[논문 리뷰] Trading T gates for dirty qubits in state preparation and unitary synthesis
이 논문은 임의의 양자 상태 및 유니터리의 합성에서 T-게이트를 더러운 보조 큐비트로 교환하는 양자 알고리즘을 제안하며, 거의 최적의 T-카운트 트레이드오프를 달성한다. $Λ$ 더러운 큐비트를 활용함으로써 T-게이트 비용을 $Θ(N/\lambda + \lambda \log^2(N/\epsilon))$로 감소시키며, 이는 이전의 보조 큐비트가 없는 방법 대비 최선의 경우 제곱근 수준의 개선을 보이며, 로그 인자 수준까지 최적임을 증명한다.
Efficient synthesis of arbitrary quantum states and unitaries from a universal fault-tolerant gate-set e.g. Clifford+T is a key subroutine in quantum computation. As large quantum algorithms feature many qubits that encode coherent quantum information but remain idle for parts of the computation, these should be used if it minimizes overall gate counts, especially that of the expensive T-gates. We present a quantum algorithm for preparing any dimension-$N$ pure quantum state specified by a list of $N$ classical numbers, that realizes a trade-off between space and T-gates. Our scheme uses $\mathcal{O}(\log{(N/ε)})$ clean qubits and a tunable number of $\sim(λ\log{(\frac{\log{N}}ε)})$ dirty qubits, to reduce the T-gate cost to $\mathcal{O}(\frac{N}λ+λ\log{\frac{N}ε}\log{\frac{\log{N}}ε})$. This trade-off is optimal up to logarithmic factors, proven through an unconditional gate counting lower bound, and is, in the best case, a quadratic improvement in T-count over prior ancillary-free approaches. We prove similar statements for unitary synthesis by reduction to state preparation. Underlying our constructions is a T-efficient circuit implementation of a quantum oracle for arbitrary classical data.
연구 동기 및 목표
- 고장내성 양자 계산에서 주요 비용 요소인 T-게이트 수를 최소화하는 것.
- 청결한 보조 큐비트가 아닌, 조절 가능한 수의 더러운 보조 큐비트(혼합 또는 알려지지 않은 상태로 초기화된 큐비트)를 활용하는 것.
- T-게이트 수와 보조 큐비트 사용 간의 트레이드오프를 로그 인자 수준까지 최적임을 입증하는 것.
- 유니터리 합성에 대해 상태 준비로의 환원을 통해 접근을 확장하고, 낮은 T-카운트를 유지하는 것.
- 제안된 트레이드오프의 최적성을 확인하기 위한 무조건적 하한선을 도출하는 것.
제안 방법
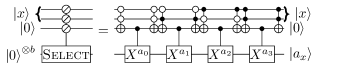
- 제어된 위상 로테이션을 통한 상태 준비의 계층적 분해를 사용하며, 각 로테이션은 푸리에 상태와 제어된 애더 회로로 구현된다.
- 목표 위상 $ a_x / 2^b $ 는 $ \epsilon $ 이내의 오차로 준비된 푸리에 상태 $ |\mathcal{F}\rangle $ 를 사용하여 근사함으로써, 직접적인 T-게이트 집약적인 위상 로테이션의 필요성을 줄인다.
- 제어된 애더 회로는 $ \mathcal{O}(b) $ T-게이트 비용을 가지며, 푸리에 상태와의 얽힘을 통해 위상 로테이션 $ e^{i2\pi x / 2^b} $ 를 적용한다.
- 총 오차는 $ \delta \leq \frac{2\pi n}{2^b} + \epsilon $ 로 유계이며, $ b = \Theta(\log(N/\delta)) $ 이므로 근사 오차를 정밀하게 제어할 수 있다.
- T-게이트 비용은 $ \mathcal{O}(N/\lambda + \lambda \log^2(N/\epsilon)) $ 로 분해되며, 여기서 $ \lambda $ 는 사용하는 더러운 큐비트의 수를 제어한다.
- 유니터리 합성에 대해 문제를 유니터리의 열을 준비하는 상태 준비로 환원함으로써 접근을 확장하며, T-카운트 트레이드오프를 유지한다.
