[논문 리뷰] Towards Coding Social Science Datasets with Language Models
GPT-3은 사회과학 텍스트 코딩에서 합성 코더로 작동하여 인간 코더와 일치하거나 감독 ML과 경쟁하며, 다양한 작업에서 few-shot 프롬프트를 사용한 고효율성을 보인다.
Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
연구 동기 및 목표
- 사회과학 텍스트 코딩의 비용과 변동성을 줄이기 위해 인간 코딩을 대체하거나 보강하기 위해 언어 모델을 활용하자는 동기를 부여합니다.
- 미세 조정 없이 다양한 데이터 세트와 코딩 체계에서 GPT-3의 코딩 능력을 시연합니다.
- GPT-3의 코딩 성능을 인간 코더 및 전통적 감독 학습 방식과 비교합니다.
- 여러 작업에서 GPT-3 코딩의 신뢰도(간재일치)와 효율성(시간/비용)을 평가합니다.
제안 방법
- 코딩 작업을 가르치기 위해 GPT-3에 두세 개의 예시를 포함한 작업별 프롬프트를 제공합니다.
- GPT-3의 출력을 범주형 또는 서수 코드로 변환하고 간재일치 지표를 사용하여 인간 코더와 비교합니다.
- 네 가지 데이터 세트(PP, CAP-Congress, CAP-NYT, TGP)를 사용하여 도메인, 데이터 구조 및 측정 유형에 걸친 코딩을 테스트합니다.
- GPT-3와 인간 간의 합의를 정량화하기 위해 Intraclass Correlation (ICC), 합치된 합의 확률, Fleiss’ kappa를 계산합니다.
- 여러 가능한 범주가 있을 때 모델 편향을 보정하기 위해 GPT-3 확률을 보정합니다(선택적, 약간의 이득).
실험 결과
연구 질문
- RQ1미세 조정 없이 few-shot 프롬프트를 사용해 GPT-3이 인간 코더와 비슷한 성능으로 사회과학 텍스트를 코딩할 수 있는가?
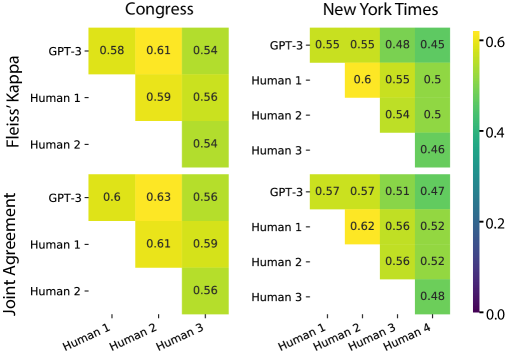
- RQ2다양한 데이터 세트에서 GPT-3의 코딩 신뢰도(ICC, kappa, 공동 합의)가 인간 코더 및 감독 ML 기준선과 어떻게 비교되는가?
- RQ3프롬프트 설계와 예시 선택이 GPT-3의 코딩 정확도와 신뢰도에 의미 있게 영향을 미치는가?
- RQ4대규모 텍스트 코딩에 GPT-3을 사용하는 것의 효율성과 비용 차이는 전통적 인간 또는 ML 접근 방식과 어떻게 비교되는가?
- RQ5GPT-3의 코딩 성능에 있어 도메인별 또는 범주별 패턴이 인간과 비교하여 존재하는가?
주요 결과
- GPT-3은 2–3 예시만으로도 서수 및 범주형 코딩 작업에서 인간 코더의 평균 성능에 맞출 수 있다.
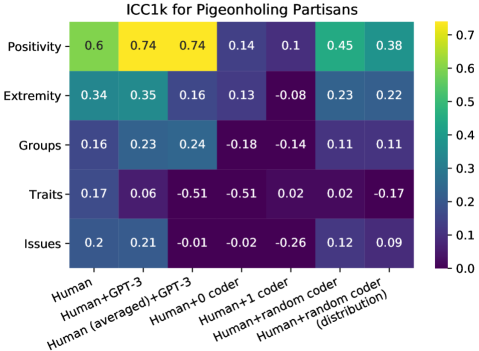
- GPT-3은 인간만 코딩에 비해 ICC를 종종 증가시키지만 모든 범주에서 일관되진 않는다.
- GPT-3의 성능은 감독 ML 대안과 경쟁력이 있으며, 예시가 몇 개에 불과해도 상당한 정확도를 달성한다(예: 4 예시 대 수천 개).
- 네 가지 데이터 세트(PP, CAP-Congress, CAP-NYT, TGP)에서 GPT-3의 인간과의 합의는 많은 경우 인간-인간 합의와 동등하지만 작업 및 범주에 따라 다소 변동이 있다.
- GPT-3 확률 보정은 약간의 정확도 이득을 얻을 수 있다(≈4–5%).
- Guardian Populism 데이터에서 GPT-3은 인간과 약 0.77 ICC를 달성(인간은 0.81)하고 4 예시를 사용하여 인간 코딩 정확도의 약 79%에 도달하는 반면, 수천 개의 라벨링 예시를 가진 백-오브-워드 ML 접근은 약 86%에 도달한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.