[논문 리뷰] Towards Mitigating Hallucination in Large Language Models via Self-Reflection
본 연구는 의학 분야의 생성형 QA에서의 환각 현상을 분석하고, 배경 지식과 답변을 생성, 평가, 개선하는 대화형 자기 성찰 루프를 제안하여 여러 LLM 및 데이터셋에 걸친 환각을 낮춘다.
Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
연구 동기 및 목표
- 여러 LLM과 의학 QA 데이터세트를 사용하여 의료 생성형 QA 시스템에서의 환각의 발생률과 특성을 조사한다.
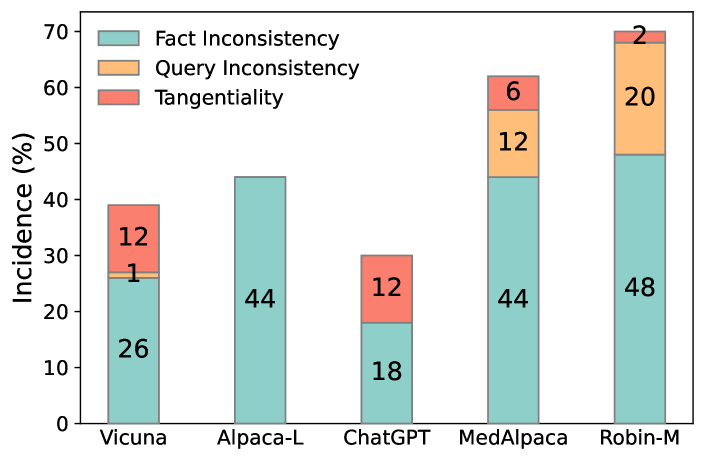
- 의료 답변에서 사실 불일치, 질의 불일치, 주변성(tangentiality) 등의 환각 원인을 조사한다.
- 사실적 신뢰성을 향상시키기 위해 지식과 답변을 반복적으로 생성, 평가, 다듬는 자기 성찰 워크플로우를 제안하고 평가한다.
- 매개변수 수가 다른 모델(7B 및 175B)에 걸친 접근법의 일반화 가능성과 확장성을 평가한다.
제안 방법
- 사실적 지식 획득, 지식 일관 답변, 질문-함의 답변의 세 루프를 갖춘 반복적 자기 성찰 파이프라인을 제안한다.
- 사실성 점수 매기기를 사용하여 생성된 배경 지식을 평가하고 사실성이 임계값에 도달할 때까지 다듬기를 촉구하는 생성-점수-다듬기 사이클을 활용한다.
- 정제된 지식을 조건으로 답변을 생성한 다음 CTRLEval을 사용하여 배경 지식과의 일관성을 평가하고 필요하면 다듬기를 촉구한다.
- 답변과 질문 간의 함의 평가를 문장 단위 검사를 이용하여 포함 가능성을 보장하도록 도입한다.
- 자동 지표(MedNLI, CtrlEval, F1, ROUGE-L 등)와 인간 평가(질의 일관성, 주변성, 사실 일관성)를 모두 평가한다.

실험 결과
연구 질문
- RQ1일반 LLM과 의학 도메인 LLM 전반에 걸친 의료 GQA에서의 환각 발생률과 특성은 무엇인가?
- RQ2대화형 자기 성찰 루프가 의학 QA에서 환각을 줄이고 사실성, 일관성, 그리고 함의를 개선할 수 있는가?
- RQ3제안된 방법이 서로 다른 매개변수 수의 모델과 여러 의학 QA 데이터세트에서 어떻게 수행되는가?
- RQ4정제, 측면 설명, 명시적 점수가 루프의 효과성에 어떤 기여를 하는가?
주요 결과
- 자기 성찰 루프는 생성된 의학 QA 응답에서 기초치 대비 질의 불일치, 주변성 및 사실 불일치를 감소시킨다.
- 본 접근법은 여러 모델과 다섯 개의 의학 데이터세트에서 MedNLI 및 관련 함의 및 일관성 지표를 향상시킨다.
- 휴먼 평가에서 루프를 사용할 때 환각 감소와 제공된 지식과의 일관성 향상을 보였다.
- 선별 연구는 정제 단계, 명시적 측면 설명 및 점수 신호가 더 나은 사실성 및 정렬에 기여함을 시사한다.
- 본 방법은 다양한 의학 QA 작업에서 7B 및 175B 모델에 대해 일반화 가능성과 확장성을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.