[논문 리뷰] Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
본 논문은 생성형 LLMs의 효율적 서빙을 조사하며, 디코딩 기법에서 하드웨어 인지 아키텍처 및 양자화에 이르는 알고리즘 혁신과 시스템 최적화를 다루고, 향후 연구 방향을 제시한다.
In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
연구 동기 및 목표
- LLM 서빙 및 추론의 발전에 대한 포괄적 개요를 제공한다.
- 기술을 기반 접근 방식(알고리즘적 대 시스템)으로 분류하고 강점과 한계를 분석한다.
- 디코딩, 아키텍처 설계, 모델 압축, 저비트 양자화, 병렬 계산, 메모리 관리 및 커널 최적화를 살펴본다.
- 향후 연구와 실천을 안내하기 위해 대표적인 LLM 서빙 프레임워크와 벤치마크를 조사한다.
제안 방법
- 알고리즘 혁신과 시스템 최적화를 구분한 효율적 LLM 서빙 접근법의 분류 체계를 개발한다.
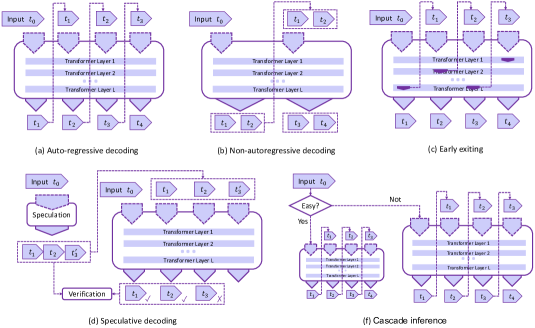
- 디코딩 알고리즘(비자기회귀 디코딩, 추정적 디코딩, 조기 종료, 캐스케이드 추론)과 그 트레이드오프를 분석한다.
- 구성 축소, 어텐션 단순화, 활성화 공유, 조건부 계산, 순환 단위 등의 아키텍처 설계 옵션을 설명한다.
- 지식 distillation, pruning 등의 모델 압축 기법을 검토하고 LLM에의 적용 가능성을 평가한다.
- 저비트 양자화(QAT vs PTQ) 및 추론에 대한 하드웨어 영향에 대해 요약한다.
- 효율적 배포를 위한 병렬 계산 및 메모리 관리 등 시스템 수준의 최적화를 논의한다.
실험 결과
연구 질문
- RQ1LLM 서빙 효율성을 높이기 위해 제안된 주요 알고리즘적 및 시스템 수준 기술은 무엇인가?
- RQ2디코딩 전략, 아키텍처 선택 및 압축/양자화가 추론 속도와 자원 사용에 어떤 영향을 미치는가?
- RQ3하드웨어 플랫폼 전반에 걸친 효율적인 LLM 추론 배치에서 주된 과제와 트레이드오프는 무엇인가?
- RQ4향후 LLM 서빙 연구 및 시스템 설계에서 가장 유망해 보이는 방향은 무엇인가?
주요 결과
- 본 조사는 LLM 서빙을 위한 알고리즘 혁신과 시스템 최적화의 두 부분으로 구성된 분류를 제공합니다.
- 탐구된 디코딩 알고리즘에는 비자기회귀 디코딩, 추정적 디코딩, 조기 종료, 캐스케이드 추론을 포함하며, 트레이드오프와 검증 보장에 대한 논의가 있다.
- 아키텍처 설계 접근은 구성 축소, 어텐션 단순화, 활성화 공유, 조건부 계산, 순환 단위 등의 아키텍처 설계 옵션을 다룬다.
- 지식 distillation 및 pruning과 같은 모델 압축 기법이 LLM 추론에 대한 적용 가능성과 실질적 이득에 대해 검토된다.
- 저비트 양자화(QAT vs PTQ)와 그 하드웨어 영향이 분석되며, 잠재적 대기 시간 및 처리량 이점과 확장 효과가 포함된다.
- 또한 시스템 수준의 전략으로 병렬 계산, 메모리 관리, 커널 최적화가 실무에서의 효율성 향상을 실현하는 데 중요하다고 논의한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.