[논문 리뷰] Towards Translating Real-World Code with LLMs: A Study of Translating to Rust
이 논문은 Flourine이라는 엔드투엔드 번역 도구를 사용하여 실제 C/Go 코드를 Rust로 번역하는 것을 다섯 개의 LLM과 408개의 벤치마크(총 8160개의 실험)에서 연구하고, 모델별 번역 성공률을 보고합니다.
Large language models (LLMs) show promise in code translation - the task of translating code written in one programming language to another language - due to their ability to write code in most programming languages. However, LLM's effectiveness on translating real-world code remains largely unstudied. In this work, we perform the first substantial study on LLM-based translation to Rust by assessing the ability of five state-of-the-art LLMs, GPT4, Claude 3, Claude 2.1, Gemini Pro, and Mixtral. We conduct our study on code extracted from real-world open source projects. To enable our study, we develop FLOURINE, an end-to-end code translation tool that uses differential fuzzing to check if a Rust translation is I/O equivalent to the original source program, eliminating the need for pre-existing test cases. As part of our investigation, we assess both the LLM's ability to produce an initially successful translation, as well as their capacity to fix a previously generated buggy one. If the original and the translated programs are not I/O equivalent, we apply a set of automated feedback strategies, including feedback to the LLM with counterexamples. Our results show that the most successful LLM can translate 47% of our benchmarks, and also provides insights into next steps for improvements.
연구 동기 및 목표
- Hand-written 테스트 케이스 없이 번역을 검증하는 엔드투엔드 Rust 번역 도구 Flourine을 개발한다.
- LLMs가 C/Go에서 실제 코드를 Rust로 번역하고 동작을 유지하는 능력을 평가한다.
- 피드백 전략과 컴파일 주도 수정이 정확한 번역을 달성하는 데 얼마나 효과적인지 조사한다.
- 소스와 번역된 프로그램 간의 입출력 동등성을 검증하는 교차 언어 차등 퍼징 프레임워크를 제공한다.
- 재현성을 보장하기 위해 오픈 소스 데이터, 벤치마크 및 결과를 제공한다.
제안 방법
- Flourine은 LLM으로부터 후보 Rust 번역을 얻고, 컴파일 오류를 수정한 다음, 교차 언어 차등 퍼저를 통해 I/O 동등성을 검증하며 반복적으로 번역을 개선한다.
- 퍼저는 Go/C 소스와 Rust 간의 프로그램 상태를 JSON 직렬화를 통해 매핑하여 사전에 테스트가 존재하지 않아도 입력/출력 동등성 검사를 가능하게 한다.
- 피드백 전략은 퍼저가 반례를 찾았을 때 번역을 다듬는 데 사용된다. 전략으로는 재시작, 힌트 재시작, 반례 기반 수정, 대화형 수리가 포함된다.
- 벤치마크는 7개 실제 프로젝트(C 및 Go)에서 실 컴파일 가능 Rust 등가 단위로 추출되며 1–25개의 함수와 다양한 도메인을 포함한다.
- 실험은 408개의 벤치마크와 다섯 개의 LLM(GPT-4-Turbo, Claude 2.1, Claude 3 Sonnet, Gemini Pro, Mixtral)에서 총 8160회의 실행이다.
- LLMs는 제로샷 번역 작업으로 프롬프트된 다음 Rust 컴파일러 오류에 의해 안내된 컴파일 수정 단계가 뒤따른다.
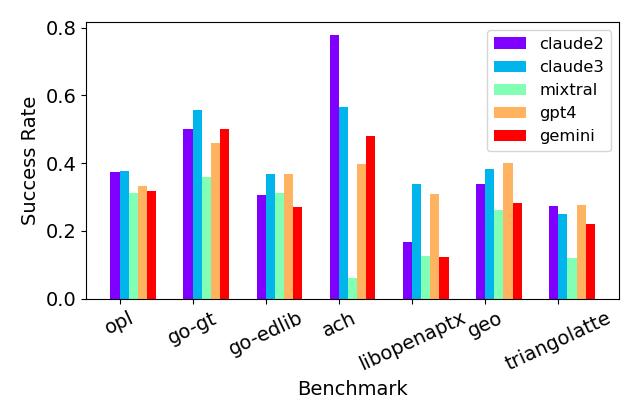
실험 결과
연구 질문
- RQ1다양한 벤치마크에서 LLM이 실제 C/Go 코드를 Rust로 얼마나 정확하게 번역할 수 있는가?
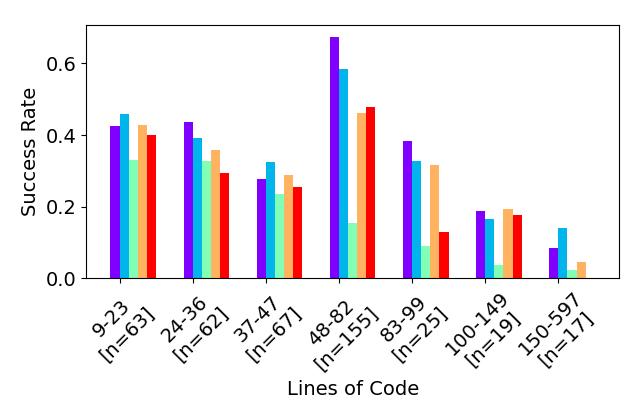
- RQ2프로그램의 크기와 복잡성이 번역 성공률에 어떤 영향을 미치는가?
- RQ3피드백 전략이 번역 성공에 도움을 주는가, 어떤 전략이 가장 효과적인가?
- RQ4LLM 번역은 품질과 관용성 측면에서 규칙 기반 번역 도구와 비교해 어떤 차이가 있는가?
- RQ5번역이 실패하는 주된 이유는 무엇이며 실패를 어떻게 완화할 수 있는가?
주요 결과
- LLMs는 전체 번역 성공률에서 Claude 2 47.7%, Claude 3 43.9%, Mixtral 21.0%, GPT-4-Turbo 36.9%, Gemini Pro 33.8%를 달성했다.
- 408개의 벤치마크에서 총 실험은 8160회였으며, 408개 벤치마크와 다섯 개의 LLM이 보고된 성공률을 산출한다.
- 가장 성능이 좋은 LLM은 벤치마크의 최대 47%를 번역했고, 일반적으로 더 작은 벤치마크가 더 큰 벤치마크보다 번역이 쉬웠다.
- 피드백 전략은 최상의 LLM에서 평균적으로 번역 성공에 절대적 포인트로 최대 8포인트의 기여를 했으며, 반례 기반 프롬프트가 때때로 단순 반복보다 성능이 낮은 경우도 있었다.
- 규칙 기반 도구인 C2Rust와 비교하여 LLM 번역은 더 간결하고 관용적이지만 항상 완전하지는 않았다.
- 제한점으로는 퍼징의 휴리스틱 특성(형식적 동등성 보장은 없음)과 일부 데이터 유형에 영향을 미치는 직렬화 제약이 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.