[논문 리뷰] Towards Personalized Federated Learning via Heterogeneous Model Reassembly
이 논문은 pFedHR를 도입합니다. 서버에서 후보 모델을 재조합하고 개인화된 모델과 클라이언트를 매칭하여 개인정보를 유출하지 않고도 이질적인 클라이언트 모델을 갖춘 개인화 연합학습을 가능하게 하는 프레임워크입니다. 자동으로 다양한 개인화 후보를 생성하고 계층 재접합과 유사도 기반 선택을 통해 공개 데이터 분포 문제를 완화합니다.
This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.
연구 동기 및 목표
- Federated learning에서 클라이언트가 서로 다른 네트워크 구조를 가진 모델의 이질성 해결.
- 개인 데이터를 공유하지 않고도 개인화 모델을 생성하고 선택하는 서버 측 메커니즘 개발.
- 공개 데이터 분포에 대한 의존성 감소 및 이질적 모델 재조합을 통한 개인화 강화.
- IID 및 Non-IID 설정에서 다수의 데이터셋에 걸쳐 베이스라인 대비 우수한 성능 시연.
제안 방법
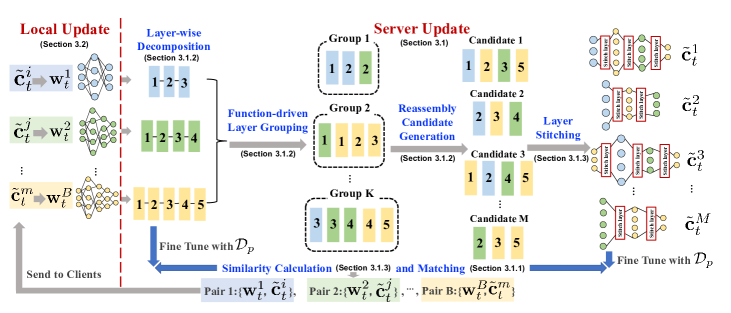
- 각 클라이언트 모델을 레이어로 분해하고 기능별로 그룹화하며 CKA 기반 유사도 지표를 사용.
- 레이어 단위 분해, 기능 주도 그룹화, 그리고 레이어 스티칭으로 재조합하여 M개의 이질적 모델 후보 생성.
- 공개적으로 이용 가능한 데이터를 사용하고 로짓의 코사인 유사도와 함께 미세조정 후 각 클라이언트 모델과 스티치된 후보 간의 유사성 계산.
- 각 클라이언트에 대해 가장 잘 매칭된 후보를 해당 라운드의 개인화 모델로 선택하여 지식 증류를 통한 클라이언트 측 학습의 가이드로 사용.
- 공개 데이터를 사용하여 소수의 에폭으로 스티치된 후보를 파인튜닝하여 부정적 효과를 제한; 지도 데이터가 있거나 없더라도 공개 데이터를 가이드로 사용하되 파라미터 공유를 피함.
- 클라이언트 업데이트는 지식 증류를 사용하여 개인화 모델을 로컬 학습에 통합하고 클라이언트 데이터 프라이버시를 보존.

실험 결과
연구 질문
- RQ1이질적 클라이언트 모델이Private data를 노출하지 않고 서버 측 모델 재조합으로 효과적으로 개인화될 수 있는가?
- RQ2이질적 아키텍처를 가진 FL에서 정보가 풍부하고 다양한 개인화 모델 후보를 자동으로 생성하고 클라이언트에 매칭하는 방법은?
주요 결과
| 공개 데이터 | 데이터셋 | MNIST IID | MNIST Non-IID | SVHN IID | SVHN Non-IID | CIFAR-10 IID | CIFAR-10 Non-IID |
|---|---|---|---|---|---|---|---|
| Labeled | MNIST | 93.08% | 91.44% | 81.55% | 78.39% | 68.22% | 66.13% |
| Labeled | SVHN | 94.10% | 93.27% | 81.94% | 81.06% | 72.69% | 70.27% |
| Labeled | pFedHR | 94.55% | 94.41% | 83.68% | 83.40% | 73.88% | 71.74% |
| Unlabeled | FedKEMF | 93.01% | 91.66% | 80.41% | 79.33% | 67.12% | 66.93% |
| Unlabeled | FCCL | 93.62% | 92.88% | 82.03% | 79.75% | 68.77% | 66.49% |
| Unlabeled | pFedHR | 93.89% | 93.76% | 83.15% | 80.24% | 69.38% | 68.01% |
- pFedHR가 MNIST, SVHN, CIFAR-10에서 IID 및 Non-IID 설정의 이질적 모델 실험에서 최첨단 성능을 달성.
- 라벨링된 공개 데이터가 있을 때, pFedHR는 모든 데이터셋과 설정에서 일관되게 기준선보다 우수. 예: MNIST: 93.08% vs 93.27% (FedGH) 및 94.55% (pFedHR); SVHN: 81.55% (FedMD) vs 83.68% (pFedHR); CIFAR-10: 68.22% (FedMD) vs 73.88% (pFedHR).
- 라벨이 없는 공개 데이터일 때도 pFedHR은 경쟁적이고 종종 기준선보다 우수, 예: MNIST 93.89% IID vs 93.01% (FedKEMF); SVHN 83.15% IID vs 82.03% (FCCL); CIFAR-10 69.38% IID vs 68.77% (FCCL).
- 프레임워크는 공개 데이터 분포가 클라이언트 데이터와 다를 때도 성능을 유지하여 공개 데이터 민감성에 대한 강건성 보임.
- 군집(K) 수를 늘리면 성능이 향상되나 생성된 후보의 수 M과의 균형 필요.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.