[논문 리뷰] Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
LENS는 모듈형 비전 모듈로부터 얻은 풍부한 텍스트 설명을 이용해 frozen LLM이 시각 및 시각-언어 작업을 수행하도록 하여 멀티모달 사전 학습 없이도 제로샷 성능에서 경쟁력을 갖춘다.
We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
연구 동기 및 목표
- 멀티모달 사전 학습 없이 frozen LLM으로 시각적 추론을 가능하게 하고 이를 촉진한다.
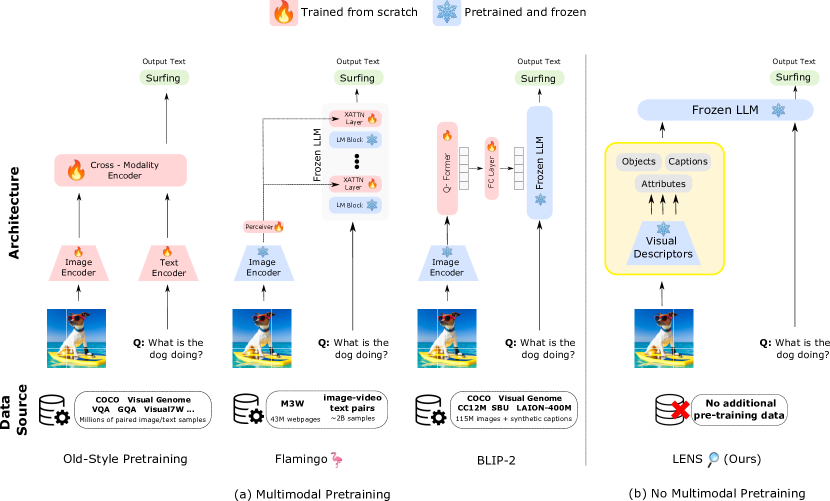
- 비전 모듈을 frozen LLM과 추론 엔진으로 연결하는 모듈형 아키텍처(LENS)를 제안한다.
- 다양한 데이터셋에서 객체 인식 및 시각-언어 과제에 대해 LENS가 제로샷 성능에서 경쟁력을 보임을 보인다.
제안 방법
- 이미지를 묘사하기 위한 시각 어휘(태그와 속성)를 정의한다.
- 세 가지 비전 모듈(Tag, Attributes, Intensive Captioning)을 사용해 이미지로부터 텍스트 설명을 생산한다.
- 연결된 텍스트 설명들을 frozen LLM에 입력해 객체 인식 및 V&L 작업을 수행한다.
- 비전 모듈 출력과 사용자 쿼리 및 짧은 최종 답변 단서를 결합하는 작업 특화 프롬프트를 설계한다.
- 제로샷 및 소수샷 객체 인식과 제로샷 VQA/OK-VQA/혐오 이미지 벤치마크에서 다중모달 베이스라인과 비교하여 평가한다.
실험 결과
연구 질문
- RQ1독립적인 비전 모듈로부터의 텍스트 설명에 의해 안내되는 frozen LLM이 멀티모달 사전 학습 없이도 경쟁력 있는 시각 및 시각-언어 과제를 수행할 수 있는가?
- RQ2다른 비전 모듈들(Tag, Attributes, captions)의 기여가 제로샷 객체 인식 및 V&L 추론 성능에 어떻게 기여하는가?
- RQ3표준 시각 벤치마크 및 VQA 스타일 작업에서 LENS가 공동 사전학습된 다중모달 모델과 어떻게 비교되는가?
- RQ4LLM 기반 추론을 위해 텍스트 기반 시각 정보를 가장 잘 활용하는 프롬프트 및 프롬프트 구성 요소는 무엇인가?
주요 결과
| 모델 | # 학습 가능한 매개변수 | VQAv2 (test-dev) | OK-VQA (test) | Rendered-SST2 (test) | 혐오 밈 (dev) |
|---|---|---|---|---|---|
| Kosmos-1 | 1.6B | 51.0 | - | 67.1 | 63.9 |
| Flamingo 3B | 1.4B | 49.2 | 41.2 | - | 53.7 |
| Flamingo 9B | 1.8B | 51.8 | 44.7 | - | 57.0 |
| Flamingo 80B | 10.2B | 56.3 | 50.6 | - | 46.4 |
| BLIP-2 ViT-L FlanT5 XL | 103M | 62.3 | 39.4 | - | - |
| BLIP-2 ViT-g FlanT5 XXL | 108M | 65.0 | 45.9 | - | - |
| LENS Flan-T5 XL | 0 | 57.9 | 32.8 | 83.3 | 58.0 |
| LENS Flan-T5 XXL | 0 | 62.6 | 43.3 | 82.0 | 59.4 |
- LENS는 Kosmos 및 Flamingo와 같은 엔드-투-엔드 사전학습 모델에 비견될 제로샷 객체 인식 성능을 달성한다.
- 시각-언어 과제에서 Flan-T5 XXL를 사용하는 LENS는 VQA 2.0 및 관련 벤치마크에서 여러 다중모달 베이스라인과 비교해 우수하거나 경쟁력 있는 결과를 얻는다.
- 태그와 속성 정보를 결합하면 단일 비전 모듈을 사용하는 것보다 객체 인식에서 상호 보완적 이점을 제공한다.
- 집약적 캡션은 VQA 결과를 향상시키며 특정 캡션 수를 넘어서면 수익이 감소하고, OCR 기반 프롬프트는 태그 및 속성과 결합될 때 혐오 밈 작업에서 도움이 된다.
- LENSOO(최적 variant)는 멀티모달 사전학습을 피하면서도 강력한 제로샷 성능을 보여주고, LLM의 모듈형 추론 기반 활용의 효과를 강조한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.