[논문 리뷰] Towards Building Multilingual Language Model for Medicine
본 논문은 25.5B 토큰 규모의 다국어 의학 말뭉치 MMedC, 평가 벤치마크 MMedBench, 그리고 MMedLM/MMedLM 2 등 오픈 소스 다국어 의학 LLM을 소개하며, 이는 강력한 성능을 달성하고 MMedBench에서 GPT-4에 필적한다.
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
연구 동기 및 목표
- 언어적으로 다양한 대상을 위해 오픈 소스 다국어 의학 언어 모델을 개발한다.
- 6개 언어에 걸친 자기회귀 학습을 위한 대규모 다국어 의학 말뭉치(MMedC)를 구축한다.
- 다국어 의학 추론 평가를 위한 근거를 포함한 다국어 의학 QA 벤치마크(MMedBench)를 만든다.
- MMedC로 학습된 모델 및 오픈 소스 LLM을 평가하여 다국어 의학 QA와 근거 생성 능력을 평가한다.
제안 방법
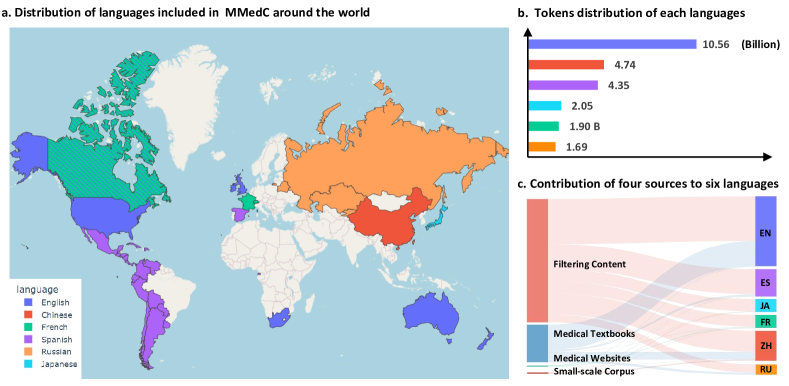
- 네 가지 데이터 소스에서 영어, 중국어, 일본어, 프랑스어, 러시아어, 스페인어에 걸친 25.5B 토큰 이상으로 MMedC를 구성한다.
- 다국어 의학 다지선다형 QA 데이터셋을 모아 MMedBench를 정리하고 GPT-4가 생성한 근거를 보강한다.
- 제로샷, PEFT, 전체 파인튜닝 설정에서 MMedC로 학습된 모델(MMedLM/MMedLM 2)을 포함한 다양한 LLM을 미세조정 및/또는 평가한다.
- 자동 지표(BLEU-1, ROUGE-1, BERT-score)와 인간 평가를 통해 근거 품질을 평가하고 신뢰할 수 있는 평가 방법을 식별한다.
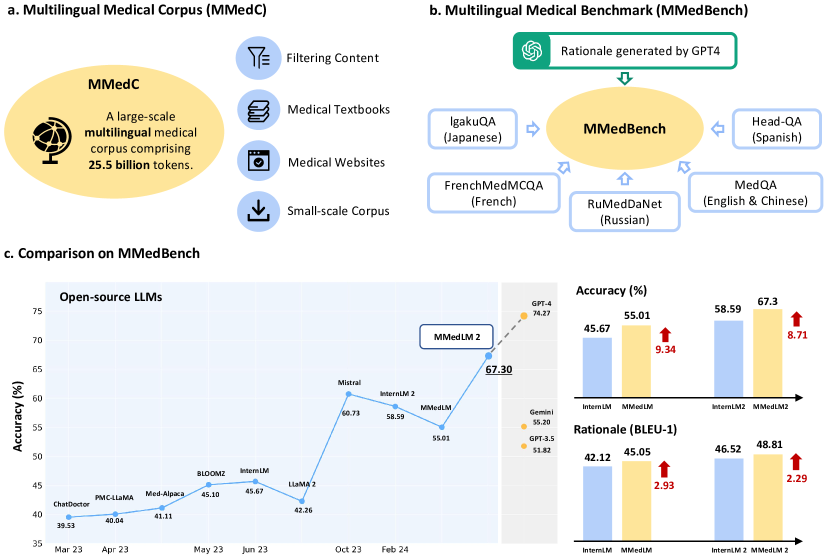
실험 결과
연구 질문
- RQ1다언어로 의학에 초점을 둔 말뭉치가 비영어권 의학 질의에 대해 오픈 소스 LLM을 개선할 수 있는가?
- RQ2MMedC 학습이 언어 간 다국어 의학 QA 및 근거 생성에 어떤 영향을 미치는가?
- RQ3다국어 LLM에서 의학 근거에 대해 인간 판단을 가장 잘 반영하는 평가 지표는 무엇인가?
- RQ4MMedBench에서 오픈 소스 다국어 의학 LLM과 폐쇄형 모델의 비교 성능은 어떠한가?
주요 결과
- MMedC로 학습된 모델(MMedLM, MMedLM 2)은 다수의 설정에서 베이스라인을 능가하고 MMedBench에서 GPT-4에 필적한다.
- 6개 언어에 걸쳐, 다국어 전체 미세조정에서 MMedLM 2는 영어 58.13에서 스페인어 80.01까지 정확도를 달성하고, 다국어 트랙의 평균은 67.30이다.
- 근거 생성은 MMedC 학습으로부터 이점을 얻으며 BLEU-1 및 ROUGE-1 점수의 개선과 인간 평가에서 MMedLM 2를 선호한다.
- ROUGE-1 및 BLEU-1은 MMedBench에서 근거 평가를 위한 신뢰할 수 있는 자동 지표로 확인되며, GPT-4 평점이 인간 판단과 가장 많이 상관하지만 확장성이 떨어진다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.