[논문 리뷰] Towards Generalist Foundation Model for Radiology by Leveraging Web-scale 2D&3D Medical Data
RadFM은 MedMD와 RadMD를 도입하여 시각적으로 조건화된 방사선학 기초 모델을 훈련하고, RadBench에서 평가되며, 여러 방사선학 작업에서 공개 기반선 baselines를 능가한다.
In this study, we aim to initiate the development of Radiology Foundation Model, termed as RadFM. We consider the construction of foundational models from three perspectives, namely, dataset construction, model design, and thorough evaluation. Our contribution can be concluded as follows: (i), we construct a large-scale Medical Multi-modal Dataset, MedMD, which consists of 16M 2D and 3D medical scans with high-quality text descriptions or reports across various data formats, modalities, and tasks, covering over 5000 distinct diseases. To the best of our knowledge, this is the first large-scale, high-quality, medical visual-language dataset, with both 2D and 3D scans; (ii), we propose an architecture that enables visually conditioned generative pre-training, i.e., allowing for integration of text input with 2D or 3D medical scans, and generate responses for diverse radiologic tasks. The model was initially pre-trained on MedMD and subsequently fine-tuned on the domain-specific dataset, which is a radiologic cleaned version of MedMD, containing 3M radiologic visual-language pairs, termed as RadMD; (iii), we propose a new evaluation benchmark, RadBench, that comprises five tasks, including modality recognition, disease diagnosis, visual question answering, report generation and rationale diagnosis, aiming to comprehensively assess the capability of foundation models in handling practical clinical problems. We conduct both automatic and human evaluation on RadBench, in both cases, RadFM outperforms existing multi-modal foundation models, that are publicaly accessible, including Openflamingo, MedFlamingo, MedVInT and GPT-4V. Additionally, we also adapt RadFM for different public benchmarks, surpassing existing SOTAs on diverse datasets. All codes, data, and model checkpoint will all be made publicly available to promote further research and development in the field.
연구 동기 및 목표
- 방사선학에서 기초 모델용 대규모 다중 모달 의학 데이터 부족 문제를 해결한다.
- 대규모의 고품질 방사선학 중심 다중 모달 데이터셋(MedMD)과 깨끗한 파인튜닝 하위집합(RadMD)을 구축한다.
- 2D 및 3D 의학 이미지와 텍스트를 다룰 수 있는 통합된 시각적으로 조건화된 생성 모델(RadFM)을 개발한다.
- 모달리티 인식, 질병 진단, VQA, 보고서 생성 및 근거 진단을 평가하기 위한 포괄적 평가 벤치마크(RadBench)를 확립한다.
- 기존 공개 다중 모달 기초 모델 대비 RadFM의 성능 향상을 시연하고 다른 벤치마크에 대한 적응력을 입증한다.
제안 방법
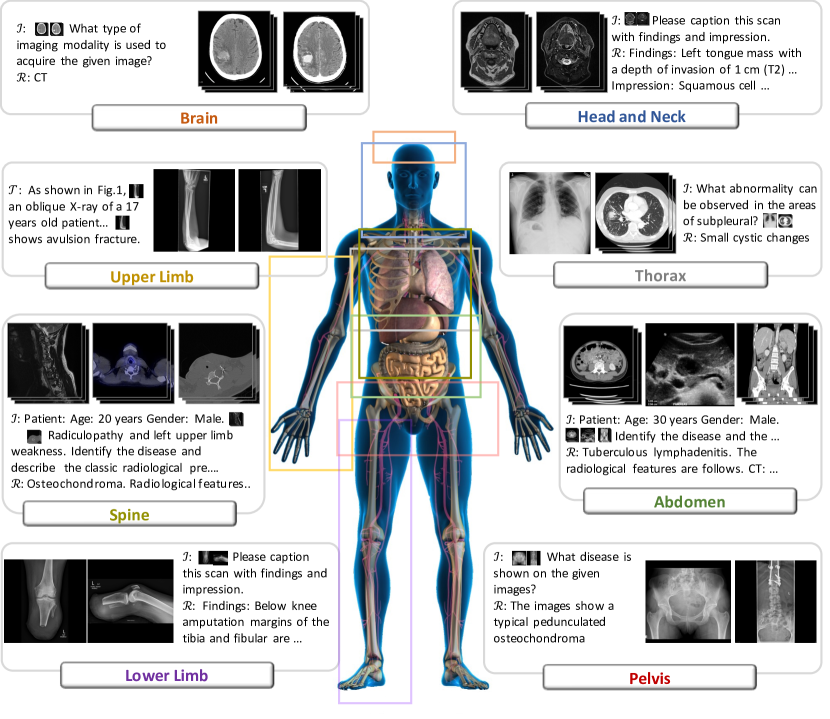
- 16M 2D/3D 방사선 스캔과 17개 시스템 및 5000+개의 질병에 걸친 고품질 텍스트 캡션 또는 보고서를 포함하도록 MedMD를 구성한다.