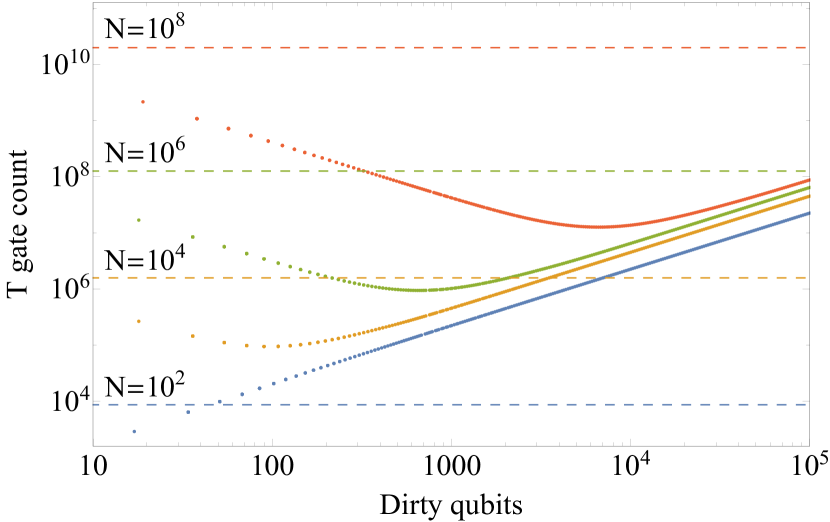
실험 결과
연구 질문
- RQ1청결한 보조 큐비트가 아닌 더러운 보조 큐비트를 사용함으로써, 임의의 양자 상태 준비에서 T-게이트 수를 줄일 수 있는가?
- RQ2상태 및 유니터리 합성에서 T-게이트 수와 보조 큐비트 수(더러운 것 포함) 간의 최적 트레이드오프는 무엇인가?
- RQ3제안된 T-카운트 트레이드오프는 로그 인자 수준까지 최적이며, 이를 무조건적 하한선을 통해 증명할 수 있는가?
- RQ4푸리에 상태와 제어된 애더 회로를 사용하는 것과 직접적인 위상 로테이션 합성 방식을 비교했을 때, T-비용은 어떻게 다른가?
- RQ5동일한 트레이드오프는 유니터리 합성으로까지 확장될 수 있으며, 그 결과 T-카운트 스케일링은 어떻게 되는가?
주요 결과
- 제안된 방법은 $ \lambda $ 개의 더러운 큐비트를 사용하여 N차원 양자 상태를 준비할 때 T-게이트 비용을 $ \mathcal{O}(N/\lambda + \lambda \log^2(N/\epsilon)) $ 으로 달성한다.
- 최선의 경우, 보조 큐비트가 없는 방법 대비 T-카운트에서 제곱근 수준의 개선을 보이며, $ \lambda = \mathcal{O}(\sqrt{N}) $ 일 때 T-카운트를 $ \mathcal{O}(N \log(N/\epsilon)) $ 에서 $ \tilde{\mathcal{O}}(\sqrt{N}) $ 로 감소시킨다.
- T-게이트 수와 보조 큐비트 사용 간의 트레이드오프는 무조건적 게이트 수 세기 하한선을 통해 로그 인자 수준까지 최적임을 입증한다.
- $ N \times N $ 행렬의 $ K $ 개의 완전히 지정된 열을 갖는 유니터리 합성에 대해 T-비용은 $ \mathcal{O}(KN/\lambda + \lambda K \log^2(N/\epsilon)) $ 로 스케일링되며, 동일한 트레이드오프를 유지한다.
- 푸리에 상태와 제어된 애더 회로의 사용은 직접적인 T-게이트 집약적인 위상 로테이션의 필요성을 줄이며, 오차 $ \delta \leq \frac{2\pi n}{2^b} + \epsilon $ 를 갖는 효율적인 근사화를 가능하게 한다.
- 조금의 $ \lambda = \mathcal{O}(\sqrt{N}) $ 에서도, $ |\textsc{T}\rangle $ 마법 상태 준비 비용을 고려하더라도, 난이도 있는 보조 큐비트 사용보다 성능이 뛰어나다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.