[논문 리뷰] Towards Predicting Equilibrium Distributions for Molecular Systems with Deep Learning
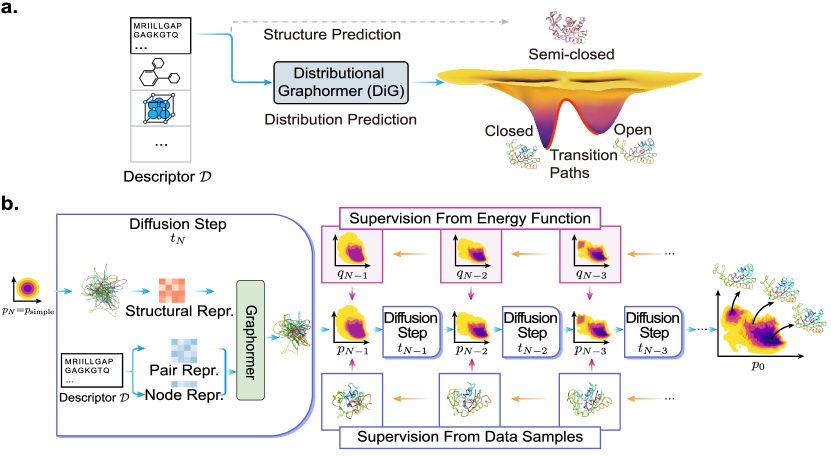
DiG는 분자 서술자에 조건화된 확산 기반 Graphormer 프레임워크로 평형 분포를 예측하고, 다양한 형태의 입체구조를 효율적으로 샘플링한다.
Advances in deep learning have greatly improved structure prediction of molecules. However, many macroscopic observations that are important for real-world applications are not functions of a single molecular structure, but rather determined from the equilibrium distribution of structures. Traditional methods for obtaining these distributions, such as molecular dynamics simulation, are computationally expensive and often intractable. In this paper, we introduce a novel deep learning framework, called Distributional Graphormer (DiG), in an attempt to predict the equilibrium distribution of molecular systems. Inspired by the annealing process in thermodynamics, DiG employs deep neural networks to transform a simple distribution towards the equilibrium distribution, conditioned on a descriptor of a molecular system, such as a chemical graph or a protein sequence. This framework enables efficient generation of diverse conformations and provides estimations of state densities. We demonstrate the performance of DiG on several molecular tasks, including protein conformation sampling, ligand structure sampling, catalyst-adsorbate sampling, and property-guided structure generation. DiG presents a significant advancement in methodology for statistically understanding molecular systems, opening up new research opportunities in molecular science.
연구 동기 및 목표
- 분자 시스템에 대해 단일 구조가 아닌 평형 분포를 예측해야 하는 필요성을 동기 부여한다.
- 평형 분포를 근사하고 다양하며 화학적으로 타당한 구조를 샘플링할 수 있는 딥러닝 프레임워크를 제안한다.
- 상태 밀도 추정과 속성 가이드 기반 생성을 통한 역설계 지원을 가능하게 한다.
제안 방법
- 분자 서술자에 조건화된 목표 평형 분포로 간단한 분포를 변환하기 위해 확산 기반 생성을 수행하는 Distributional Graphormer (DiG)를 도입한다.
- 목표 분포에서 간단한 가우시안으로 이동시키기 위해 순방향 Langevin 확산을 사용하고, Graphormer를 기반으로 한 점수 모델 s^θ_D,t(R)로 역 확산 과정을 학습한다.
- 데이터 기반 점수 또는 에너지 함수 E_D를 활용하는 물리정보 기반 확산 사전 학습(PIDP)을 이용한 단계별 독립 감독으로 점수 모델을 학습한다.
- 역분해 단계의 이산화(discretized reverse steps)를 통해 R_0 샘플을 평형 분포에서 얻도록 확산 프로세스를 점수 매칭 및 확산 이론에 기반한다.
- 과정을 추적하여 확산 경로를 따라 밀도 추정하고 자유에너지 및 엔트로피와 같은 열역학적 양을 계산 가능하게 한다.
- 타깃 속성 c로 점수를 조건화하여 조건부 분포 q_D,t(R|c)를 베이즈 규칙 기반의 조정을 통해 변환함으로써 역설계를 지원한다.
실험 결과
연구 질문
- RQ1디퓨전 기반 생성 모델이 서술자로부터 분자 시스템의 평형 분포를 근사할 수 있는가?
