.
- 비디오를 통한 관찰 학습은 학습한 기술을 서브-목표에 근거하게 하고 새로운 맥락에서 이를 실행하도록 한다.
- 자기 모방과 함께 분산 데이터 수집(N=1000 에이전트)은 샘플 효율성과 학습의 안정성을 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.