- 도메인 특화 파인튜닝을 위한 3M 방사선학 중심 시각-언어 데이터셋으로 MedMD를 필터링하여 RadMD를 생성한다.
- 3D ViT 시각 인코더, Perceiver 집계 모듈, 텍스트 생성을 위한 LLM을 활용하는 시각적으로 조건화된 자기회귀 모델 RadFM을 제안한다.
- 2D 이미지를 4 슬라이스로 패딩하고 3D 패치를 위한 학습 가능한 3D 위치 임베딩을 사용하여 다중 이미지 입력을 가능하게 한다.
- 사이에 텍스트 프롬프트가 삽입된 시각 임베딩을 집계하기 위해 Perceiver 기반 융합을 사용하고 음의 로그우도(negative log-likelihood) 목적함수로 학습한다.
- 의학 용어와 관련 프롬프트를 강조하기 위해 토큰별 가중치를 적용하고, 삽입형(interleaved)과 시각-지시(visual-instruction) 데이터셋에서 다르게 적용한다.
- 출력을 형성하기 위해 모달리티 인식, 질병 진단, VQA, 보고서 생성 및 근거 진단에 대해 작업 특화 프롬프트를 활용한다.
![Figure 1 : The general comparison between RadFM and different SOTA methods, i.e. , OpenFlamingo [ 1 ] , MedVInT [ 55 ] , Med-Flamingo [ 31 ] and GPT-4V [ 37 ] . On the left we plot the radar figure of the five models, on the average of different automatic metrics, the coordinate axes are logarithmiz](https://ar5iv.labs.arxiv.org/html/2308.02463/assets/x1.png)
실험 결과
연구 질문
- RQ1단일 일반모델이 2D/3D 입력과 자연어 출력을 사용하여 모달리티 인식, 질병 진단, VQA, 보고서 생성, 근거 진단 등 다양한 방사선 작업을 효과적으로 처리할 수 있는가?
- RQ2대규모 MedMD 데이터셋으로 학습한 뒤 Radiology 중심 파인튜닝(RadMD)을 거치면 기존 공개 다중 모달 방사선 모델 대비 우수한 성능을 보이는가?
- RQ3RadFM은 포괄적인 방사선학 특화 벤치마크(RadBench)와 RadBench를 넘어선 공개 벤치마크에서 어떤 성능을 보이는가?
- RQ43D ViT 인코더, Perceiver 융합, LLM 디코더의 어떤 아키텍처 선택이 2D/3D 방사선 데이터와 다양한 작업을 통합하는 데 기여하는가?
- RQ5데이터 품질과 프롬프트 전략이 방사선 작업 전반의 모델 성능에 어떤 영향을 미치는가?
주요 결과
- RadFM은 RadBench에서 자동 평가와 인간 평가 모두에서 공개 이용 가능 대형 다중 모달 기초 모델(OpenFlamingo, MedFlamingo, MedVInT, GPT-4V)보다 우수한 성능을 보인다.
- RadFM은 RadBench 외의 공개 벤치마크에 적용했을 때도 강한 일반화 성능을 시현한다.
- RadFM은 2D와 3D 방사선 이미지를 단일 아키텍처로 통합한 최초의 기초 모델이다.
- 모델은 다중 이미지를 입력으로 지원하고 다양한 방사선 작업에 대해 자연어 출력을 생성한다.
- 학습 파이프라인은 광범위한 MedMD 사전 학습 데이터셋과 방사선학 중심 RadMD 파인튜닝 세트를 결합하여 강한 도메인 정렬을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.