[논문 리뷰] Transformers as Algorithms: Generalization and Stability in In-context Learning
이 논문은 컨텍스트 내 학습(ICL)을 트랜스포머가 추론 중에 암시적 가설 함수를 구성하는 알고리즘 학습 문제로 formalize하고, i.i.d. 및 dynamical-system 프롬프트 하에서 다작업 및 전달 학습에 대한 일반화/안정성 경계를 제공합니다.
In-context learning (ICL) is a type of prompting where a transformer model operates on a sequence of (input, output) examples and performs inference on-the-fly. In this work, we formalize in-context learning as an algorithm learning problem where a transformer model implicitly constructs a hypothesis function at inference-time. We first explore the statistical aspects of this abstraction through the lens of multitask learning: We obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system. The crux of our analysis is relating the excess risk to the stability of the algorithm implemented by the transformer. We characterize when transformer/attention architecture provably obeys the stability condition and also provide empirical verification. For generalization on unseen tasks, we identify an inductive bias phenomenon in which the transfer learning risk is governed by the task complexity and the number of MTL tasks in a highly predictable manner. Finally, we provide numerical evaluations that (1) demonstrate transformers can indeed implement near-optimal algorithms on classical regression problems with i.i.d. and dynamic data, (2) provide insights on stability, and (3) verify our theoretical predictions.
연구 동기 및 목표
- 컨텍스트 내 학습(ICL)을 트랜스포머가 추론 시점에 가설 함수를 구성하는 알고리즘 학습 문제로 motivate하고 formalize한다.
- i.i.d. 및 dynamical-prompt 설정에서 다작업 학습(MTL)에서 ICL의 일반화 경계를 도출한다.
- 이 일반화 보장을 뒷받침하는 트랜스포머 아키텍처의 안정성 특성을 특성화한다.
- 전이 학습(미관측 작업) 및 교차 작업 일반화를 지배하는 인덕티브 바이어스를 조사한다.
- 근사 최적 알고리즘 구현 및 안정성 통찰을 검증하는 수치 평가를 제공한다.
제안 방법
- ICL을 내-context 시퀀스에 대한 암시적 최적화로 모델링하여 예측 함수 f^{Alg}_{S^{(m)}}를 얻는다.
- 알고리즘적 안정성을 통해 일반화 경계를 증명하고 i.i.d. 및 동적 데이터에 대해 MTL 속도 1/sqrt(nT)을 도출한다.
- 트랜스포머의 자기-주의 안정성을 확립하고 안정성을 량화성과 근사오차 분석을 통해 과도 위험과 연결한다.
- 프레임워크를 dynamical-system 프롬pts로 확장하여 지수( C_rho, rho )-안정성과 이에 따른 안정성 기반 주장을 조정한다.
- 커버링 수와 Dudley/경험적 과정 아이디어를 사용하여 안정성을 유한 샘플의 초과 위험 경계로 변환한다.
- ICL이 고전적 회귀 과제에서 거의 최적의 알고리즘을 구현할 수 있음을 보이는 실험적 검증과 전달/인덕티브 바이어스 통찰의 검증을 제공한다.
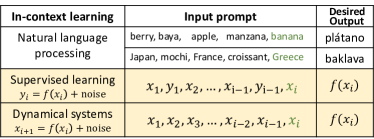
실험 결과
연구 질문
- RQ1ICL이 다작업 학습 설정에서 작업 간 일반화를 보장하는 조건은 무엇인가?
- RQ2트랜스포머 안정성이 i.i.d. 프롬프트와 dynamical-system 프롬프트에서 ICL의 일반화 경계에 어떤 영향을 미치는가?
- RQ3 unseen tasks에서 ICL의 전달 학습 행동은 어떠하며 작업 복잡성과 원천 작업 수가 이를 어떻게 좌우하는가?
- RQ4ICL이 회귀 문제에서 거의 최적의 알고리즘(예: ridge 회귀)을 구현한다고 해석될 수 있으며 프롬프트 길이가 안정성에 어떤 영향을 미치는가?
- RQ5원천 작업 구조와 대상 작업 간 거리의 정렬이 선형 및 동적 설정에서 전달 위험에 어떤 영향을 미치는가?
주요 결과
- ICL 일반화는 i.i.d. 및 동적 프롬 prompts 모두에 대해 다작업 설정에서 1/sqrt(nT) 속도를 달성한다.
- 자기 주의 안정성을 한정할 수 있으며 특정 노름 제약 하에서 트랜스포머 기반의 ICL은 일반화 보장을 제공하는 안정성 조건을 준수한다.
- 경험적으로 ICL 예측은 프롬프트가 길어질수록 더 안정적이 되며 노이즈가 있는 데이터로의 학습은 안정성을 촉진한다.
- 전이 학습에는 귀납적 바이어스가 존재한다: 전달 위험은 작업 복잡도와 MT 작업의 수에 의해 지배되며 모델 크기에 거의 의존하지 않는다.
- 선형 회귀와 유사한 작업에서 전달 위험과 MT L의 위험 곡선이 일치하며, 전달 위험은 실험에서 대략 d^2/T로 확산한다.
- 동적 시스템에 걸쳐 ICL은 충분한 기억과 안정된 역학이 주어질 때 자기회귀 LS 추정기보다 우수할 수 있다.
![Figure 3: The benefit of learning across the full task sequence: Right side: Standard ERM where each task trains with all $n=40$ prompts. Left side: ERM focuses on different parts of the trajectory by fitting $n/4=10$ prompts per task over $i\in[1,10]$ to $[31,40]$ (highlighted as the orange ranges)](https://ar5iv.labs.arxiv.org/html/2301.07067/assets/x6.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.