- RQ2DiG가 MD 시뮬레이션 및 실험 구조와 비교하여 다양하고 기능적으로 관련된 구성을 얼마나 잘 샘플링하는가?
- RQ3DiG가 리간드 결합 포즈 샘플링 및 촉매-흡착체 흡착 분포를 기존 방법과 비견할 만한 정확도로 수행할 수 있는가?
- RQ4평형 데이터가 드문 경우 물리정보 기반 사전학습(PIDP)이 학습을 어떠하게 보강할 수 있는가?
- RQ5DiG가 타깃 속성에 조건화하여 속성 가이드(역) 설계를 지원할 수 있는가?
주요 결과
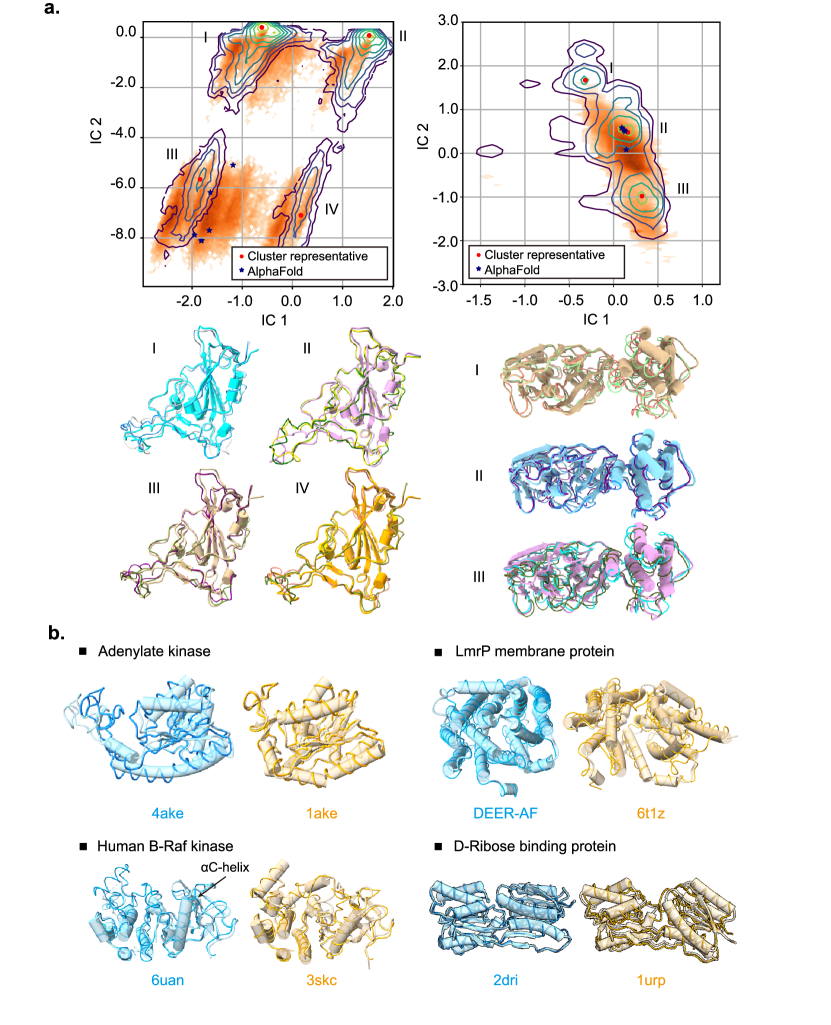
- DiG는 밀리초 MD 시뮬레이션에서 관찰된 분포와 유사하고 알려진 기능적 상태와 일치하는 다양한 단백질 구성을 생성할 수 있다.
- DiG는 결정구조와 높은 유사성을 보이는 정확도(RMSD) 분포로 포켓 내 리간드 구조를 생성하며, 많은 사례에서 최대 근접치가 약 ~2.0 Å 이내로 달성된다.
- DiG는 다양한 흡착 자리에서 DFT 유도 기준선과 근접하게 일치하는 촉매-흡착체 흡착 구성을 샘플링할 수 있다.
- 물리정보 확산 사전학습(PIDP)은 사전학습 중 에너지 함수를 활용하여 평형 데이터가 드문 상황에서도 점수 학습을 가능하게 한다.
- DiG는 속성 가이드 구조 생성을 위한 조건부 생성을 지원하여 큰 조건부 데이터 세트를 요구하지 않고도 역설계를 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.