[논문 리뷰] Towards Generalist Biomedical AI
이 논문은 14-task 다중모달 생의학 벤치마크인 MultiMedBench와 단일 일반ist 다중모달 모델인 Med-PaLM M을 소개합니다. 이 모델은 태스크별 특화 파인튜닝 없이 모든 태스크에서 SOTA 또는 근사 SOTA 성능을 달성하며, 제로샷 일반화, 태스크 전이 및 흉부 X선 보고서의 방사선학자 수준 평가에 대한 근거도 제시합니다.
Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
연구 동기 및 목표
- 다양한 데이터 모달리티와 태스크를 통합적으로 처리할 수 있는 일반ist 생의학 AI 시스템 개발의 필요성을 제시합니다.
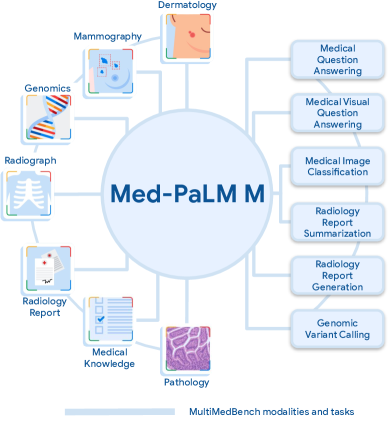
- 텍스트, 영상, 그리고 유전체를 포함하는 14개의 태스크를 다루는 다양하고 포괄적인 벤치마크인 MultiMedBench를 만들고 공개합니다.
- 태스크별 파인튜닝 없이도 다중 생의학 태스크를 해결하는 단일 모델로 Med-PaLM M을 제안합니다.
- 전문가 모델에 대한 강력한 성능을 입증하고, 제로샷 일반화 및 임상 평가를 탐색합니다.
제안 방법
- vision-language 데이터에 대해 사전학습된 PaLM-E 기반 일반ist 아키텍처를 생의학 데이터로 미세조정합니다.
- 태스크별 프롬프트와 원샷 예제를 활용한 지시어 튜닝으로 다양한 태스크를 단일 출력 공간으로 통합합니다.
- 이미지 토큰을 텍스트와 함께 다중모달 맥락에서 교차시키고 태스크 데이터 규모에 비례하는 혼합 비율로 MultiMedBench에서 엔드투엔드 학습을 수행합니다.
- 언어 중심 및 다중모달 추론 태스크에 대한 스케일링 효과를 연구하기 위해 모델 규모(12B, 84B, 562B)를 다각도로 평가합니다.
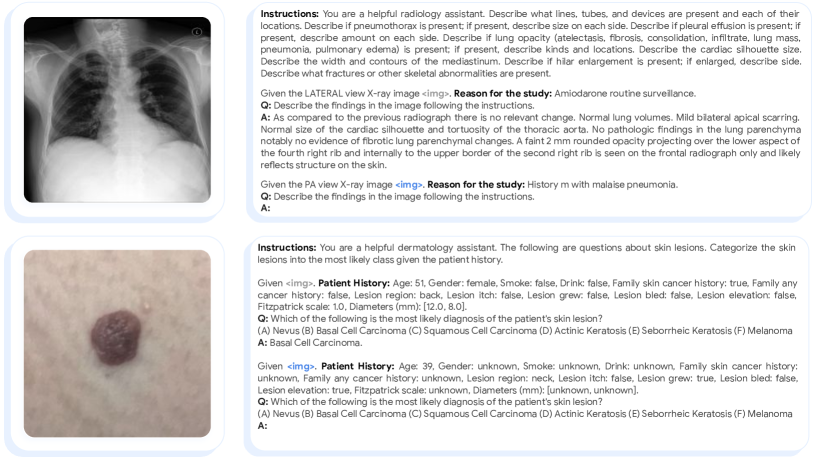
- MIMIC-CXR에서 방사선의학자 평가를 수행하고 인간 기준과 비교합니다.
실험 결과
연구 질문
- RQ1다양한 생의학 태스크에서 학습된 단일 다중모달 모델이 전문가 모델에 비해 경쟁력 있거나 우수한 성능을 내는가?
- RQ2모델 규모를 키우면 언어 중심 및 다중모달 추론 태스크의 성능이 정적 이미지 분류 태스크보다 더 향상되는가?
- RQ3일반ist 생의학 AI에서 제로샷 일반화 및 흥미로운 다중모달 의학 추론의 증거가 있는가?
- RQ4모델 규모에 따라 AI가 생성한 흉부 X선 보고서에 대한 방사선의학자 평가가 인간 기준과 어떻게 비교되는가?
- RQ5일반ist 모델이 생의학 영역 내의 태스크 간에 긍정적 전이 transfer를 보여줄 수 있는가?
주요 결과
- Med-PaLM M은 모든 MultiMedBench 태스크에서 SOTA를 매칭하거나 능가하며, 종종 단일 가중치 세트로 전문 모델을 능가합니다.
- 흉부 X선 보고서 생성은 MIMIC-CXR에서 소형 F1 기준으로 이전 SOTA보다 8% 이상 개선됩니다.
- Slake-VQA에서 Med-PaLM M은 BLEU-1 및 F1 지표에서 이전 SOTA를 10% 이상 상회합니다.
- 제로샷 및 등장하는 능력이 관찰되며, 제로샷 의료 추론 및 새로운 개념에 대한 일반화가 나타납니다.
- 방사선의학자 평가에 따르면 Med-PaLM M 보고서는 최대 40.50%의 사례에서 선호되며, 최상위 모델은 보고서당 임상적으로 중요한 오류가 0.25건입니다.
- 모델 규모 확장은 언어 중심 및 시각적 추론 태스크에서 유의미한 이점을 보이는 반면, 일부 영상 중심 태스크에서는 수익이 감소합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.